機器之心專欄知乎、清華大學知乎聯合清華大學對外開放基於知乎的大規模富文字查詢和推薦資料集「ZhihuRec」。該資料集包含了知乎上的 1 億個行為資料,是目前為止,國內用於個
2021-06-30 16:13:37
機器之心專欄
知乎、清華大學
知乎聯合清華大學對外開放基於知乎的大規模富文字查詢和推薦資料集「ZhihuRec」。該資料集包含了知乎上的 1 億個行為資料,是目前為止,國內用於個性化推薦的最大的實際互動資料集。
資料在機器學習中扮演著重要角色。在推薦系統的研究中,對使用者建模來說,使用者行為和附帶資訊都非常有幫助。因此,大規模真實場景下的使用者豐富行為是非常有用的資料。但是,這些資料很難獲取,因為這種資料大部分都被公司擁有並且保護起來。
本文中,知乎聯合清華大學對外開放基於知乎的大規模富文字查詢和推薦資料集ZhihuRec。該資料集中的曝光數接近 1 億,並具有目前為止最豐富的上下文資訊,覆蓋 10 天、79.8 萬用戶、16.5 萬個問題、55.4 萬個回答、24 萬個作者、7 萬話題以及 50.1 萬用戶搜尋行為日誌。它可以被用於各種推薦方法,如協同過濾、基於內容的推薦、基於序列的推薦、知識增強的推薦和混合推薦等。此外,由於 ZhihuRec 資料集中資訊豐富,不僅可以將它應用於推薦研究,還可以將它應用於使用者建模(如性別預測、使用者興趣預測)、跨平臺應用(查詢平臺和推薦平臺)等有趣的課題。據瞭解,這是用於個性化推薦的最大的實際互動資料集。
總結來說 ZhihuRec 資料集主要具有三個優點:
ZhihuRec 是最大的公共推薦資料集,包含從知乎收集的各種使用者互動,該資料集是開源的。ZhihuRec 資料集提供了豐富的內容資訊,包括問題、回答、個人資料、話題。特別是使用者的搜尋日誌也會顯示出來,這些以前沒有包含過。除 top-N 推薦、上下文感知推薦等推薦研究外,ZhihuRec 還可用於各種研究領域,例如使用者建模、整合搜尋和推薦研究。

論文地址:https://arxiv.org/pdf/2106.06467.pdf資料集地址:https://github.com/THUIR/ZhihuRec-Dataset資料集簡介
下表 1 展示了 ZhihuRec 與其他一些經典推薦資料集之間的差異,結果表明,ZhihuRec 資料集比傳統推薦資料集包含更多的資訊和類型,如文字、使用者畫像、物品屬性、時間戳等。

表格中 O 表示 ZhihuRec 資料集中雖然沒有記錄使用者具體的評分 / 收藏行為,但是記錄了使用者的收藏回答總量。
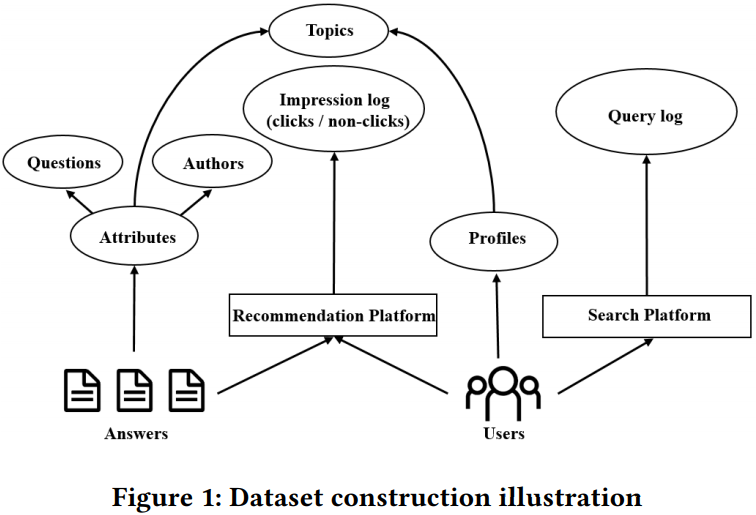
下圖給出了 ZhihuRec 資料集的構建過程,可以看出資料集包含的上下文資訊有使用者對回答的點選和瀏覽行為日誌、使用者查詢詞記錄、使用者畫像資訊、答案屬性資訊、問題屬性資訊、作者畫像資訊和話題屬性等各類資訊,以及每個使用者最多 20 個最近查詢關鍵詞。

表 2 顯示了 ZhihuRec 中每個印象記錄的欄位及其說明。根據答案的讀取時間,所有使用者的點選和未點選的印象都記錄在資料集中。

表 3 顯示了 ZhihuRec 資料集中的每個搜尋記錄的欄位及其說明。所有使用者的搜尋關鍵字和時間戳都記錄在資料集中。

由於 ZhihuRec 資料集包含約 1 億個使用者 - 答案互動,因此也稱為 Zhihu100M。此外,還構造了兩個從 Zhihu100M 資料集中隨機抽取的較小資料集,稱為 Zhihu20M 和 Zhihu1M,以滿足各種應用需求。它們包含大約 2000 萬和 1M 的使用者答案日誌,可以將其視為中等大小的資料集和相對較小的資料集。表 4 中顯示了它們的一些統計資訊。

使用者畫像和屬性都記錄在 ZhihuRec 中。該資料集保留使用者、問題、回答和作者的內容資訊。表 5 顯示了使用者的屬性,表 6 顯示了回答的屬性,表 7 顯示了問題的屬性,表 8 顯示了作者的屬性。

使用者的屬性。

回答的屬性。

問題的屬性。

作者的屬性。
如表中所示,關於使用者、問題、回答和作者的功能十分豐富,可以對使用者和內容(回答)進行全面建模。問題屬性中沒有 authorID,原因是隨著時間的推移,許多人可以修改知乎問答社群中的問題。
請注意,authorID 與 userID 是不同的,這意味著如果一個人在資料集中同時扮演使用者和作者的角色,則其 authorID 和 userID 是不同的,因為釋出者和閱讀者是不同的角色。
每個使用者或問題還具有幾個話題(從 0 到 70,308),由使用者本人(使用者話題)或系統使用者(問題話題,所有使用者都可以對其進行編輯)標記。它提供了一種更明確的方式來幫助瞭解使用者的興趣和問題的類型,這對於推薦也很有用。每個話題都有一個話題 ID 和話題描述作為其屬性,話題 ID 進行了雜湊處理,並且話題描述中的所有上下文都已轉換為數字編號。
資料集隱私保護
由於整個資料集都是從真實場景中的真實使用者那裡收集的,因此有必要保護使用者隱私。因此,並非使用者的所有內容資訊都被釋放。
ZhihuRec 資料集中的所有 ID 均被匿名和雜湊處理。所有文字資訊(例如問題的標題、回答的內容、話題的描述和搜尋關鍵字)均被分解為單詞,並且所有單詞均被數字替換。使用者畫像中的所有文字功能(例如性別、註冊類型、登入頻率、省、城市)也都已轉換為數字號碼。因此,無法從 ZhihuRec 資料集中獲取使用者個人資料和內容屬性的詳細資訊。
ZhihuRec 資料集刪除了使用者的出生日期、工作經歷、教育經歷等敏感資訊。使用者的網路資訊 (如 IP 地址) 也已被刪除。使用者對回答的顯式反饋如贊同、感謝、收藏、評論、反對和舉報等都被隱藏,ZhihuRec 資料集只儲存了相關的總的統計量,如使用者總的贊同數、收藏數、評論數、反對數和舉報數等。
資料集統計特性
圖 2 顯示了使用者註冊時間的分佈;可以發現,隨著時間的推移,每月註冊使用者的數量逐漸增加。

圖 3 顯示了每個話題的使用者分佈數:

圖 4 顯示了每個話題下的問題分佈數:

圖 5 顯示了每個話題下的回答分佈數。它顯示大多數使用者關注的話題少於 100 個,大多數回答和問題繫結不止一個話題。

圖 6 顯示了 ZhihuRec 資料集中每個搜尋的使用者分佈數量。大多數使用者的搜尋少於 3 個,並且分佈顯示出類似對數的衰減。但是,有許多使用者有 20 個搜尋,原因是研究者在此處進行了截斷(最多將保留該使用者的 20 個最近搜尋關鍵字)。

資料集在多項推薦任務中的應用
topN 推薦
使用者的互動日誌包含在 ZhihuRec 資料集中;從推薦系統的角度來看,可以將使用者在日誌中互動的回答視為商品。該資訊適用於協同過濾,其中包含通用的 topN 推薦的主要方法。為了評估 ZhihuRec 資料集的效能,在 Zhihu1M 資料集中應用了 5 種推薦演算法。
Pop:此基準始終會推薦訓練集中最受歡迎的回答(使用者點選)。ItemKNN:此方法選擇前 K 個最近鄰,並使用其資訊進行預測。BPR:此方法應用貝葉斯個性化排名目標函數來優化矩陣分解。 LightGCN:此方法使用圖卷積網路來增強協同過濾的效能。ENMF:使用高效神經矩陣分解的非取樣神經網路推薦模型。實驗已使用 RecBole 完成。對於所有方法,使用者和回答的 embedding 大小為 64。ItemKNN 的鄰居數為 100。採用留一法(Leave-one-out)。實驗結果如表 9 所示:

序列推薦
序列推薦在改善許多推薦任務的效能方面起著重要作用,因為它們可以揭示使用者的動態偏好,這也是前 N 個推薦。通常,序列推薦與傳統推薦之間的區別在於序列推薦需要清晰的時間資訊。它使用使用者互動的商品序列作為輸入,並根據互動時間戳對商品進行排序。推薦系統中對商品的展示也有排序。由於所有使用者的互動都記錄在 ZhihuRec 資料集中,因此本文已在 Zhihu1M 資料集中應用了四個最新的序列模型(FPMC 、GRU4Rec、NARM 、SASRec)。
FPMC:此方法基於基礎馬爾可夫鏈上的個性化過渡圖,並結合了 MF。 GRU4Rec:基於會話的模型,使用 RNN 捕獲序列依賴關係並進行預測。 NARM:此方法使用具有注意力機制的混合編碼器來捕獲使用者的意圖。 SASRec:採用自注意力層來捕獲動態使用者互動序列的順序模型。實驗已使用 RecBole 完成。對於所有方法,使用者和回答的 embedding 大小為 64。使用留一法。實驗結果如表 10 所示:

上下文感知推薦
上下文感知推薦模型使用來自使用者、商品和上下文來增強模型效能。上下文感知推薦結合了不同推薦模型的優勢,例如協同過濾,基於內容的模型以獲得更好的推薦;該資料集非常適合上下文感知推薦。如點選預測任務中通常描述的那樣,一個使用者點選一個回答的互動標記為 1,而該使用者有被展示但不點選一個回答的互動標記為 0。本文在 Zhihu1M 資料集中應用了 4 個最新的上下文感知模型。
Wide&Deep :由 Google 提出,它結合了深度神經網路和線性模型,並廣泛用於實際場景中。NFM :使用雙向互動層對二階特徵互動進行建模的神經模型。ACCM:這是一個注意力協同和內容模型,它將內容和使用者互動結合在一起。CC-CC:此方法使用自適應 「特徵取樣」 策略。實驗已使用 CC-CC 工具箱完成。所有方法的使用者和回答的 embedding 大小為 64。對於每個使用者,最後一次點選和最後一次點選之後的展示均被視為測試集,最後一次點選之前的點選以及最後一次點選之前的點選和最後一次點選之間發生的展示被視為驗證集,其他被視為訓練集。實驗結果如表 11 所示:

跨場景推薦
如上所述,使用者的搜尋關鍵字也包含在 ZhihuRec 資料集中;搜尋使用的關鍵詞可以視為其明確的需求資訊。雖然以前的推薦系統的研究主要集中於從使用者的隱式反饋中學習,但如果更多的研究人員嘗試整合搜尋和推薦,將很有幫助,這將有助於更好地瞭解使用者的資訊需求並提供更好的資訊服務。該資料集由於其豐富的搜尋和推薦日誌可以應用於此類研究。
基於負反饋的推薦
當用戶與回答進行互動時,他們會給答案以正反饋和負反饋。正面反饋是指使用者對回答進行點選、收藏、點贊等。負反饋則是使用者刪除、跳過回答等。傳統的推薦資料集存在缺乏負反饋問題。ZhihuRec 資料集同時記錄了使用者的正反饋和負反饋。利用使用者的負向偏好可以提高推薦質量,該資料集適用於基於負反饋的推薦模型。
由於 ZhihuRec 資料集具備了豐富的上下文資訊,它還可以被用在推薦之外的任務上,例如識別最有價值的回答者、識別優質回答等。
結論
本文介紹了來自線上知識共享社群的一個新資料集,旨在為個性化推薦做出貢獻。據瞭解,這是一個包含詳細資訊的最大的公開資料集,包括使用者、內容、行為、作者、話題以及包含搜尋和對推薦結果是否點選的使用者互動日誌。該研究呈現了有關最新演算法在該資料集上的實驗結果。該資料集可用於以下方面的研究:上下文感知推薦、序列推薦、利用負反饋的推薦、整合搜尋和推薦以及使用者畫像和內容屬性的建模。該資料集是公開可用的,並且在互動日誌和搜尋關鍵字中包含大量資訊,適合跨平臺研究。
相關文章
機器之心專欄知乎、清華大學知乎聯合清華大學對外開放基於知乎的大規模富文字查詢和推薦資料集「ZhihuRec」。該資料集包含了知乎上的 1 億個行為資料,是目前為止,國內用於個
2021-06-30 16:13:37

2021年6月,榮耀推出了它的全新產品,榮耀50系列手機。這一次榮耀的數字系列沉澱了一年之久,以體驗至上的姿態迎接每一位使用者,它在各方面的效能表現也沒有讓人失望,甚至有
2021-06-30 16:12:53

蘋果訂單迴流,值得慶祝?往外運輸材料費用不斷增加,再加上在印建廠不順利,招聘新員工、管理等方面都出了問題,富士康不堪壓力還是回國再招聘新員工為產線加能趕工期。蘋果呢?此前庫
2021-06-30 16:12:44

晶片製程的不斷萎縮,令全球積體電路產業進入後摩爾時代。隨著工藝精度的演進,理論上來講會面臨物理極限,但為了滿足市場需求,一眾專業晶圓代工巨頭以及相關裝置供應商都在想方設
2021-06-30 16:12:32
IT之家 6 月 30 日訊息 6 月 29 日凌晨,微軟面向 Dev 開發頻道釋出了第一個 Windows 11 Insider Preview 版本,即 Build 22000.51! 微軟表示,隨著我們在未來幾個月內完成產品
2021-06-30 16:12:05

近兩年華為憑藉P系列和Mate系列旗艦手機在高階手機市場站穩腳跟,以往華為會在每年3/4月釋出P系列旗艦,在9/10月釋出Mate系列旗艦。但是直到今天華為P50系列還沒有釋出,讓不
2021-06-30 15:52:53