大家都知道,現有的序列推薦演算法大多采用淺層的神經網路結構。
而今天,AI 科技評論將為大家介紹一篇由中科院先進所、騰訊、華南理工近日合作發表在資訊檢索領域頂會 SIGIR 2021上的一篇論文,這篇論文發現通過對殘差塊結構進行微小的修改,序列推薦模型能夠使用更深的網路結構以進一步提升精準度,也就是,推薦模型也能夠像計算機視覺領域的模型那樣擁有100層以上的深度並獲得最優效能。
在此基礎上,論文提出一個高效且通用的框架 StackRec 來加速深度序列推薦模型的訓練,並應用到多種實際的推薦場景中。
論文地址:https://arxiv.org/pdf/2012.07598.pdf
程式碼+資料地址:https://github.com/wangjiachun0426/StackRec
由於推薦系統中的資料稀疏性問題以及深度學習中的梯度消失、梯度爆炸問題,現有的序列推薦演算法往往採用淺層的神經網路結構(一般不超過10層,例如GRU4Rec通常1層最優,SASRec通常2個殘差塊最優)。
而本文這篇StackRec論文發現,通過對序列推薦模型的殘差塊進行微小的修改,在殘差塊的殘差對映上新增一個權重係數,極深的網路也能得到有效的穩定的訓練,從而緩解過擬合問題。
具體來說,如圖1所示,我們可以對殘差塊中的殘差對映新增一個係數,來衡量殘差對映的權重,訊號傳播公式為:
其中,被初始化為0,使得殘差塊在初始化階段表示為一個單位函數,從而滿足動態等距理論 [1]。論文作者在NextItNet [2]上進行實驗,發現當訓練資料充足時,隨著網路深度的增加,推薦模型的表現越來越好,最多可使用128層的深度並獲得最優效能,如圖2(b)所示。
加深序列推薦模型帶來了明顯的精準度提升,但訓練時間也會受到影響。
一方面,深度神經網路的訓練本身就需要大量的時間來進行計算和迭代優化;
另一方面,在現實應用中,推薦系統承載的使用者數量和物品數量往往可達到成百上千萬,互動記錄數量可達到數百億,這樣大規模訓練資料的使用也在一定程度上增加了特別深模型的訓練時間。如何在不損失精準度的條件下提升深度序列推薦模型的訓練效率是一個極具學術研究意義和商業應用價值的問題,StackRec論文對此進行研究和探討。
論文對現有的深度序列推薦演算法進行觀察,總結了一些特點和規律:
1、現有的深度序列推薦模型呈現為「三明治」結構,包含三個模組,底層是用於表示互動序列的嵌入表示層,頂層是用於生成預測結果概率分佈的Softmax層,中間是多個隱含層(通常為殘差網路)。網路的深度可以通過控制殘差塊的數量來改變。
2、最近的研究工作CpRec [3]展示了深度序列推薦模型的中間層參數可以通過多種方式跨層共享。例如,CpRec頂部的層/塊使用與底部完全相同的參數,從而減少參數的儲存空間,實現模型壓縮。
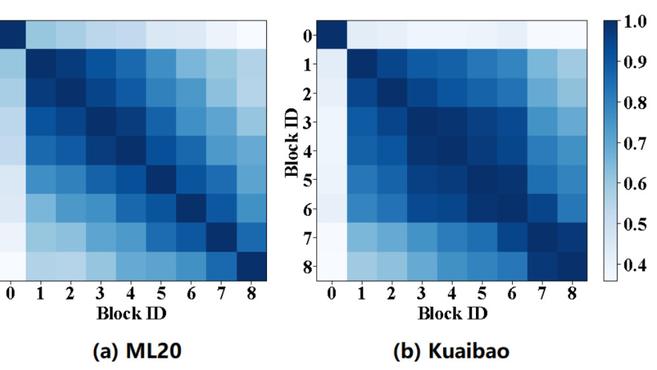
3、如圖3所示,在深度序列推薦模型的中間層中,每兩個相鄰殘差塊輸出的特徵圖非常相似,這潛在地表明這些塊在某種程度上具有相似的功能。
這些觀察表明,中間層學習到的知識可以通過某種方式進行共享,因為它們存在高度的相似性。
這啟發了論文作者思考,能否先訓練一個淺層推薦模型,然後複製其參數並堆疊出一個更深的模型。通過新增新的層,或許能夠擴展模型容量,提高推薦精準度。
通過為新加的層賦予較好的初始化參數,或許能夠加快模型收斂,減少訓練時間,事實上這種現象在CV和NLP等模型上也存在。
StackRec演算法的非常簡單,就是採用對一個淺層序列推薦模型進行多次層堆疊(Layer Stacking),從而得到一個深層序列推薦模型。
4)將深層模型作為一個新的淺層模型,重複1)至3)直到滿足業務需求。
對於步驟2),論文提出兩種按塊進行的堆疊方式:相鄰塊堆疊(Adjacent-block Stacking)和交叉塊堆疊(Cross-block Stacking)。假設我們有一個訓練好的擁有塊的模型(也就是淺層模型),那麼我們可以通過複製這個淺層模型的參數來構造一個擁有塊的深層模型。我們按照以下方式進行相鄰塊堆疊:對於,深層模型的第個塊和第個塊與淺層模型的第個塊擁有相同的參數。同理,我們按照以下方式進行交叉塊堆疊:對於,深層模型的個塊和第個塊與淺層模型的第個塊擁有相同的參數。圖4展示了相鄰塊堆疊和交叉塊堆疊這兩種堆疊方式,假設為2。這兩種堆疊方式是可以互相替代的。它們剛好對應了CpRec中兩種按塊進行的參數共享機制。
通過這兩種堆疊方式,步驟1)中訓練好的淺層模型參數可以遷移到深層模型中,這對於深層模型來說是一種很好的熱啟動方式。通過步驟3)的微調,深層模型能夠快速收斂,達到其最優效能。這種方式比起標準的從頭開始訓練方式,能夠獲得一定程度的訓練加速效果。而且StackRec演算法可以迴圈執行上述堆疊過程,快速獲得一個很深的模型。
StackRec演算法是一個通用的框架,可以使用NextItNet、GRec、SASRec、SSEPT等深度序列推薦模型作為基準模型,提升它們的訓練效率。論文作者使用NextItNet作為案例來闡述StackRec演算法的使用,但在實驗中也報告了StackRec演算法在其它模型上的效能表現,以證明StackRec演算法的通用性。
論文作者將StackRec演算法應用到持續學習、從頭開始訓練、遷移學習這三種常見的推薦場景中。
在真實的生產環境中,推薦系統會經歷兩個階段:資料匱乏階段和資料充沛階段。
在資料匱乏階段,推薦系統處於使用初期,缺乏訓練資料,無論是使用者和物品數量還是互動行為數量都很有限。在這個冷啟動階段,由於訓練資料過於稀疏,使用淺層的推薦模型就足以獲得較好的效能。若使用深層的推薦模型,可能會遇到過擬合問題,而且還會導致無意義的計算成本。
推薦系統部署上線後,隨著新資料的產生,訓練資料逐漸累積,推薦系統進入資料充沛階段,原有的淺層模型表達能力不足,我們需要重新構建並訓練一個更深的網路以獲得容量更大的模型,從而實現更好的推薦精準度。
在這樣的場景中,StackRec演算法就能起到很大的作用,因為它能夠從淺層模型中遷移有用的知識到目標深層模型中,加速深層模型的訓練,這使得我們不需要從頭開始訓練一個模型。
更具前瞻性的是,真實的推薦系統會持續產生新的訓練樣本,最終能夠變成終身學習(Lifelong Learning)系統。StackRec演算法能夠輕鬆地訓練一個層數更多、容量更大的推薦模型,即時應用到終身學習系統中。
我們將這種推薦場景命名為持續學習(Continual Learning,CL)場景。
StackRec演算法在CL場景中的使用如圖5所示。假設是訓練樣本,是在系統上收集訓練樣本的時間刻度。在初始時刻,我們用樣本訓練一個隨機初始化的有個塊的淺層NextItNet,並將得到的模型部署上線。推薦系統處於冷啟動狀態,模型開始提供服務。當系統積累了更多的訓練資料(包含),模型由於網路較淺,無法實現最優的效能。此時我們希望使用一個層數更多、表達能力更強的模型,於是,我們執行StackRec的堆疊操作,將NextItNet的層數翻倍為個塊。
由於網路的連線突然發生變化,深層網路需要在樣本上進行微調直到收斂,即可得到模型。真實的推薦系統每天都會產生大量新的資料,上述堆疊和微調操作可以重複執行下去。演算法1展示了這樣的逐步堆疊過程。事實上,按照這樣的方式,StackRec可以被視作終身學習模型,輕鬆快捷地獲得一個深度模型並投入使用。
在具體實踐中,不同於持續學習場景,有時候我們需要從頭開始訓練一個新的深度序列推薦模型,而不利用舊模型的知識。在這種從頭開始訓練(Training from Scratch,TS)場景中,StackRec演算法同樣能夠起到一定程度的訓練加速作用。當我們需要一個深層模型時,我們可以先訓練一個淺層模型若干步,接著使用StackRec演算法將它複製並堆疊成深層模型,然後進一步訓練它直到收斂。
與CL場景相比,StackRec演算法在TS場景中的使用有兩個不同點:
如果我們知道訓練一個模型直到收斂的總步數,那麼我們只需要訓練淺層模型大約其步即可。在TS場景中,StackRec演算法能夠幫助我們減少模型訓練時間,是因為訓練淺層模型所需時間更少,速度更快,並且堆疊方式中的知識遷移也帶來一定的訓練加速作用。
值得注意的是,淺層模型和深層模型使用相同的資料進行訓練,如果將淺層模型訓練直到收斂,那麼深層模型會快速過擬合,無法找到更優的參數空間。演算法 2闡述了StackRec演算法在從頭開始訓練場景中的使用。
序列推薦模型可以通過無監督/自監督方式來訓練,因此模型的輸出可以被視作個性化的使用者表示,並遷移到下游任務中,解決下游任務的使用者冷啟動問題。PeterRec是第一個展示序列推薦模型具有遷移學習能力的工作。
受此啟發,StackRec論文試圖探索StackRec演算法能否作為通用的預訓練模型,有效地應用到下游任務中。
因此,在遷移學習(Transfer Learning,TF)場景中,我們可以使用StackRec演算法訓練一個深度序列推薦模型作為預訓練模型,然後應用到下游任務中。根據實際業務需要,我們可以自由地選擇使用CL場景中的StackRec演算法過程,或是TS場景中的StackRec演算法過程。論文作者按照CL場景的演算法過程來展示StackRec演算法在TF場景中的表現。
事實證明,在TF場景中,StackRec演算法同樣能夠用於加速預訓練模型的訓練,並且成功遷移到下游任務中,不損失預訓練模型和目標模型的精準度。
論文作者在ML20、Kuaibao和ColdRec這三個真實世界的資料集上進行大量實驗,使用MRR@N、HR@N和NDCG@N這三個評估指標來評估模型的推薦精準度,並報告了相對於基準模型的訓練加速比Speedup以分析訓練效率。
其中StackA-Next-k:代表使用相鄰塊堆疊方式的StackRec;StackC-Next-k:代表使用交叉塊堆疊方式的StackRec,字尾-k表示所含塊數。
(1)StackRec演算法在持續學習場景中的表現
這個實驗模擬了持續學習場景中資料不斷增加的過程。由表1可見,首先,在ML20和Kuaibao這兩個資料集上,NextItNet-8 () 比NextItNet-4 () 表現得更好,這表明當序列推薦模型擁有更多訓練資料時,使用一個更深的網路結構能獲得更高的精準度。其它設定(和)下的實驗結果也展示了相同的情況。
然而,從頭開始訓練一個更深的模型需要花費更多的計算成本和訓練時間。而StackRec模型,包括StackC-Next-8和StackA-Next-8,實現了與NextItNet-8 () 同等甚至更好的推薦精準度,同時獲得2.5倍的訓練加速效果。
這表明,使用好的參數初始化方式來熱啟動深度序列推薦模型,能使模型在微調過程中快速收斂,並保持同等的精準度。圖6展示了相應的收斂過程,很明顯,在相同的層數下,StackRec比NextItNet收斂更快,推薦精準度也略高。
(2)StackRec演算法在從頭開始訓練場景中的表現
為了獲得一個32塊的StackRec,首先可以訓練一個8塊的NextItNet(訓練時間用黃色線表示),然後使用相鄰塊堆疊將它加深為16塊,並執行微調(訓練時間用橙色線表示);而後,進一步將它加深為32塊,並訓練直到收斂(訓練時間用紅色線表示)。
由圖7可見,在ML20資料集上,StackRec總的訓練時間縮短了40%(280分鐘相對於490分鐘),在Kuaibao資料集上則縮短了35%(480分鐘相對於740分鐘)。
2、從淺層模型遷移參數來熱啟動深層模型有助於訓練收斂。
(3)StackRec演算法在遷移學習場景中的表現
為了檢驗StackRec演算法的遷移學習能力,我們在ColdRec的源域資料集上使用StackRec演算法預訓練一個模型,然後簡單地在最後一個隱含層後面增加一個新的Softmax層。原有的層使用預訓練的參數,新的層使用隨機初始化參數,隨後,在目標域資料集上微調所有參數。
從表2可以看出,StackRec相比於NextItNet-16獲得3倍的訓練加速,並且它的精準度在預訓練和微調後沒有任何損失。在實際應用中,預訓練模型通常需要使用一個大規模資料集進行長時間的訓練,對高效能硬體資源和時間成本的需求阻礙了它的應用落地,預訓練模型的訓練效率成為遷移學習的關鍵問題。StackRec演算法能在這樣的遷移學習場景中起到很大作用。
(4)另外,StackRec論文還進行了大量消融分析和通用性證明實驗,包括不同堆疊方式的比較、不同堆疊塊數的比較、不同基準模型的例項化等實驗,以探究StackRec演算法的合理性、有效性、靈活性和通用性。
StackRec論文探究了深度序列推薦模型中網路深度的影響,發現了模型隱含層之間具有很高的相似性,然後設計了相鄰塊堆疊和交叉塊堆疊兩種堆疊方式。
並將演算法例項化到NexItNet等多個序列推薦模型上,應用到持續學習、從頭開始訓練、遷移學習三個推薦場景中,在不損失推薦精準度的條件下,實現 2倍以上的訓練加速效果。
值得注意的是,StackRec僅僅適用於training階段,對於線上推理階段深度序列推薦模型加速問題,可以參考同時期工作SkipRec [4]發表在AAAI2021。
[1] Dynamical isometry and a mean field theory of cnns: How to Train 10,000- Layer Vanilla Convolutional Neural Networks. Xiao et al, ICML2018
[2] A Simple Convolutional Generative Network for Next Item Recommendation. Yuan et al. WSDM2019
[3] A Generic Network Compression Framework for Sequential Recommender Systems. Sun et al. SIGIR2020
[4] SkipRec: A User-Adaptive Layer Selection Framework for Very Deep Sequential Recommender Models. Chen et al. AAAI2021