機器之心分析師網路作者:Jiying編輯:Joni這篇文章圍繞機器學習(ML)和功能性磁共振成像(fMRI)的應用問題,以三篇最新的研究型論文為基礎,探討基於統計學中 ML 的 fMRI 分析方法。本文
2021-06-29 19:31:26
機器之心分析師網路
作者:Jiying
編輯:Joni
這篇文章圍繞機器學習(ML)和功能性磁共振成像(fMRI)的應用問題,以三篇最新的研究型論文為基礎,探討基於統計學中 ML 的 fMRI 分析方法。
本文主要討論的是機器學習(ML)和功能性磁共振成像(fMRI)的應用問題。fMRI 主要用來檢測人在進行各種腦神經活動時(包括運動、語言、記憶、認知、情感、聽覺、視覺和觸覺等)腦部皮層的磁力共振訊號變化,配合在人腦皮層中樞功能區定位,就可研究人腦思維進行的軌跡,揭示人腦奧祕。其基本原理是利用 MRI 來測量神經元活動所引發之血液動力的改變。所以,利用 ML 連線 fMRI 影象,以瞭解人腦正在觀察和思考的物件是理論上可行的。以本文討論的問題為例,神經科學家現在可以通過像資料科學家一樣運行計算模型來預測並準確地將神經功能與認知行為聯絡起來。不過,這些技術與人工智慧模型有著相同的偏見(biases)和侷限性(limitations),需要嚴格的科學方法加以應用[1]。
雖然神經科學家在 20 世紀初就注意到了大腦血流有明顯的變化,但是卻一直沒有找到合適的方法來測量這些變化。20 世紀 80 年代出現了一種有效的方法:正電子發射體層攝影(術) (position emissiom tomography,PET)。有了這種技術,研究人員能夠通過放射性追蹤和檢測光子(phonto)發射來觀察神經元活動的變化。由於這些光子在神經元消耗最多葡萄糖的地方降解得最多,因此它們可以顯示出神經元的活動。然而,早期使用這種方法時面臨著一個問題:每個人的大腦都有不同的尺寸和結構,差異和變化非常大。此外,PET 掃描的空間和時間影象解析度非常低。它們檢測的區域至少有一毫米寬,需要 10 秒鐘才能收集到足夠的資料來形成影象。所以該技術的早期應用範圍相當有限。
磁共振成像(magnetic resonance imaging,MRI)可以在原子核振動的基礎上構建更準確的大腦影象。由於 MRI 掃描器以不同的速度向許多位置傳送訊號,它可以通過解碼不同的頻段來成像。不過在 MRI 成像時需要使用一種造影劑,這種造影劑可能對受試者的健康有危險。幸運的是,在注意到核磁共振訊號對大腦中血液迴圈的含氧量敏感後,許多研究小組在 90 年代提出了檢測大腦活動的功能性磁共振成像(fMRI)的概念。
神經科學家的傳統方法是通過發現最活躍的訊號區域來推斷統計學上的選擇性區域。現代研究目標則是推斷出選擇性區域的共性活動模式。研究人員發現,神經網路並不會對一個物體有特別的反應,但從統計學角度上分析,卻分佈著對許多物體的不同比例的反應。這是一種統計學上的相關關係。此外,現代神經科學家的另一個研究目標是通過訓練一個計算模型,從更大的資料集中預測人類感知的物體。這種基於機器和統計學習的方法旨在根據神經模型的交叉驗證來預測人們的思維。
但是,儘管取得了一些成功,但是對這些基於統計學的科學推論我們仍需要謹慎分析和討論。fMRI 分析測量了數十萬個稱為體素(voxel)的小方塊。為了從大腦的某個部分找到有意義的反應,而不是由於隨機的變化,必須進行統計測試。因此,需要衡量真假陽性的風險,如研究人員在他們的一個實驗中發現了一個重要的反應,但當這些實驗被多次重複時,這一反應訊號在一般的資料中卻變得不明顯。因此,人們必須能夠將實驗重複幾百次甚至幾千次,才能確定結果。使用 fMRI 統計的另一個問題是所謂的 "非獨立性(non independence)" 統計錯誤。研究人員傾向於選擇最適合他們研究的資料和結果。例如,在所有的統計測試中,他們可能會關注那些體素顯示出最強關聯性的實驗,而這相對來說可以使他們的實驗結果好得多。
我們在這篇文章中,圍繞上面的主題,以三篇最新的研究型論文為基礎,探討基於統計學中 ML 的 fMRI 分析方法。
1、通過深度學習對人腦的任務狀態進行解碼和對映

本文是來自中科大和北大的研究人員 2020 年發表在 Human brain mapping 中的一篇文章[2]。本文重點討論基於支援向量機(SVM)的多變數模式分析(multivariate pattern analysis,MVPA)在基於人腦功能磁共振成像(fMRI)的特定任務狀態解碼中的應用。本文作者提出了一個深度神經網路(DNN),用於從大腦的 fMRI 訊號中直接解碼多個大腦任務狀態,無需人工進行特徵提取。
關於根據腦功能成像資料解碼和識別人腦的功能的問題,SVM-MVPA 是一種應用最為廣泛的方法。SVM-MVPA 是一種監督學習技術,可同時考慮多個變數的資訊。不過,SVM-MVPA 在高維資料中的表現欠佳,往往依賴於專家選擇 / 提取特徵的結果。因此,作者在本研究中探索了一種開放式的大腦解碼器,它使用的是人類的全腦神經成像資料。相對應的,具有非線性啟用函數的 DNN 的分層結構使其能夠學習比傳統機器學習方法更復雜的輸出函數,並且可以進行端到端的訓練。由此,本文提出了一個 DNN 分類器,通過讀取與任務相關的 4D fMRI 訊號,有效解碼並對映個人正在進行的大腦任務狀態。
1.1 方法介紹
1.1.1 資料介紹
本研究使用了 HCP S1200 最小預處理的 3T 資料版本,其中包含了大量年輕健康成年人的成像和行為資料[3]。作者使用了 1034 名 HCP 受試者的資料,他們共執行了七項任務:情緒、賭博、語言、運動、關係、社交和工作記憶(working memory,WM)。具體用於實驗分析的是 HCP volume-based 的預處理 fMRI 資料,這些資料已經被歸一到 Montreal Neurological Institute's(MNI) 152 空間。七項任務中的大部分是由控制條件(例如,WM 任務中的 0 - 回位和情感任務中的形狀刺激)和任務條件(例如,WM 任務中的 2 - 回位和情感任務中的恐懼刺激)組成的。在每個任務中,只有一個條件被選為下一個步驟。對於只有兩個條件的任務(情感、語言、賭博、社交和關係任務),與任務關聯度大的條件優先於其他條件。WM 和運動任務包含一個以上的任務條件,作者則是從列表中隨機選擇一個(WM 的 2 個背部身體和運動的右手)(表 1)。
對於每個任務,輸入樣本是一個連續的 BOLD(Blood-oxygen-level-dependent imaging)序列,涵蓋了整個區塊和區塊後的 8s 內的樣本,包括血流動力學反應函數(hemodynamic response function,HRF)的後訊號。此外,將每個 BOLD volume 從 91×109×91 剪裁到 75×93×81,以排除掉不屬於大腦的區域。因此,輸入資料的大小從 27×75×93×81 到 50×75×93×81(time × x × y × z,TR=0.72s)。在所有的任務和受試者中,總共獲得了 34,938 個 fMRI 4D 資料項。

表 1. 每個任務所選擇的 BOLD 時間序列的細節
1.1.2 模型介紹
圖 1 為本文提出的網路模型的完整流程圖。該網路由五個卷積層和兩個全連線層組成。其中,27×75×93×81 的資料是通過節 1.1.1 的預處理和資料增強步驟產生的。第一層使用了 1×1×1 的卷積濾波器,即卷積神經網路(CNN)的結構中最普遍的設定,這些濾波器可以在不改變卷積層的感受野的情況下增加非線性。這些濾波器可以為 fMRI volume 中的每個體素生成時間描述符,而且它們的權重可以在訓練中由 DNN 學習得到。因此,採用這種類型的過濾器後,資料的時間維度從 27 降到了 3。在這之後,堆疊一個卷積層和四個殘差塊以提取高層次(high-level)特徵。本文使用的殘差塊是通過用一個三維卷積層替換原始殘差塊中的二維卷積層而得到的。四個殘差塊的輸出通道分別為 2 的倍數 -----32、64、64 和 128。這些層的設計方式是:它們的尺寸可以迅速減少以平衡 GPU 記憶體的消耗。為了便於網路視覺化分析,作者在最後一個卷積層中使用了全卷積,而不是常見的 CNN 中的池化操作。在卷積層堆疊之後,使用了兩個全連線層;第一個有 64 個通道,第二個進行七路分類(每類一個)。在本文模型中,每個卷積層之後都引入了 ReLU 函數和 BN 層,而在最後一個全連線層中採用了 softmax 函數。

圖 1. 深度神經網路。該網路由五個卷積層和兩個全連線層組成。該模型將 fMRI 掃描作為輸入,並提供標記的任務類別作為輸出
對人腦進行特定任務解碼面臨的一個最大問題是可用資料有限。在其他類似的應用中,可以採用資料增強的方式以基於有限的資料生成更多的資料樣本。資料增強的主要目的是增加資料的變化,這可以防止過度擬合併提高神經網路的不變性。與傳統影象相反,本實驗中的輸入影象已經與標準的 MNI152 模板對齊。因此,在空間域進行資料增強是多餘的。考慮到輸入資料的不同持續時間,作者在時間域中應用了資料增強,以提高神經網路在這種情況下的泛化能力。在訓練階段的每個 epoch 中,從每個輸入資料項中隨機分割出 k 個連續的 TR 片段(實驗中 k=27)(圖 2a)。為了避免報告的準確性出現波動,在驗證和測試階段只使用由每個資料的前 k 個 TR 組成的片段。

圖 2. 模型訓練和網路視覺化的工作流程。(a) 模型自動學習標記的 fMRI 時間序列的特徵,並在驗證的損失達到最小時停止訓練。因此,模型訓練時不需要手工提取特徵。遷移學習的工作流程類似,只是使用訓練後的模型取代未訓練的模型。每個資料項的分類被反向傳播到網路層,以獲得對分類重要的部分的視覺化。視覺化的資料具有與輸入資料相同的大小,然後在時間維度上縮小,並對映到 fsaverage 表面
1.1.3 遷移學習
與傳統方法相比,深度學習方法,特別是 CNN 的一個重要優勢是其可重複使用性,這意味著訓練好的 CNN 可以直接在類似的任務中重複使用。作者對訓練好的 CNN 使用了遷移學習策略來驗證所提出的模型的適用性。遷移訓練的工作流程與初始訓練的工作流程基本相似(圖 2a),只是它從一個前四層已經訓練好的模型開始,而輸出層是未訓練的。作者採用了 HCP 的 TEST-RETEST 任務 - fMRI 組的 TEST 資料集(N = 43)訓練深度模型來分類兩個 WM 任務子狀態 ----0bk body 和 2bk-body。作者採用了按主題劃分的五重交叉驗證,其中 60% 的資料(25 個主題的 100 個樣本)用於訓練,20%(9 個主題的 36 個樣本)用於驗證,20%(9 個主題的 36 個樣本)用於測試(總共 172 個樣本的規模與常用的 fMRI 研究資料集相當)。為了進一步驗證,作者訓練深度模型來分類四個運動任務子狀態—左腳、左手、右腳和舌頭運動。使用五重交叉驗證,其中 60%(25 名受試者的 400 個樣本)用於訓練,20%(9 名受試者的 144 個樣本)用於驗證,20%(9 名受試者的 144 個樣本)用於測試(共 688 個樣本)。輸入樣本是一個連續的 BOLD 序列,涵蓋了整個區塊和區塊後的 8 秒,包括 HRF 的後訊號。
為了評估使用小樣本量的 fMRI 研究的 DNN 的適用性,作者對來自 HCP TEST 掃描的 43 個物件的資料進行了深度分類器的訓練。N = 1, 2, 4, 8, 17, 25, 34。為了避免準確性的差異,所有的測試都應用於 HCP TEST-RETEST 資料集中全部 43 名受試者的 RETEST 資料。深度學習在 120 個 epochs 後停止。此外,作者使用傳統的搜尋光和全腦 SVM-MVPA 方法進行實驗比較。
1.1.4 效能評估
為了評估該模型在不同分類任務中的表現,作者首先定義了一組參數。每個任務條件的 F1 分數被計算為 TP、FP 和 FN 的函數:F1=(2×TP)/(2×TP + FP + FN)。其中,TP 是真陽性,FP 是假陽性,FN 是每個標籤的假陰性。作者還通過一比一的方法計算每個標籤的 ROC 曲線,參數靈敏度和特異性表示為:靈敏度 sensitivity=TP/(TP+FN),特異性 specificity=TN/(TN+FP),其中 TN 是真陰性,等於其餘標籤的 TP 之和。準確率被定義為正確預測與分類總數的比率:準確率 accuracy=(TP + TN)/(TP + FP + TN + FN)。
1.1.5 網路視覺化分析
本文使用引導反向傳播(Guided back-propagation [4]) ,一種廣泛使用的深度網路視覺化方法,生成每個分類的模式圖和輸入 fMRI 4D 時間序列的任務加權表示。在標準的反向傳播過程中,如果一個 ReLU 單元的輸入是正的,那麼該單元的偏導就向後複製,否則就設定為零。在引導式反向傳播中,如果一個 ReLU 單元的輸入和部分導數都是正數,則該單元的部分導數被向後複製。因此,引導式反向傳播保持了對類別得分有積極影響的路徑,並輸出 CNN 檢測到的資料特徵,而不是那些它沒有檢測到的特徵。如圖 2b 所示,在向訓練好的網路輸入資料後,相對於輸入資料產生了 27×75×93×81 的預測梯度。然後,每個體素的時域絕對最大值的符號值被抽出並建立在三維任務模式圖中,然後被歸一化為其最大值。最後,將 pattern map 對映到 fsaverage 表面。此外,測試組的歸一化 pattern map 的 Cohen's d 效應被計算為每個任務的 pattern map 的平均值除以其 SD。
本文的視覺化對比分析是在 AFNI[5]、Freesurfer[6]、HCP Connectome Workbench和 MATLAB(MathWorks, Natick, MA)中進行。為了比較傳統的 GLM 圖和模式圖(pattern map),作者還從 HCP 任務的 fMRI 分析包中獲取了參數估計對比度(COPE)的 Cohen 效應。
1.2 實驗結果分析
首先,作者完成了針對深度模型在一般分類任務中的實驗。作者在實驗中使用 NVIDIA GTX 1080Ti 板進行了約 30 個 epoch 的訓練,所需時間大約 72 小時。本文所提出的模型成功地區分了七個任務,準確率為 93.7±1.9%(mean±SD)。根據 F1 得分,本文使用的模型 / 分類器在七個任務中的表現不同:情緒(94.0±1.6%)、賭博(83.7±4.6%)、語言(97.6±1.1%)、運動(97.3±1.6%)、關係(89.8±3.2%)、社交(96.4±1.0%)和 WM(91.9±2.3%,平均值 ±SD)。平均混淆矩陣(The average confusion matrix)顯示,前兩個混淆分別是由賭博與關係、WM 與關係引起的(圖 3a)。圖 3b 顯示了 ROC 曲線,根據該曲線,運動、語言和社交任務具有最大的曲線下面積(area under the curve,AUC),而賭博具有最小的面積。在驗證關鍵超參數的選擇,即 1×1×1 核通道的數量(NCh1)時,模型記錄的準確值分別為 93.2%、91.5% 和 92.7%,NCh1=3、9 和 27(圖 3c)。在 NCh1=1 的情況下,該模型無法在 30 個 epoch 內收斂。

圖 3. HCP S1200 任務 fMRI 資料集上的深度學習分類結果
然後,為了確定對每個分類貢獻最大的體素(Voxel,指一段時間內多次測量大腦某塊區域),作者使用引導式反向傳播法生成了模式圖,以視覺化模型學習到的模式。圖 4 給出了對任務 COPE 的 GLM 分析的 Cohen's d 效應大小的分組統計圖(圖 4a-g),以及 DNN 模式圖的 Cohen's d(圖 4h-n)。如圖所示,DNN 模式圖上的 Cohen's d 與 GLM COPEs 上的情感、語言、運動、社交和 WM 任務相似。例如,在語言條件下,GLMCOPEs(圖 4c)和 DNN 模式圖(圖 4j)中的 bilateral Brodmann 22 區出現了較大的效應大小異常。同樣,在運動任務的右手運動條件下,兩個圖(圖 4d,k)顯示在 Brodmann 4 和 bilateral Brodmann 18 區有類似的效應。

圖 4. HCP S1200 資料集上的 HCP 組平均值(左欄)和 DNN 熱圖(右欄)的 Cohen's d 效應
最後,關於遷移學習的問題,經過五次交叉驗證,本文提出的 DNN 在測試中達到了 89.0±2.0% 的平均準確率(圖 5a),平均 AUC 為 0.931±0.032(圖 5b)。如圖 5c 所示,通過雙樣本 t 檢驗,DNN 的準確性明顯高於 SVM-MVPA 全腦(t[8]=9.14,p=.000017;平均 ±SD=55.6±7.9%)和 SVM-MVPA ROI(t[8]=7.59,p=.000064;平均 ±SD=69.2±5.4%)。

圖 5. 工作記憶任務分類的遷移學習結果(0bk-body 與 2bk-body)
經過五次交叉驗證,本文提出的 DNN 的平均準確率為 94.7±1.7%(圖 6a),平均 AUC 為 ROC 0.996±0.005(圖 6b)。平均混淆矩陣顯示,最主要的混淆是由左腳與右腳造成的(圖 6a)。圖 6c 顯示,通過雙樣本 t 檢驗,DNN 的準確性(94.7±1.7%)明顯高於 SVM-MVPA 全腦(t[8]=3.59,p=.0071;平均 ±SD=81.6±7.1%)和 SVM-MVPA ROI(t[8]=8.77,p=.000022;平均 ±SD=68.6±5.7%)。然後,作者驗證了學習所需的資料量。所有三種方法在所有 N_Subj 中都報告了高於經典方法的準確性。N_Subj=8 足以使 DNN(80.3%)在準確性方面超過普通的 SVM-MVPA 全腦方法(41.7%)和 SVM-MVPA ROI(56.3%)(圖 6d)。

圖 6. 運動任務(左腳、左手、右腳和舌頭)的分類遷移學習結果
小結:本文提出的方法能夠直接從 4D fMRI 時間序列中對人正在進行的大腦功能進行分類和對映。本文方法允許從簡短的 fMRI 掃描中解碼受試者的任務狀態,無需進行特徵選擇。這種靈活高效的大腦解碼方法可以應用於神經科學的大規模資料和精細的小規模資料。此外,它的便利性、準確性和通用性的特點使得該深度框架可以很容易地應用於新的人群以及廣泛的神經影像學研究,包括內部精神狀態分類、精神疾病診斷和實時 fMRI 神經反饋等等。
2、使用深度生成神經網路從 fMRI 模式重建人臉

本文是發表在 Communications Biology 中的一篇文章[7]。由上一篇文章的介紹可以知道,目前,已經可以從功能磁共振成像的大腦反應中解碼識別不同的類別。但是,針對視覺上相似的輸入(例如不同的人臉)的分類和識別仍然是非常困難的。本文具體探討的是應用深度學習系統從人類的功能磁共振成像重建人臉影象。作者基於一個大型名人臉部資料庫使用一個生成對抗網路(GAN)的無監督過程訓練了一個變分自動編碼器(VAE)神經網路。自動編碼器的潛在空間為每幅影象提供了一個有意義的、拓撲學上有組織的 1024 維描述。然後,向人類受試者展示了幾千張人臉影象,並學習了多體素 fMRI 啟用模式和 1024 個潛在維度之間的簡單線性對映。最後,將這一對映應用於新的測試影象,將 fMRI 模式轉化為 VAE 潛在編碼,並將編碼重建為人臉。
2.1 模型介紹
本文所使用的 VAE-GAN 模型如圖 7(a)所示,其中的三個網路學習完成互補的任務。具體包括:編碼器網路將人臉影象對映到一個潛在的表徵(1024 維)上,顯示為紅色。生成器網路將其轉換為一個新的人臉影象。鑑別器網路(只在訓練階段使用)為每張給定的影象輸出一個二進位制的判斷,可以是來自原始資料集,也可以是來自生成器輸出,即:該影象是真的還是假的?訓練的過程具有 "對抗性",因為判別器和生成器的目標函數相反,並交替更新:如果鑑別器能夠可靠地確定哪些影象來自生成器(假的),而不是來自資料庫(真的),就會得到獎勵。如果生成器能夠產生鑑別器網路不會正確分類的影象,就會得到獎勵。訓練結束後,丟棄鑑別器網路,編碼器 / 生成器網路被用作標準(變分)自動編碼器。
網路中的 "人臉潛在空間" 提供了對大量人臉特徵的描述,可以近似於人腦中的臉部表現。在這個潛在空間中,人臉和人臉特徵(例如,男性)可以被表示為彼此的線性組合,不同的概念(例如,男性,微笑)可以用簡單的線性操作來處理(圖 7b)。作者分析,這種深度生成神經網路潛在空間的多功能性表明它可能與人腦的人臉表徵有同源性,這也使得它成為基於 fMRI 的人臉解碼的理想候選方法。由此,作者推斷,在對大腦活動進行解碼時,學習 fMRI 模式空間和這種潛在空間之間的對映,而不是直接學習影象畫素空間(或這些畫素的線性組合,例如 PCA 等的處理方法),可能是非常有用的。此外,作者推測 ,VAE-GAN 模型能夠捕捉人臉表徵的大部分複雜性,使 "人臉流形" 變得平坦,就像人類大腦可能做的那樣。因此,作者認為,採用簡單的線性大腦解碼方法就足夠了。

圖 7. 深度神經網路潛在空間。(a)VAE-GAN 網路架構。(b)潛在空間屬性
作者首先使用無監督 GAN 在 202,599 張名人人臉標記資料庫上訓練了一個 VAE 深度網路(13 層)(CelebA[8]),共執行 15 個 epoch。使用編碼器處理向人類受試者展示的人臉影象以生成 1024 維的潛在編碼,這些編碼作為設計矩陣後續會用於 fMRI GLM(一般線性模型)分析。作者使用 SPM12 處理 fMRI 資料(https://www.fil.ion.ucl.ac (https://www.fil.ion.ucl.ac/).uk/spm/software/spm12/)。接下來,作者對每份資料分別進行了切片時間校正和重新對齊。然後將每個時段的資料與第二個 MRI 時段的 T1 掃描資料進行聯合登記。不過,作者並未對這些資料進行歸一化或平滑化處理。具體的,作者將每個實驗的開始和持續時間(固定、訓練臉、測試臉、單人背影或意象)輸入一般線性模型(general linear model,GLM)中作為迴歸因子;將用於訓練臉部的 1024 - 維潛在向量(來自 VAE-GAN 或 PCA 模型)作為參數化的迴歸器來建模,並將運動參數作為滋擾迴歸器(nuisance regressors)輸入用於消除滋擾訊號。此外,在估計 GLM 參數之前,令整個設計矩陣與 SPM 的血流動力學反應函數(hemodynamic response function,HRF)進行卷積處理。
作者訓練了一個簡單的大腦 fMRI 的編碼器(線性迴歸),將人臉影象的 1024 維潛在表徵(通過 "編碼器" 運行影象,或使用 PCA 變換獲得)與相應的大腦反應模式聯絡起來,並將人類受試者在掃描器中觀看相同的人臉時記錄下來。圖 8(a)給出了這一過程的完整描述。每個受試者平均看到超過 8000 張人臉(每個人都有一個演示),使用 VAE-GAN 潛在維度(或影象在前 1024 個主成分上的投影)作為 BOLD 訊號的 1024 個參數化迴歸因子。這些參數化的迴歸因子可以是正的,也可以是負的(因為根據 VAE 的訓練目標,VAE-GAN 的潛在變數是近似正態分佈的)。將一個額外的分類迴歸因子("面部與固定" 對比)作為一個恆定的 "偏差" 項新增到模型中。作者驗證了設計矩陣是 "full-rank" 的,也就是說,所有的迴歸因子都是線性獨立的。作者分析,這一屬性是因為 VAE-GAN(和 PCA)的潛在變數往往是不相關的。因此,由 SPM GLM 分析進行的線性迴歸產生了一個優化的權重矩陣 W,以預測大腦對訓練人臉刺激的反應模式。

圖 8. 基於 VAE-GAN 潛在表徵的人臉影象的大腦解碼。(a)訓練訓階段。(b)測試階段
假設在 1025 維的人臉潛在向量 X(包括了一個偏置項)和相應的大腦啟用向量 Y 之間存在一個線性對映 W:

訓練大腦解碼器通過以下方式找到最佳對映 W:

為了在 "測試階段" 使用這個大腦解碼器,作者簡單地反轉了線性系統,如圖 8b 所示。作者向同一受試者展示了 20 張新的測試人臉,這些人臉在訓練階段並沒有向受試者展示過。每個測試人臉平均呈現 52.8 次以增加信噪比。所得的大腦活動模式簡單地與轉置的權重矩陣 W^T 及其反協方差矩陣相乘,以產生 1024 個潛在人臉維度估計值。然後,使用 GAN(如圖 7a 所示)將預測的潛在向量轉化為重建的人臉影象。對於基線 PCA 模型,方法的流程是相同的,但人臉的重建是通過解碼的 1024 維向量的 inverse PCA 獲得的。測試大腦解碼器包括使用學到的權重 W 為每個新的大腦啟用模式 Y 檢索潛在的向量 X,利用下式求解 X:

作者已經將本文使用的預訓練的 VAE-GAN 網路以及 Python 和 TensorFlow 原始碼公佈在了 GitHub 上:https://github.com/rufinv/VAE-GAN-celebA.
2.2 實驗結果分析
本實驗中,通過 Amazon Mechanical Turk (AMT)獲得用於比較 VAE-GAN 和 PCA 人臉重建的影象質量的人類評價結果。四個受試者的 20 張測試影象中的每一張都標記為 "原始 」,然後是 VAE-GAN 和基於 PCA 的重建影象,在" 選項 A "和" 選項 B "的字樣下顯示。實驗中,向受試者釋出的指示為:" 在兩個修改過的人臉中,哪一個最像原來的人臉?選擇 A 或 B"。每對影象總共被比較了 15 次,由至少 10 個不同的 AMT" 工作者 " 進行,每個反應分配(VAE-GAN/PCA 為選項 A/B)由至少 5 個工作者檢視。因此,該實驗在兩個人臉重建模型之間總共進行了 1200 次(=4×20×15)比較。
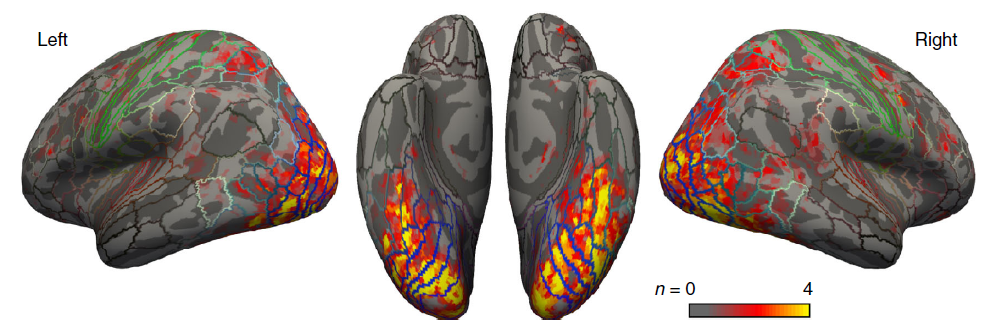
作者首先對比了 VAE-GAN 和 PCA,將灰質體素的一個子集定義為 "興趣區域" (ROI)。事實上,大腦的許多部分都在進行與人臉處理或識別無關的計算。作者的 ROI 只選擇生理上的可能應激大腦區域,選擇標準考慮了兩個因素。(i) 預計體素會對人臉刺激作出反應(通過臉部和基線條件之間的 t 檢驗來確定,即固定在空螢幕上),(ii)將 1024 個潛在人臉特徵作為迴歸因子輸入線性模型時,體素的 BOLD 反應的解釋方差有望改進(與只有二元人臉迴歸因子的基線模型相比:存在 / 不存在人臉)。所選的體素如圖 9 描述,包括 枕部、顳部、頂部和額部區域。作者對 PCA 人臉參數進行了單獨的選擇, 並將這些參數用於基於 PCA 的 "大腦解碼器"(所選體素的平均數量:106,685;範圍:74,073-164,524);兩個模型所選區域幾乎相同。

圖 9. 為大腦解碼選擇的體素。在大腦解碼器訓練階段,體素的選擇是基於其視覺反應性和 GLM 擬合度的綜合考慮(圖 8a)。顏色程式碼(紅色到黃色)表示每個特定體素被選中的受試者的數量(1-4)。彩色的線表示標準皮質區域的邊界
圖 10(a)給出了人臉重建影象的示例。雖然 VAE-GAN 和 PCA 都能重建出與原始人臉相似的影象,但是由 VAE-GAN 重建的影象更真實,更接近原始影象。作者通過將 20 張測試人臉的大腦估計潛在向量與 20 張實際人臉的潛在向量相關聯來量化大腦解碼系統的效能,並使用成對相關值來測量正確分類的百分比。具體結果見圖 10(b)。實驗結果表明,從人腦啟用到 VAE–GAN 潛在空間的線性對映比到 PCA 空間的對映更容易、更有效。作者認為,這與其 「深度生成神經網路更接近於人臉表徵的空間」 的假設相吻合。此外,作者還進行了模型間的完全識別結果比較,即利用重建影象的感知質量作為指標衡量重建的人臉水平。實驗要求人類觀察者比較兩種模型重建的人臉質量:四個受試者的原始測試影象與相應的 VAE-GAN 和 PCA 重建影象一起顯示,受試者判斷哪一個重建影象從感知角度判斷更像原始影象。具體結果見圖 10(c)。76.1% 的實驗中受試者選擇了 VAE-GAN 重建的影象,而 23.9% 的實驗中受試者選擇了 PCA 重建的影象。

圖 10. 人臉重建。(a)重建人臉影象示例;(b)兩兩識別結果;(c)完全識別結果
進一步的,為了確定哪一個大腦區域對兩個大腦解碼模型的人臉重建能力貢獻最大,作者將每個受試者的體素選擇劃分為三個大小相等的子集,如圖 11a 所示。然後分別對這三個子集進行腦解碼和麵部重建。兩兩識別結果顯示,枕骨體素和較小程度的顳體素提供了大腦解碼所需的大部分資訊(圖 11b)。

圖 11. 不同腦區的貢獻情況。(a)體素分割過程;(b)不同區域的兩兩識別結果,Full select 指的是圖 9 中描述的體素集;它與圖 10b 中的資料相同。圓圈代表個別受試者的表現。虛線是單個受試者表現的 p<0.05 的顯著性閾值。在三個子集中,枕部體素的表現是最優的,其次是顳部體素。在所有情況下, VAE-GAN 模型的效能仍然高於 PCA 模型。
最後,作者通過創建一個簡單的分類器以根據人臉屬性為大腦解碼的潛在向量貼標籤的方式,研究人腦對於特定人臉屬性的表徵。具體的關於人臉 「性別」 屬性的實驗結果見圖 12。將每個大腦解碼的潛在向量投射到潛在空間的 "性別" 軸上(圖 12a),投射的符號決定了分類輸出(正數代表「男性」,負數代表「女性 」)。由圖 12b 的結果可以看出,這個單一衡量標準的分類器提供了足夠的資訊來對人臉性別進行分類,準確率達到了 70%。非參數 Friedman 檢驗表明,性別解碼效能在三個體素子集中是不同的,而 post hoc 檢驗則顯示枕葉體素的表現明顯好於額頂葉體素,而顳葉體素介於兩者之間。

圖 12. 圖 6 性別解碼。(a)基本線性分類器;(b)解碼準確度
3、AI 解碼大腦神經反饋動力學 - 用於解碼神經反饋實驗的資料

本文是來自日本 ATR 國際學院計算神經科學實驗室的研究人員發表在《Scientific Data》2021 上的一篇文章[9],主要為利用 AI 解碼大腦神經反饋以讀取和識別大腦中特定資訊的方法提供實驗所需的資料。解碼神經反饋(Decoded neurofeedback,DecNef)是一種閉環 fMRI 神經反饋與機器學習方法相結合的形式,意思是分析 fMRI 的狀態改變外圍不同裝置(比如被測者面前的顯示器)的刺激。這是對操縱大腦動力學表現或表徵這一長期目標的更細化的呈現。本文針對 DecNef 實驗,提供了可應用的資料來源。作者釋出了一個大型的、可公開訪問的神經影像學資料庫,其中包括 60 多個接受 DecNef 訓練的人。這個資料庫由大腦的結構和功能影象、機器學習解碼器和額外的處理資料組成。作者在文中描述了編譯資料庫時採用的協議,包括源資料中常見的和不同的掃描參數、元資料、結構,以及匿名化、清理、排列和分析等處理方式。
3.1 DecNef 背景分析
在單變數(univariate)方法中,人們具體測量一個感興趣區域(ROI)的整體活動水平。與此不同,多體素模式分析(multivoxel pattern analysis,MVPA)則是學會對分佈在活動模式中的資訊進行解碼。DecNef 利用了 MVPA 而不是使用單變數方法,因此它具有很高的目標特異性。此外,儘管受試者清楚解碼神經反饋實驗的存在,但他們並不知道具體的內容和目的,從而有助於減少由於認知過程或對被操縱維度的瞭解而產生的混淆。此外,解碼神經反饋實驗甚至可以通過一種稱為 "超邊界(hyperalignmen)" 的方法,根據受試者間接推斷出目標神經表徵。通過這樣的功能排列方法,將不同受試者的神經活動模式通過一組線性變換構建了一個共同的、高維的空間。這些轉換是有效的參數,可以用來將任何新的資料模式帶入 / 帶出個人的大腦座標系統和模型空間座標。上述特點使得 DecNef 成為了開發新的臨床應用的一種有效工具,特別是在神經精神疾病方面。除了面向臨床的研究外,DecNef 還可以作為系統和認知神經科學的一個重要正規化來研究大腦的基本功能。
不同的 DecNef 實驗探究的是不同的認知過程或心理表徵,但所有研究都採用了相同的基本設計邏輯(如圖 13a)。(1)最初的環節是獲取 fMRI 資料,用於訓練機器學習演算法—MVPA 或解碼器構建環節。(2)隨後的神經反饋階段,持續 2 到 5 天不等。在解碼器構建環節,受試者完成了簡單的動作,包括視覺(研究 2、3)、偏好(研究 1)、知覺(研究 4)或記憶任務(研究 5),在神經反饋環節,所有程式幾乎都是相同的(圖 13b)。在神經反饋訓練中,要求受試者調節或操縱他們的大腦活動,以最大限度地擴大反饋盤(feedback disc)的大小。

圖 13. 實驗設計的示意性概述。(a) 每項研究都包括一段 fMRI,用於獲得構建 "解碼器" 所需的資料,這是一個機器學習的大腦活動模式分類器。(b) 所有的研究都有相同的基本實驗設計
已經發表了關於如何運行解碼神經反饋實驗這部分工作的介紹[10]。不過,關於 DecNef(以及一般的神經反饋)的一個關鍵問題仍未解決:潛在神經機制究竟是什麼?一些近期的研究工作已經開始聚焦於這個問題,並應用了元分析、計算模型、神經網路等工具。表 2 總結了已有的部分研究,包括相關出版物、神經反饋過程訓練目標等內容。

表 2. 納入資料收集的研究摘要
3.2 資料分析
關於本文提供的源資料,表 3 給出所有研究中使用的掃描參數的技術細節,以及不同研究之間的差異。

表 3. 不同研究之間的掃描參數
可通過機構儲存庫 "DecNef 項目大腦資料儲存庫(DecNef Project Brain Data Repository)"(https://bicr-resource.atr.jp/drmd/),或從 Synapse 資料儲存庫 (https://doi.org/10.7303/syn23530650) 訪問資料。資料是按照圖 14 所示的結構來組織的。簡而言之,對於每項研究,最上層的資料夾包含了每個受試者的資料夾(例如,"sub-01")。其中有三個子資料夾,"anat" 包含與結構 / 解剖掃描有關的原始 Nifti 檔案,"func"—進一步細分為特定會話資料夾(例如,"ses-0":解碼器,"ses-1":神經反饋的第一個會話,等等),包含所有來自功能掃描的壓縮 Nifti 檔案。

圖 14. 資料集結構和內容
對高解析度的解剖學掃描進行塗抹處理,以確保結構資料的適當匿名化。使用統計參數對映(SPM)對影象進行了偏差校正。使用統計參數繪圖(SPM)工具箱(https://www.fil.ion.ucl.ac.uk/spm/)對影象進行偏差校正,並使用 FreeSurfer 套件的自動塗抹工具進行塗抹。圖 15 為一個受試者的影象結果示例。

圖 15. 受試者結構掃描的匿名化(汙損)處理示例
鑑於 DecNef 方法的細粒度、高空間解析度的要求,用於線上反饋計算的大腦影象的功能排列需要具備非常高的會話間一致性。影象必須與原始解碼器的結構對齊,而且這種對齊必須在(子)體素水平上是精確的。即使是微小的頭部運動也很容易破壞這一前提條件,導致不完善的解碼和反饋得分計算。為了滿足這一要求,所有的研究都要求實時監測傳入的大腦功能影象與原始解碼器結構中的模板之間的對齊情況。儘管使用 Turbo BrainVoyager(TBV,Brain Innovation)實時校正頭部運動,但並不能保證校正後的影象在解碼方面是有意義的,尤其是在突然出現明顯位移時。因此,在實時神經反饋實驗中,對原始 DICOM 影象進行了以下處理步驟。首先,在誘導期測量的功能影象使用 TBV 進行三維運動校正。第二,從解碼器識別的每個體素中提取訊號強度的時間序列,並將其移位 6 秒以考慮到血流動力學延遲。第三,從時間過程中去除線性趨勢,並使用從每次 fMRI 運行開始後 10 秒測量的訊號強度對每個體素的訊號時間過程進行 Z-score 歸一化處理。第四,計算反饋分數的資料樣本是通過平均每個體素在誘導期的 BOLD 訊號強度來創建的。
在目標體素的啟用模式方面,控制資料質量的一個有效方法是首先計算它們的平均啟用(用初始解碼器構建會話的資料)。然後,在實時會話中,計算平均模式和傳入活動模式之間的逐個相關性。這種方法確保了當體素的反應模式由於例如頭部或身體運動而發生重大變化時,相關度的降低會迅速發生,從而可以被檢測到。最佳水平的相關性水平應該在 r∈[0.85 1.00]的區間內,或 Fisher 變換的 z∈[1.26 Inf]。作者證實,所有的研究確實都能滿足此條件(圖 16)。平均來說,只有不到 2% 的實驗的 z 值小於 1.26(研究 1:0.13%,研究 2:3.17%,研究 3:0.91%,研究 4:0.36%,研究 5:3.74%)。

圖 16. 平均活動模式和實時活動模式之間的費舍爾轉換相關性(Fisher transformed correlation)。較大值表明實時測量模式和解碼器構造模式之間有更好的功能一致性。每個點代表一個實驗的相關值。每個琴狀圖有 N(天)×M(受試者)×L(運行)×J(實驗)個點。圖中央的白圈代表中位數,粗灰線代表四分位數範圍,細灰線代表相鄰的數值。將 z<1.10 的資料點從圖中刪除
接下來,作者建立了頭部運動和模式相關度之間的關係。作者使用 SPM12 計算了頭部運動參數,得出了 3 個平移參數和 3 個旋轉參數。為了這個分析的目的,作者通過對相關的 3 個參數進行平均化處理來計算平均絕對旋轉和平均絕對平移,在神經反饋實驗中使用的 3 個 TR 來計算解碼器的可能性和模式的關聯性。作者將這兩個頭部運動指數(以毫米為單位)與所有研究中彙集的 Fisher 轉換後的相關係數(即模式相關度)進行了對比(如圖 17 所示)。為了進行統計分析,作者串聯單次實驗資料,使用線性混合效應(linear mixed effects,LME)模型進行分析(按照 Wilkinson 符號,指定為 y ~ 1 + m + (1 | st) + (1 + st | prt);其中 y:模式相關性,1:截距,m:運動參數,st:實驗研究,prt:受試者)。具體來說,這些 LME 模型的設計是將運動作為固定效應,實驗研究作為隨機效應和協變數,個體受試者作為隨機效應而巢狀在實驗研究中。

圖 17. 模式相關性與頭部運動的關係。頭部運動被計算為三維方向上的旋轉(a)或三維方向上的平移(b),並與 Fisher 轉換後的模式相關係數成圖。使用不同顏色繪製來自不同研究的資料點。每個資料點表徵一個特定受試者、運行和實驗
最後,其他的生理噪聲源(如心跳或呼吸)也會影響用於實時解碼的多體素活動模式。這些來源在本研究中沒有直接測量,因此作者只能猜測它們的影響。如果它們對所有體素的影響是相對均勻的,作者預計對模式相關的測量幾乎沒有影響,因為體素之間的關係將保持基本不變。如果各體素之間存在不均勻的影響,作者認為模式相關性會受到類似於頭部運動的影響。人們可能會擔心,在第一種情況下,將無法檢測到資料的噪聲失真,從而有可能造成反饋給受試者的目標真實性失效。但由於所有體素的活動首先經過基線歸一化處理,然後通過計算體素的活動模式與權重向量之間的點積來確定反饋似然,因此重要的是體素的模式(體素活動之間的 "差異")。由此,作者指出,由於 MVPA 的特殊性,額外的噪聲源不太可能在不影響模式相關度的情況下顯著影響體素活動模式的資訊內容。
4、小結
本文探討了基於統計學中 ML 的 fMRI 分析方法。其中, 第一篇文章介紹了基於 SVM 的多變數模式分析在基於人腦功能磁共振成像(fMRI)的特定任務狀態解碼中的應用。具體的,作者引入一個 DNN 分類器,通過讀取與任務相關的 4D fMRI 訊號,有效解碼並對映個人正在進行的大腦任務狀態。DNN 的分層結構使其能夠學習比傳統機器學習方法更復雜的輸出函數,並且可以進行端到端的訓練,進而提升了大規模資料集中 fMRI 解碼的準確度水平。第二篇文章具體探討的是應用深度學習系統從人類的功能磁共振成像(fMRI)重建人臉影象。利用 VAE-GAN 模型,學習多體素 fMRI 啟用模式和 1024 個潛在維度之間的簡單線性對映。然後將這一對映應用於新的測試影象,將 fMRI 模式轉化為 VAE 潛在編碼,並將編碼重建為人臉。最後一篇文章釋出了一個大型的、可公開訪問的神經影像學資料庫,該資料庫中的資料是由解碼神經反饋(Decoded neurofeedback,DecNef)實驗訓練得到的,除了面向臨床的研究外,該資料庫還可以作為系統和認知神經科學的一個重要正規化來研究大腦的基本功能。這一資料庫的釋出為推動解碼神經反饋的研究發展提供了良好的資料基礎。
ML 已經證明在影象處理和識別的廣泛用途。利用 ML 連線 fMRI 影象,可以分類人腦正在觀察和思考的狀態,甚至重建正在聯想的人臉內容。神經科學家正在藉助機器學習技術解碼人類大腦的活動、理解人類大腦的趨勢方興未艾,幫助我們更好的瞭解我們的大腦迷宮。
相關文章
機器之心分析師網路作者:Jiying編輯:Joni這篇文章圍繞機器學習(ML)和功能性磁共振成像(fMRI)的應用問題,以三篇最新的研究型論文為基礎,探討基於統計學中 ML 的 fMRI 分析方法。本文
2021-06-29 19:31:26

不知道什麼時候,手機拍照也是各大手機廠商新機的一大賣點,後置攝像頭越多、後置畫素越高也就代表手機越高階。如今的國產手機,後置畫素基本4800萬起步,三星、小米等在去年就已經
2021-06-29 19:30:53

格力作為國產空調行業龍頭,但近兩年似乎後繼乏力,龍頭之位則被另一家國產家電巨頭——美的收入囊中。值得一提的是,格力不僅把國產空調龍頭的位置「讓」了出去,而且在市值上還落
2021-06-29 19:30:21

根據外媒報道,華為將會在我國武漢建造第一家晶圓廠,並會從明年開始分階段投產。但與很多人想象的不同,華為這座晶片工廠,將專注於光通訊領域,名稱為華為海思武漢光晶片工廠,主要生
2021-06-29 19:12:34
6月2日,華為鴻蒙的面世成為中國作業系統發展史上一座里程碑。在鴻蒙上線後,消費者以及商業夥伴的熱情遠超筆者的想象。據一位花粉表示,更新入口開放後的數天時間內,一度因為進入
2021-06-29 19:08:23

小米終於更新了自家的「電競」快速液晶顯示器了,尺寸與上一代保持一致,同樣是 24.5 英寸,但是螢幕的重新整理率從原本的 144Hz 升級到了 165Hz,給電競玩家帶來更流暢的重新整理
2021-06-29 18:50:22