全球頂尖CV團隊在關注什麼?這一次,機器之心知識站走近蘇黎世聯邦理工學院的計算機視覺實驗室(ETHZ CVL),研究組成員將連續4天帶來4場技術直播,趕緊點選「閱讀原文」關注吧!蘇黎世聯
2021-06-03 11:49:31

全球頂尖CV團隊在關注什麼?這一次,機器之心知識站走近蘇黎世聯邦理工學院的計算機視覺實驗室(ETHZ CVL),研究組成員將連續4天帶來4場技術直播,趕緊點選「閱讀原文」關注吧!
蘇黎世聯邦理工學院計算機視覺實驗室由計算機視覺領域著名學者Luc Van Gool, 以及醫療影像教授Ender Konukoglu和計算機視覺及系統教授Fisher Yu的研究組組成,是歐洲乃至世界最頂尖的CV/ML研究機構之一。ETHZ CVL關注訊號從採集、分析到處理的全流程,旨在開發通用的概念和方法,研究領域包括視覺場景理解、醫學影象分析、機器人、具身智慧、高效神經網路與計算等。
CVL對標國際研究前沿,以實際應用驅動研究,並將與工業界的密切合作視為重要優勢。研究成果發表於計算機視覺(CVPR、 ECCV、ICCV)、機器學習(NeurIPS、ICML、ICLR)、人工智慧(AAAI)、機器人(ICRA)、醫學影象(MICCAI)等領域的頂級會議。其中,Luc Van Gool教授提出的SURF運算元是計算機視覺領域的經典演算法,谷歌學術引用超過20000次。CVL組織的「PASCAL VOC挑戰賽」對學術界和工業界產生深遠影響。

CVL畢業成員廣泛活躍於工業界與學術界。在工業界,實驗室成員分佈在Google、Facebook、Apple等知名企業,也有部分成員成功創業。在學術界,實驗室成員執教於馬普所、波恩大學、新加坡國立大學、悉尼大學、南京大學等國內外高校。
CVL由影象通訊與理解(Image Communication and Understanding,ICU),生物醫學影象計算(Biomedical Image Computing,BMIC),視覺智慧和系統(Visual Intelligence and Systems,VIS),計算機輔助醫學應用(Computer-assisted Applications in Medicine,CAiM)共4個研究小組構成。其中:
影象通訊與理解(ICU)小組由Luc Van Gool教授領導,Dengxin Dai、Radu Timofte、Martin Danelljan等三位講師,分別在自動駕駛、影象處理、目標跟蹤等領域展開研究。此外,ICU小組的成員對高效網路設計與計算、大規模3D場景理解、影象和視訊解析以及3D重構等方向有著廣泛的興趣。相關主頁:https://icu.ee.ethz.ch/生物醫學影象計算(BMIC)小組由Ender Konukoglu教授領導。面向生物醫學領域的前沿挑戰,研發理論合理且實際可行的前沿技術解決方案。相關主頁:https://bmic.ee.ethz.ch/視覺智慧和系統(VIS)小組由Fisher Yu教授領導。藉助影象處理、機器學習、統計學、深度學習和控制理論,研究可以在實際環境中執行復雜任務的感知機器人系統。相關主頁:https://cv.ethz.ch/計算機輔助醫學應用(CAiM)小組由Orun Gksel教授領導。CAiM關注醫療資料分析和資訊提取,研究基礎涉及多個交叉學科,包括工程學、電腦科學和醫學。小組成員具備跨學科背景,力求研發前沿的醫學成像和影象分析技術,並應用於臨床實踐。相關主頁:https://caim.ee.ethz.ch/group.html6月7日至10日,機器之心特別邀請到ETHZ CVL的4位研究員分享團隊最新進展,具體安排如下:
直播地址:https://jmq.h5.xeknow.com/s/30jrSR(點選閱讀原文直達)
6月7日 20:00-21:00
分享主題:New Opportunities in Monocular 2D and 3D Object Tracking
分享摘要:Object tracking is foundational for video analysis and a key component for perceptionin autonomous systems, such as self-driving cars and drones. Due to its importance, tracking has been studied extensively in the literature. However, the availability of large-scale driving video data brings new research opportunities in the field.
In this talk, I will discuss our recent findings in multiple object tracking (MOT), after briefly reviewing the current works and trends on the topic. Then, I will introduce our new tracking method based on Quasi-Dense Similarity Learning. Our method isconceptually more straight forward yet more effective than the previous works. It boosts almost ten percent of accuracy on the large-scale BDD100K and WaymoMOT datasets.
I will also talk about how to use the 2D tracking method for monocular 3D object tracking. Our quasi-dense 3D tracking pipeline achieves impressive improvements on the nuScenes 3D tracking benchmark with five times tracking accuracy of the popular tracking methods. Our works point to some interesting directions in MOT research and technology in the era of ubiquitous videos.
分享嘉賓:Fisher Yu is an Assistant Professor at ETH Zürich in Switzerland. He obtained his Ph.D. degree from Princeton University and became a postdoctoral researcher at UC Berkeley. He is now leading the Visual Intelligence and Systems (VIS) group at ETH Zürich. Hisgoal is to build perceptual systems capable of performing complex tasks incomplex environments. His research is at the junction of machine learning, computer vision and robotics.He currently works onclosing the loop between vision and action.His works on imagerepresentation learning and large-scale datasets, especially dilated convolutions and the BDD100K dataset, have become essential parts of computer vision research. More info is on his website: https://www.yf.io
6月8日 20:00-21:00
分享主題:Scaling perception algorithms to new domains and tasks
分享摘要:In this talk, I will mainly present our recent methods for semi-supervised and domain-adaptive semantic image segmentation by using self-supervised depth estimation. In particular, we propose three key contributions:
(1) We transfer knowledge from features learned duringself-supervised depth estimation to semantic segmentation;
(2) We propose astrong data augmentation method DepthMix by blending images and labels while respecting the geometry of the scene;
(3) We utilize the depth feature diversity as well as the level of difficulty of learning depth to select the most useful samples to collect human labels in the semi-supervised setting and to generate pseudo-labels in the domain adaptation setting.
Our methods have achieved state-of-the-art results for semi-supervised and domain-adaptive semantic image segmentation. The codes are also made available. During the talk, I will also present our ACDC dataset. ACDC is a new large-scale driving dataset for training and testing semantic image segmentation algorithms on adverse visual conditions, such as fog, nighttime, rain, and snow. The datasetand associated benchmarks are made publicly available.
分享嘉賓:Dengxin Dai is a Senior Scientist and Lecturer working with the Computer Vision Lab at ETH Zurich. He leads the research group TRACE-Zurichworking on Autonomous Driving in cooperation with Toyota. In 2016, he obtained his PhD in Computer Vision at ETH Zurich. He is the organizer of the workshop series (CVPR'19-21) "Vision for All Seasons: Bad Weather and Nighttime",the ICCV'19 workshop "Autonomous Driving", and the ICCV'21 workshop "DeepMTL:Multi-Task Learning in Computer Vision". He was a Guest Editor for the IJCV special issue "Vision for All Seasons", an Area Chair for WACV2020, and an Area Chair for CVPR 2021. His research interests lie in Autonomous Driving, Robust Perception Algorithms, Lifelong Learning, Multi-task Learning, and Multimodal Learning.
6月9日 19:00-20:00
分享主題:Deep Visual Perception in a Structured World
分享摘要:The world we live inis highly structured. Things that are semantically related are typically presented in a similar way: both trucks and buses have wheels and cabins, for example. Things also undergo continuous variations over time; in a video clip, content among frames are highly correlated. Our humans also interact with the environment constantly and communicate with each other frequently. Overall, there exist rich structures between human and environment and over both spaceand time.
Therefore, it is highly needed to understand this visual world from a structured view. In this talk, I will advocate the value of structured information in intelligent visual perception. As examples, I will present a line of my recent work on semantic segmentation, human semantic parsing and fake video detection.
分享嘉賓:Dr. Wenguan Wang is currently a postdoctoral scholar in ETH Zurich, working with Prof. Luc VanGool. From 2018-2019, he was a Senior Scientist in Inception Institute of Artificial Intelligence, UAE. From 2016-2018, he was a Research Assistant (VisitingPh.D.) in The University of California, Los Angeles, under the supervision of Prof. Song-Chun Zhu. His current research interests are in the areas of Image/Video Segmentation, Human-Centric Visual Understanding, Gaze BehaviorAnalysis, Embodied AI, and 3D Object Detection. He has published over 50 journal and conference papers such as TPAMI, CVPR, ICCV, ECCV, AAAI, and Siggraph Asia.
6月10日 19:00-20:00
分享主題:Tiny AI for computer vision
分享摘要:In recent year, deep neural networks has boosted the performances of computer vision algorithms for the task of visual recognition, object detection, semantic segmentation etc. Yet, it often comes with the increase of the model complexity in terms of number of parameters and computational cost. This increases the energy consumption, latency, andtransmission of pre-trained models and becomes a huge challenge for the deployment of deep neural networks on edge devices. Thus, network compression and model acceleration becomes a feasible solution to this problem.
In this talk, we will report the recent development and thought of model acceleration in the Computer Vision Lab. We introduce our work on model acceleration and network architecture optimization from the perspective of learning filter basis, group sparsity, differentiable network pruning, and the advantage of heterogenous network architectures.
分享嘉賓:Yawei Li is currently a Ph.D student at Computer Vision Lab supervised by Prof. Luc Van Gool. His research direction is efficient computation in computer vision. He is interested in efficient neural network design and image restoration. For efficient computation, he has been exploring in the direction of neural network compression and model acceleration, graph neural networks, and vision transformers. He has published papers in top-tier computer vision conferences including CVPR, ECCV, and ICCV.
歡迎加入直播交流群
掃碼入群:針對本次分享主題,歡迎大家進群一起交流。
如群已超出人數限制,請新增其他小助手:syncedai2、syncedai3、syncedai4 或 syncedai5,備註「cv lab」即可加入。
相關文章

全球頂尖CV團隊在關注什麼?這一次,機器之心知識站走近蘇黎世聯邦理工學院的計算機視覺實驗室(ETHZ CVL),研究組成員將連續4天帶來4場技術直播,趕緊點選「閱讀原文」關注吧!蘇黎世聯
2021-06-03 11:49:31

看完鴻蒙系統的釋出會,相信大家被華為裝置之間的聯動給震驚到了,見識到什麼是真正的萬物互聯,HarmonyOS 2不只是手機/平板作業系統,它是一個囊括一整套物聯網裝置在內的生態系統
2021-06-03 11:48:46
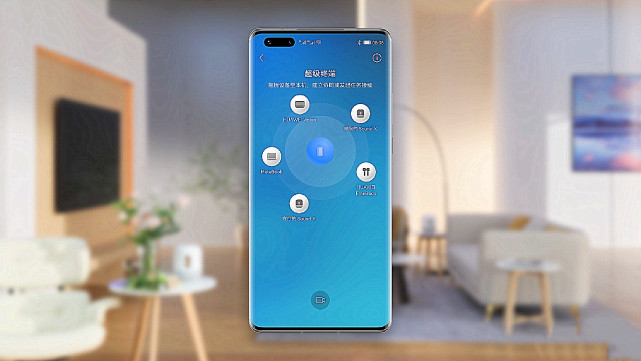
自從鴻蒙系統正式推送之後,筆者一直都帶著好奇心在體驗著HarmonyOS 2帶來的變化,生怕錯過驚喜,也擔心繫統本身會出現不足。因為鴻蒙系統就像是年輕人一樣,才剛剛出爐,需要時間去
2021-06-03 11:48:24

上月底,在華為舉辦的全場景智慧生活釋出會上,華為 MateBook 16「全能本」正式和消費者見面,這是華為 MateBook 系列的新成員,它面向對效能有較高要求的專業領域使用者、重度辦公
2021-06-03 11:48:13
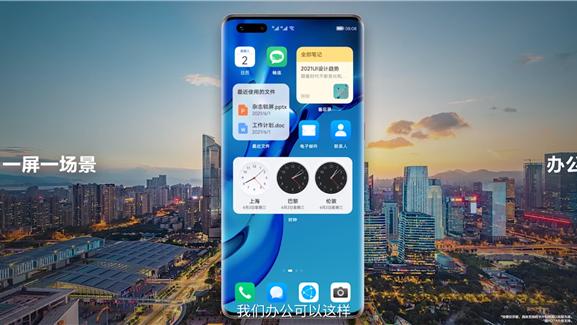
很多華為使用者從EMUI升級鴻蒙之後使用者發現,手機流暢度有了肉眼可見的流暢度體驗。6月2日,華為鴻蒙釋出會上,華為消費者業務軟體部總裁王成錄稱,新發布的Harmony OS系統無懼老
2021-06-03 11:48:05

成功領導數字化轉型工作的資訊長通常有一些重要的技能,但現在最重要的技能是什麼?資訊長決定組織在數字化轉型方面的成敗。商業和技術諮詢機構West Monroe公司總經理Greg Lay
2021-06-03 11:30:39