


作者 | 駱俊武 責編 | 歐陽姝黎整個系列側重於思考力的訓練,不僅僅是講清楚 What,而是更關注 Why 和 How,以幫助大家構建出牢固的知識體系。這是技術系列《吃透 MQ》的開
2021-07-01 03:07:11

整個系列側重於思考力的訓練,不僅僅是講清楚 What,而是更關注 Why 和 How,以幫助大家構建出牢固的知識體系。
這是技術系列《吃透 MQ》的開篇。本文主要講解 MQ 的通用知識,讓大家先弄明白:如果讓你來設計一個 MQ,該如何下手?需要考慮哪些問題?又有哪些技術挑戰?

有了這個基礎後,我相信後面幾篇文章再講 Kafka 和 RocketMQ 這兩種具體的訊息中介軟體時,大家能很快地抓住主脈絡,同時分辨出它們各自的特點。
對於 MQ 來說,不管是 RocketMQ、Kafka 還是其他訊息佇列,它們的本質都是:一發一存一消費。下面我們以這個本質作為根,一起由淺入深地聊聊 MQ。

從 MQ 的本質說起
將 MQ 掰開了揉碎了來看,都是「一發一存一消費」,再直白點就是一個「轉發器」。
生產者先將訊息投遞一個叫做「佇列」的容器中,然後再從這個容器中取出訊息,最後再轉發給消費者,僅此而已。

1、訊息:就是要傳輸的資料,可以是最簡單的文字字元串,也可以是自定義的複雜格式(只要能按預定格式解析出來即可)。
2、佇列:大家應該再熟悉不過了,是一種先進先出資料結構。它是存放訊息的容器,訊息從隊尾入隊,從隊頭出隊,入隊即發訊息的過程,出隊即收訊息的過程。
原始模型的進化 
再看今天我們最常用的訊息佇列產品(RocketMQ、Kafka 等等),你會發現:它們都在最原始的訊息模型上做了擴展,同時提出了一些新名詞,比如:主題(topic)、分區(partition)、佇列(queue)等等。
要徹底理解這些五花八門的新概念,我們化繁為簡,先從訊息模型的演進說起(道理好比:架構從來不是設計出來的,而是演進而來的)
最初的訊息佇列就是上一節講的原始模型,它是一個嚴格意義上的佇列(Queue)。訊息按照什麼順序寫進去,就按照什麼順序讀出來。不過,佇列沒有 「讀」 這個操作,讀就是出隊,從隊頭中 「刪除」 這個訊息。

這便是佇列模型:它允許多個生產者往同一個佇列傳送訊息。但是,如果有多個消費者,實際上是競爭的關係,也就是一條訊息只能被其中一個消費者接收到,讀完即被刪除。
如果需要將一份訊息資料分發給多個消費者,並且每個消費者都要求收到全量的訊息。很顯然,佇列模型無法滿足這個需求。
一個可行的方案是:為每個消費者創建一個單獨的佇列,讓生產者傳送多份。這種做法比較笨,而且同一份資料會被複制多份,也很浪費空間。
為了解決這個問題,就演化出了另外一種訊息模型:釋出-訂閱模型。

在釋出-訂閱模型中,存放訊息的容器變成了 「主題」,訂閱者在接收訊息之前需要先 「訂閱主題」。最終,每個訂閱者都可以收到同一個主題的全量訊息。
仔細對比下它和 「佇列模式」 的異同:生產者就是釋出者,佇列就是主題,消費者就是訂閱者,無本質區別。唯一的不同點在於:一份訊息資料是否可以被多次消費。
最後做個小結,上面兩種模型說白了就是:單播和廣播的區別。而且,當釋出-訂閱模型中只有 1 個訂閱者時,它和佇列模型就一樣了,因此在功能上是完全相容佇列模型的。
這也解釋了為什麼現代主流的 RocketMQ、Kafka 都是直接基於釋出-訂閱模型實現的?此外,RabbitMQ 中之所以有一個 Exchange 模組?其實也是為了解決訊息的投遞問題,可以變相實現釋出-訂閱模型。
包括大家接觸到的 「消費組」、「叢集消費」、「廣播消費」 這些概念,都和上面這兩種模型相關,以及在應用層面大家最常見的情形:組間廣播、組內單播,也屬於此範疇。
所以,先掌握一些共性的理論,對於大家再去學習各個訊息中介軟體的具體實現原理時,其實能更好地抓住本質,分清概念。

透過模型看 MQ 的應用場景
目前,MQ 的應用場景非常多,大家能倒背如流的是:系統解耦、非同步通訊和流量削峰。除此之外,還有延遲通知、最終一致性保證、順序訊息、流式處理等等。
那到底是先有訊息模型,還是先有應用場景呢?答案肯定是:先有應用場景(也就是先有問題),再有訊息模型,因為訊息模型只是解決方案的抽象而已。
MQ 經過 30 多年的發展,能從最原始的佇列模型發展到今天百花齊放的各種訊息中介軟體(平臺級的解決方案),我覺得萬變不離其宗,還是得益於:訊息模型的適配性很廣。
我們試著重新理解下訊息佇列的模型。它其實解決的是:生產者和消費者的通訊問題。那它對比 RPC 有什麼聯絡和區別呢?

1、引入 MQ 後,由之前的一次 RPC 變成了現在的兩次 RPC,而且生產者只跟佇列耦合,它根本無需知道消費者的存在。
2、多了一箇中間節點「佇列」進行訊息轉儲,相當於將同步變成了非同步。
再返過來思考 MQ 的所有應用場景,就不難理解 MQ 為什麼適用了?因為這些應用場景無外乎都利用了上面兩個特性。
舉一個實際例子,比如說電商業務中最常見的「訂單支付」場景:在訂單支付成功後,需要更新訂單狀態、更新使用者積分、通知商家有新訂單、更新推薦系統中的使用者畫像等等。

引入 MQ 後,訂單支付現在只需要關注它最重要的流程:更新訂單狀態即可。其他不重要的事情全部交給 MQ 來通知。這便是 MQ 解決的最核心的問題:系統解耦。
改造前訂單系統依賴 3 個外部系統,改造後僅僅依賴 MQ,而且後續業務再擴展(比如:營銷系統打算針對支付使用者獎勵優惠券),也不涉及訂單系統的修改,從而保證了核心流程的穩定性,降低了維護成本。
這個改造還帶來了另外一個好處:因為 MQ 的引入,更新使用者積分、通知商家、更新使用者畫像這些步驟全部變成了非同步執行,能減少訂單支付的整體耗時,提升訂單系統的吞吐量。這便是 MQ 的另一個典型應用場景:非同步通訊。
除此以外,由於佇列能轉儲訊息,對於超出系統承載能力的場景,可以用 MQ 作為 「漏斗」 進行限流保護,即所謂的流量削峰。
我們還可以利用佇列本身的順序性,來滿足訊息必須按順序投遞的場景;利用佇列 + 定時任務來實現訊息的延時消費 ……
MQ 其他的應用場景基本類似,都能迴歸到訊息模型的特性上,找到它適用的原因,這裡就不一一分析了。
總之,就是建議大家多從複雜多變的實踐場景再回歸到理論層面進行思考和抽象,這樣能吃得更透。

如何設計一個 MQ?
瞭解了上面這些理論知識以及應用場景後,下面我們再一起看下:到底如何設計一個 MQ?
我們還是先從簡單版的 MQ 入手,如果只是實現一個很粗糙的 MQ,完全不考慮生產環境的要求,該如何設計呢?
文章開頭說過,任何 MQ 無外乎:一發一存一消費,這是 MQ 最核心的功能需求。另外,從技術維度來看 MQ 的通訊模型,可以理解成:兩次 RPC + 訊息轉儲。
1、直接利用成熟的 RPC 框架(Dubbo 或者 Thrift),實現兩個介面:發訊息和讀訊息。
2、訊息放在本地記憶體中即可,資料結構可以用 JDK 自帶的 ArrayBlockingQueue 。
當然,我們的目標絕不止於一個 MQ 雛形,而是希望實現一個可用於生產環境的訊息中介軟體,那難度肯定就不是一個量級了,具體我們該如何下手呢?
1、高併發場景下,如何保證收發訊息的效能?
2、如何保證訊息服務的高可用和高可靠?
3、如何保證服務是可以水平任意擴展的?
4、如何保證訊息儲存也是水平可擴展的?
5、各種元資料(比如叢集中的各個節點、主題、消費關係等)如何管理,需不需要考慮資料的一致性?
可見,高併發場景下的三高問題在你設計一個 MQ 時都會遇到,「如何滿足高效能、高可靠等非功能性需求」才是這個問題的關鍵所在。
2、整體設計思路
先來看下整體架構,會涉及三類角色:

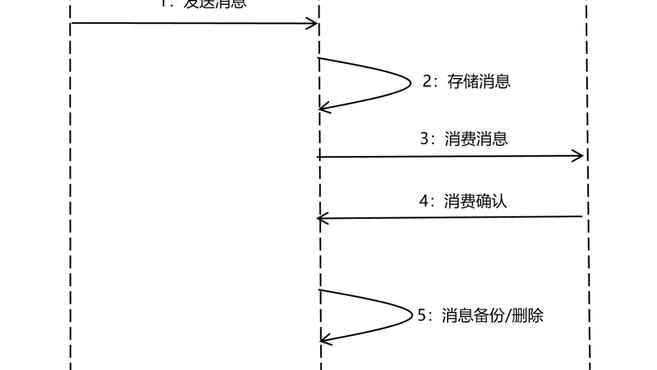
另外,將「一發一存一消費」這個核心流程進一步細化後,比較完整的資料流如下:

基於上面兩個圖,我們可以很快明確出 3 類角色的作用,分別如下:
1、Broker(服務端):MQ 中最核心的部分,是 MQ 的服務端,核心邏輯幾乎全在這裡,它為生產者和消費者提供 RPC 介面,負責訊息的儲存、備份和刪除,以及消費關係的維護等。
2、Producer(生產者):MQ 的客戶端之一,呼叫 Broker 提供的 RPC 介面傳送訊息。
3、Consumer(消費者):MQ 的另外一個客戶端,呼叫 Broker 提供的 RPC 介面接收訊息,同時完成消費確認。
難點1:RPC 通訊
解決的是 Broker 與 Producer 以及 Consumer 之間的通訊問題。如果不重複造輪子,直接利用成熟的 RPC 框架 Dubbo 或者 Thrift 實現即可,這樣不需要考慮服務註冊與發現、負載均衡、通訊協議、序列化方式等一系列問題了。
當然,你也可以基於 Netty 來做底層通訊,用 Zookeeper、Euraka 等來做註冊中心,然後自定義一套新的通訊協議(類似 Kafka),也可以基於 AMQP 這種標準化的 MQ 協議來做實現(類似 RabbitMQ)。對比直接用 RPC 框架,這種方案的定製化能力和優化空間更大。
難點2:高可用設計
高可用主要涉及兩方面:Broker 服務的高可用、儲存方案的高可用。可以拆開討論。
Broker 服務的高可用,只需要保證 Broker 可水平擴展進行叢集部署即可,進一步通過服務自動註冊與發現、負載均衡、超時重試機制、傳送和消費訊息時的 ack 機制來保證。
儲存方案的高可用有兩個思路:1)參考 Kafka 的分區 + 多副本模式,但是需要考慮分散式場景下資料複製和一致性方案(類似 Zab、Raft等協議),並實現自動故障轉移;2)還可以用主流的 DB、分散式檔案系統、帶持久化能力的 KV 系統,它們都有自己的高可用方案。
難點3:儲存設計
訊息的儲存方案是 MQ 的核心部分,可靠性保證已經在高可用設計中談過了,可靠性要求不高的話直接用記憶體或者分散式快取也可以。這裡重點說一下儲存的高效能如何保證?這個問題的決定因素在於儲存結構的設計。
目前主流的方案是:追加寫日誌檔案(資料部分) + 索引檔案的方式(很多主流的開源 MQ 都是這種方式),索引設計上可以考慮稠密索引或者稀疏索引,查詢訊息可以利用跳轉表、二分查詢等,還可以通過作業系統的頁快取、零拷貝等技術來提升磁碟檔案的讀寫效能。
如果不追求很高的效能,也可以考慮現成的分散式檔案系統、KV 儲存或者資料庫方案。
難點4:消費關係管理
為了支援釋出-訂閱的廣播模式,Broker 需要知道每個主題都有哪些 Consumer 訂閱了,基於這個關係進行訊息投遞。
由於 Broker 是叢集部署的,所以消費關係通常維護在公共儲存上,可以基於 Zookeeper、Apollo 等配置中心來管理以及進行變更通知。
難點5:高效能設計
儲存的高效能前面已經談過了,當然還可以從其他方面進一步優化效能。
比如 Reactor 網路 IO 模型、業務執行緒池的設計、生產端的批量傳送、Broker 端的非同步刷盤、消費端的批量拉取等等。
再總結下,要回答好:如何設計一個 MQ?
1、需要從功能性需求(收發訊息)和非功能性需求(高效能、高可用、高擴展等)兩方面入手。
2、功能性需求不是重點,能覆蓋 MQ 最基礎的功能即可,至於延時訊息、事務訊息、重試佇列等高階特性只是錦上添花的東西。
3、最核心的是:能結合功能性需求,理清楚整體的資料流,然後順著這個思路去考慮非功能性的訴求如何滿足,這才是技術難點所在。

寫在最後
這篇文章從 MQ 一發一存一消費這個本質出發,講解了訊息模型的演進過程,這是 MQ 最核心的理論基礎。基於此,大家也能更容易理解 MQ 的各種新名詞以及應用場景。
最後通過回答:如何設計一個 MQ?目的是讓大家對 MQ 的核心元件和技術難點有一個清晰的認識。另外,帶著這個問題的答案再去學習 Kafka、RocketMQ 等具體的訊息中介軟體時,也會更有側重點。
希望大家有所收穫,如果有任何意見和建議,歡迎評論區留言反饋!
相關文章
作者 | 駱俊武 責編 | 歐陽姝黎整個系列側重於思考力的訓練,不僅僅是講清楚 What,而是更關注 Why 和 How,以幫助大家構建出牢固的知識體系。這是技術系列《吃透 MQ》的開
2021-07-01 03:07:11

6月28日中國郵政宣佈提速,瞬間成為網際網路的熱點,快遞行業的唯一「國家隊」成員,它努力提高自己的服務質量無疑是讓業界矚目的,據悉它將在1000多個城市間提高配送速度,實現主要
2021-07-01 03:06:53

我做自媒體是高中時候的事情,那年的念高三,當時在一些眾測平臺中,申請體驗到了韶音的耳機。如果我沒記錯,那是我第一次體驗骨傳導耳機,當時還覺得蠻稀奇的,一個耳機會在耳朵裡邊迴
2021-07-01 03:06:39

#realme真我GT#realme GT大師版圖片與參數曝光,將搭載 1億畫素相機先前網路上傳出realme將推出一款「realme GT大師版」的訊息,當時除了這款手機可能依舊由知名日本工業設計師
2021-07-01 03:06:30

國產手機品牌近些年的發展非常迅速,從近幾年的銷量資料來看,國產「四巨頭」在全球市場已經獲得了相當不錯的市場份額,甚至超過了一些老牌手機巨頭;而國產手機品牌不僅在市場份額
2021-07-01 03:06:22

供應鏈最新訊息,蘋果今年的新機iPhone 13系列零部件供應商近期就要開始交貨了,即將進入量產階段。按照這個進度,再等兩個月暑假過完,9月份新機如期亮相應該比較穩妥了。所以,現在
2021-07-01 03:06:13