來源:資料STUDIO作者: 雲朵君導讀:在學習sklearn(機器學習)過程中,模型原理可謂是枯燥無味,加上大多數模型訓練過程也是不可見的,這使得很多小夥伴們望而卻步,當然也有很多學者試圖
2021-07-03 03:03:11
來源:資料STUDIO
作者: 雲朵君
導讀:在學習sklearn(機器學習)過程中,模型原理可謂是枯燥無味,加上大多數模型訓練過程也是不可見的,這使得很多小夥伴們望而卻步,當然也有很多學者試圖通過各種方式以視覺化模型學習及預測過程,但大多數是複雜且不美觀的。本文將給大家帶來一個福音。當機器學習遇到簡潔、強大且美觀的plotly視覺化庫時,可謂是強強聯手,從模型訓練、預測、決策邊界、殘差、交叉驗證、網格搜尋到模型評價,均可以很容易地可視化出來。

Plotly基本介紹
Plotly:協同 Python 和 matplotlib 工作的 web 繪相簿
Plotly 是一款用來做資料分析和視覺化的線上平臺,功能非常強大,可以線上繪製很多圖形比如條形圖、散點圖、餅圖、直方圖等等。而且還是支援線上編輯,以及多種語言python、javascript、matlab、R等許多API。
Plotly在Python中使用也很簡單,直接用pip install plotly就可以了。推薦最好在Jupyter notebook中使用,Pycharm操作不是很方便。
Plotly的圖表多樣化且專業化,可以繪製很多專業學科領域的圖表。下面是官網的幾種劃分。
基本圖表

基礎圖表

統計圖

科學圖

金融圖表
地圖

3D圖表

多子圖

與Jupyter互動圖

新增自定義控制項

人工智慧與機器學習圖

本文主要深入探討poltly與機器學習結合,繪製機器學習相關圖。注意:正文中繪圖程式碼僅展示部分核心程式碼,完整程式碼可聯絡原文作者雲朵君獲取!
Plotly Express 迴歸
這裡我們將一起學習如何使用plotly圖表來顯示各種類型的迴歸模型,從簡單的模型如線性迴歸,到其他機器學習模型如決策樹和多項式迴歸。
重點學習plotly的各種功能,如使用不同參數對同一模型進行比較分析、Latex顯示、3D表面圖,以及使用plotly Express進行增強的預測誤差分析。
Plotly Express 簡介
Plotly Express 是plotly的易於使用的高階介面,可處理多種類型的資料並生成易於樣式化的圖形。
通過Plotly Express 可以將普通最小二乘迴歸趨勢線新增到帶有trendline參數的散點圖中。為此需要安裝statsmodels及其依賴項。
基礎圖形: scatter, line, area, bar, funnel, timeline部分到整體圖表: pie, sunburst, treemap, funnel_area一維分佈圖: histogram, box, violin, strip二維分佈圖: density_heatmap, density_contour矩陣的輸入圖: imshow三維圖: scatter_3d, line_3d多維圖: scatter_matrix, parallel_coordinates, parallel_categories平鋪地圖: scatter_mapbox, line_mapbox, choropleth_mapbox, density_mapbox離線地圖: scatter_geo, line_geo, choropleth極座標圖: scatter_polar, line_polar, bar_polar三元圖: scatter_ternary, line_ternary
普通最小二乘迴歸視覺化
將線性普通最小二乘(OLS)迴歸趨勢線或非線性局部加權散點圖平滑(LOWESS)趨勢線新增到Python中的散點圖。將滑鼠懸停在趨勢線上將顯示該線的方程式及其R平方值,非常方便。
單線擬合
與seaborn類似,plotly圖表主題不需要單獨設定,使用預設參數即可滿足正常情況下的使用,因此一行程式碼並設定參數trendline="ols"即可搞定散點圖與擬合線的繪製,非常方便。
import plotly.express as pxfig=px.scatter(df, x="open", y="close", trendline="ols")fig.show()

多線擬合
同樣,在繪製多個變數及多個子圖時,也不需要設定多畫布,只要設定好參數 'x','y','facet_col','color' 即可。
fig=px.scatter(df,x="open",y="close",facet_col="Increase_Decrease", color="Up_Down", trendline="ols")fig.show()

檢視擬合結果
繪圖後,需要檢視具體的各項統計學資料,可以通過get_trendline_results方法,具體程式碼與結果如下。
results = px.get_trendline_results(fig)results.query( "Up_Down == 'Up' and Increase_Decrease == '1'" ).px_fit_results.iloc[0].summary()

非線性迴歸視覺化
非線性迴歸擬合是通過設定參數trendline="lowess"來實現,Lowess是指局部加權線性迴歸,它是一種非參數迴歸擬合的方式。
fig = px.scatter(df2, x="date", y="open", color="Increase_Decrease", trendline="lowess")fig.show()

Sklearn與Plotly組合
Scikit-learn是一個流行的機器學習(ML)庫,它提供了各種工具,用於創建和訓練機器學習演算法、特徵工程、資料清理以及評估和測試模型。
這裡使用Scikit-learn來分割和預處理我們的資料,並訓練各種迴歸模型。
線性迴歸視覺化
可以使用Scikit-learn的線性迴歸執行相同的預測。與直接用plotly.express擬合普通最小二乘迴歸不同,這是通過散點圖和擬合線組合的方式繪製圖形,這會更加靈活,除了新增普通線性迴歸擬合曲線,還可以組合其他線性迴歸曲線,即將擬合結果很好地可視化出來。
import plotly.graph_objects as gofrom sklearn.linear_model import LinearRegressionX = df.open.values.reshape(-1, 1)# 迴歸模型訓練model = LinearRegression()model.fit(X, df.close)# 生產預測點x_range = np.linspace(X.min(), X.max(), 100)y_range = model.predict(x_range.reshape(-1, 1))# 圖形繪製fig = px.scatter(df, x='open', y='close', opacity=0.65)fig.add_traces(go.Scatter(x=x_range, y=y_range, name='Regression Fit'))fig.show()

模型泛化能力視覺化
利用plotly視覺化檢視模型泛化能力,即需要比較模型分別在訓練集與測試集上的擬合狀況。這裡使用Scatter繪圖,可以通過用不同的顏色著色訓練和測試資料點,將訓練集與測試集資料及擬合線繪製在同一張畫布上,即可很容易地看到模型是否能很好地擬合測試資料。

KNN迴歸視覺化
KNN迴歸的原理是從訓練樣本中找到與新點在距離上最近的預定數量的幾個點,並從這些點中預測標籤。
KNN迴歸的一個簡單的實現是計算最近鄰K的數值目標的平均值。另一種方法是使用K近鄰的逆距離加權平均值。
from sklearn.neighbors import KNeighborsRegressor# 資料準備X = df2.open.values.reshape(-1, 1)x_range = np.linspace(X.min(), X.max(), 100)# 模型訓練,weights='distance'及weights='uniform'knn_dist = KNeighborsRegressor(10, weights='distance')knn_dist.fit(X, df2.Returns)y_dist = knn_dist.predict(x_range.reshape(-1, 1))# 繪製散點圖及擬合曲線fig = px.scatter(df2, x='open', y='Returns', color='Up_Down', opacity=0.65)fig.add_traces(go.Scatter(x=x_range, y=y_uni, name='Weights: Uniform'))# 'Weights: Distance'fig.show()

相關文章

來源:資料STUDIO作者: 雲朵君導讀:在學習sklearn(機器學習)過程中,模型原理可謂是枯燥無味,加上大多數模型訓練過程也是不可見的,這使得很多小夥伴們望而卻步,當然也有很多學者試圖
2021-07-03 03:03:11

機器之心報道編輯:杜偉、陳萍半個世紀後,MIT、石溪大學、康奈爾大學以及加州理工學院等機構的研究者通過觀測引力波證實了霍金的著名黑洞理論——面積定理,也是自在數學上證明
2021-07-03 03:02:59
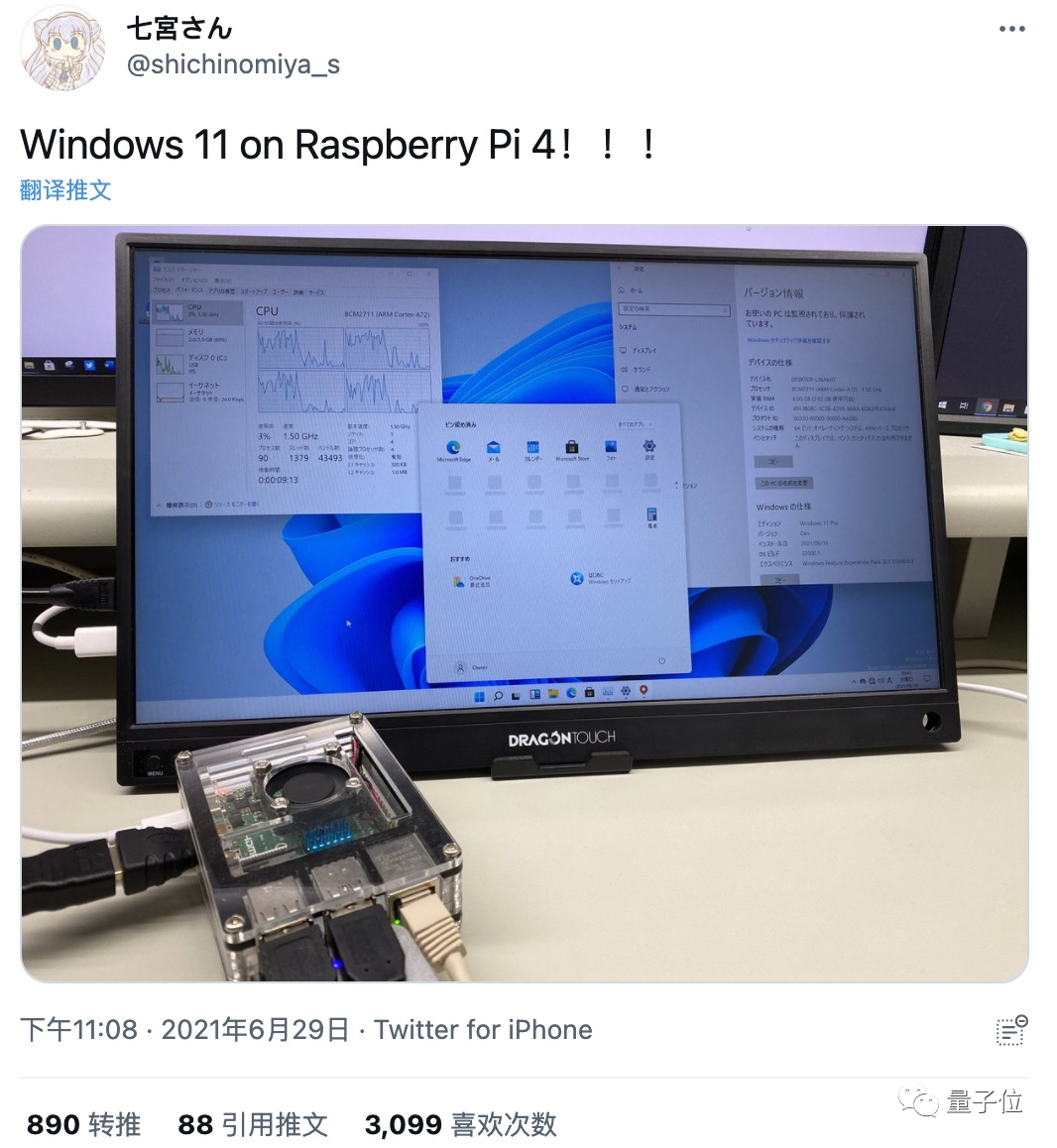
Windows 11才官宣不久,各家DIY達人就開始折騰起來了。不少人都已成功在樹莓派上運行Windows 11!圖片雖然此前微軟宣稱的Win 11硬體安裝要求非常多,不少人卻表示,在這小小的樹莓
2021-07-03 03:02:45
當我們使用計算機時,許多應用程式需要獲取要使用的麥克風功能。今天,小編與每個人共享計算機Win10系統如何禁止使用麥克風功能。如何使用麥克風設定我的近視應用程式?讓我們來
2021-07-03 03:02:35
出品|開源中國文|白開水微軟發出了一項倡議,旨在使 Visual Studio 的使用更加無障礙,讓殘疾人士和神經分化群體更容易使用該平臺。提議的功能包括:whitespace rendering、optio
2021-07-03 03:02:25

資源彙總Snailclimb / JavaGuide【Java學習+面試指南】 一份涵蓋大部分Java程式設計師所需要掌握的核心知識。doocs / advanced-java 網際網路 Java 工程師進階知識完全掃盲
2021-07-03 03:02:16