近年來,隨著圖結構資料場景的使用越來越廣泛,圖機器學習也受到了非常多的關注。如今,動輒億級節點或者百億級邊的規模資料挑戰正向社會襲來,可向超規模圖譜的圖機器學習研究更是少之又少。來自OPPO研究院資料智慧研究部的拓撲實驗室成員為此集結,在KDD Cup 2021中的MAG240M-LSC比賽中提出了能輕巧應對超大規模異構網路的MPLP方案,此方案不僅簡化了模型複雜度,而且具有很的擴展性。該項技術方案最終獲得了第四名的好成績,比賽相關技術檔和程式碼已經開源:https://github.com/qypeng-ustc/mplp
由於圖結構資料在各個場景中得到越來越多的應用,包括社交網路、推薦搜尋、知識圖譜、醫藥研發、量子物理等,圖機器學習受到了非常多的關注。另一方面,動輒億級節點或者百億級邊的大規模圖資料正逐漸帶來新的挑戰,而目前面向超大規模圖譜的圖機器學習研究較少。
2021年,斯坦福大學等相關的團隊在 KDD Cup 2021開展了大規模圖網路比賽,直擊當前圖學習研究的痛點。一方面 KDD (Knowledge Discovery and Data Mining)作為世界資料探勘領域最高級別的學術會議,吸引了全球頂尖研究機構前來展現「武功」,另一方面組織者斯坦福大學的Jure Leskovec領導的OGB團隊作為圖神經網路權威,其賽題質量自然也能夠保證。
https://ogb.stanford.edu/kddcup2021/
高質量的賽題加上優秀的競爭對手,角逐出來的技術方案備受業界關注。在節點預測賽道中,OPPO研究院資料智慧研究部的拓撲實驗室獲得了第四名的成績。如果細究其解決方案,可以發現OPPO提出的MPLP模型更加輕巧,計算開銷更小,也更具擴展性。
此次比賽的全稱是「OGB Large-Scale Challenge」,由 KDD Cup 2021和Open Graph Benchmark 官方聯合舉辦,全球共有500多個隊伍參賽。
比賽共釋出三個資料集,分別對應三個賽道。其中MAG240M-LSC是一個異構的學術圖,其任務是預測位於異構圖中的論文的學科類別;WikiKG90M-LSC是一個知識圖譜,其任務是估算缺少的三元組;PCQM4M-LSC是量子化學資料集,其任務是預測給定分子的重要分子特性。
對於每個資料集,賽事的組織者都經過精心的設計,以求參賽者在任務上提交的演算法能夠直接影響相應的應用。
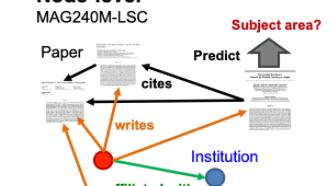
其中節點預測賽道中的MAG240M-LSC資料集是從Microsoft Academic Graph (MAG)中提取出的異構學術網路資料,總節點數244,160,499,總邊數1,728,364,232,包含有1.2億paper、1.2億author、2.6萬 institution三種類型節點以及cites、writes等邊類型,且paper的類別多達153種,壓縮的原始資料集167GB,是這次比賽中資料量最結構最複雜的任務。
基於以上,賽事主辦方給參賽者的任務是:設計模型,預測論文所屬的類別,準確率越高越好。比賽要求參賽者用2018年及之前的論文作為訓練集,2019年發表的論文作為驗證集,2020年的論文作為測試集。
此外,比賽僅有次最終提交機會,也在某種程度上增加了任務難度。
3月15日~6月8日,經過接近三個月的激烈競爭,主辦方根據準確率最終選出了六隻優勝隊伍,其中第一名的準確率是0.7549,第6名的準確率為0.7353,相差僅不到0.02。可以看出,頂級選手們的解決方案都非常優秀,在準確率方面差距並不大,只有綜合考慮計算開銷、模型複雜度才能看出誰能最大程度的適用工業場景。
排名第四的OPPO團隊提出的MPLP模型在所有靠前的解決方案中「最為輕巧」,演算法的兩個獨立部分來看:
1.對訓練和預測的節點,將標籤和特徵通過設定的元路徑(Metapath)進行聚合,可以實現高效的特徵預計算;
2.訓練一個多層MLP模型,模型參數不到百萬。
因此,模型的取樣僅涉及到訓練和預測樣本的2-hop鄰居,而且可以通過並行加速,標籤類特徵預生成部分僅需要2小時20分鐘(12個CPU),MLP模型完全放到GPU中訓練和推理,200個epoch只需要20分鐘。
而R-UniMP和APPNP等GNN模型,在單機多卡加速的情況下,單個模型訓練仍需要至少需要24小時。
在準確率方面和其他隊伍存在差距的原因是什麼呢?筆者通過與拓撲實驗室團隊的溝通中得知:
1.MPLP在特徵和標籤資訊提取方面選擇非常簡單的聚合式,不同於其他參賽隊伍選擇較複雜的圖卷積的做法;
2.由於時間有限,最終提交的模型只考慮了部分元路徑,同時考慮到過擬合問題,團隊基於對資料的理解和訓練效率考慮,刪除了部分元路徑;
3.MPLP非常簡單,在家都考慮到特徵傳遞和標籤傳播的情況下,表達能力略有不足。
換句話說,OPPO用微弱的準確率下降,換來了模型的簡潔性和計算開銷的節約。
MPLP模型,全稱「Metapath-based Label Propagation」,主要思路是通過結合不同異構元路徑(Metapath,MP)下的標籤傳播成的資訊輸出到下游分類器。對於節點分類任務來說,其框架如下:
其中H_emb為通過模型獲得的圖嵌特徵,H_pk·X表示在第K個MP上進特徵X傳播,Θ_k為參數(做維度變換)。在MPLP框架下,特徵和標籤在不同的MP下分別進傳播,之後將結果聚合起來輸送到下游分類模型中。
模型訓練分兩步,第步是在多種不同的MP上進標籤傳播,包括paper-writed_by-author-writes-paper、paper-cited_by-paper-cites-paper等,獲取不同MP下的標籤分佈資訊作為節點當前MP下的特徵;第步將所有MP獲得的特徵分別做空間對映後結合起來,輸到下游分類器進行分類預測。
如何將MPLP運用到節點預測任務中?由於比賽資料規模巨大,且資料中論文的主題分佈隨時間演化,加上論文分佈極其不均勻,部分主題的論數量只有幾十篇,而另外些主題的論文數達到幾萬篇。
針對上述三個難點,MPLP可以在不同的MP上預先進行標籤傳播,類似於SIGN和NARS方法,所以在規模和效率上具有天然的優勢;對於標籤分佈隨著時間演化問題,團隊採了類似遷移學習微調方法;對於類別不均衡,團隊定義了標籤權重方法,如下:
其中cnt_2018是維度為N_class=153的維向量,其每位表示在2018年相應主題的論文數量,超參α設定為5。
 MPLP模型下吸收不同特徵的實驗結果
MPLP模型下吸收不同特徵的實驗結果
上圖展示了在MPLP模型下吸收不同特徵的實驗結果,Valid Acc(weight)表示在當前模型中加類別weight的結果,括號內為未進行finetune。針對不同的模型,label代表不同MP下標籤Y傳播的資訊,feat代表不同MP下特徵X傳播的資訊,R-GAT和LINE-2nd表示相應預訓練模型的嵌特徵。考慮到模型複雜度和準確率表現,團隊最終採用了MPLP(label + R-GAT)方法。
與基準比較結果
為了抑制過擬合,團隊在訓練中採了5-fold交叉驗證的法,並進步的取樣8個不同的隨機種子來初始化模型,最終的預測結果來自40個模型的ensemble。並且,通過將資料集往前推1年,將2018年資料作為驗證集,將2019年資料作為測試集,驗證了這種整合方式的有效性。MPLP和其他較強的baseline比較結果如上圖所示。
KDD Cup全稱為國際知識發現和資料探勘競賽,自1997年開始,由ACM協會SIGKDD分會每年舉辦一次,目前是全球資料探勘領域最有影響力的賽事,其所設比賽題目具有相當高的實際意義和商業價值。
OPPO拓撲實驗室成立僅一年,專門從事圖學習研究。目前在團隊規模、技術積累、研發投入等方面仍處於初級階段。拓撲實驗室表示,這種將深度學習和圖論相結合處理圖結構資料的方法,既保留了深度學習的優勢,又拓展了其應用邊界,與當前OPPO面向的落地場景十分契合。
通過這場賽事,OPPO拓撲實驗室證明了自己在圖網路方面的研究成果,也首次在國際平臺展現了不俗的技術實力。其實從更大範圍來講,這場比賽不僅對於所有參賽機構來說是更加公平可信的競技場,也是引導學術界走向超大規模圖譜研究的契機。
ImageNet毋庸置疑推動了計算機視覺的發展,而OGB-LSC已經展現了圖學習發展的一個趨勢:技術方向從「真空」學術研究轉向實際工業場景。畢竟,任何前沿技術研發都是為產業化應用服務的。在學術界,雖然圖神經網路的論文越來越多,但這些實驗方法與現實場景的應用仍相距甚遠,很多論文所使用的實驗資料,與工業界真實場景的資料差距非常大,導致很多實驗效果在現實場景中無法復現。
拓撲實驗室團隊表示,這次比賽所使用的三個資料集是基於真實場景的超大規模圖譜資料,具有相當的權威性,通過這些資料所獲得的實驗結果和成績也更能讓人信服。
深度學習方法被應用在提取歐氏空間資料的特徵方面取得了巨大的成功,但許多實際應用場景中的資料是從非歐式空間生成的,傳統的深度學習方法在處理非歐式空間資料上的表現卻仍難以使人滿意。
最近幾年,研究人員結合傳統深度學習和圖論,設計了用於處理圖資料的圖學習技術,並進入一個爆發式的增長階段。通過學術界和工業界的共同努力,圖學習技術已經被成功應用到安全風控、搜尋推薦、姿態估計和知識圖譜等實際應用場景,並達到一定的成熟度;同時研究人員也在探索更多的應用場景,比如:因果推理。通過對新技術的長期探索和應用,幫助產品和服務提升使用者體驗,對OPPO至關重要,也是OPPO品牌信仰「科技為人,以善天下」的內在詮釋。
值得一提的是,圖演算法呈現的「結構化知識+跨領域」的特徵,正好與清華大學的張鈸院士提出的以「知識+資料雙輪驅動」為核心的第三代人工智慧不謀而合。作為最具潛力的新型技術路線之一,圖網路除了基礎理論方面的創新外,更重要的是拓展更多的應用場景。不過,二者的關係是相輔相成的——有了理論上的突破,圖神經網路的效果才能更強大。未來拓撲實驗室將面向安全風控、搜尋推薦等現實場景在圖演算法研究方面投入更多,加速致善式創新。








 MPLP模型下吸收不同特徵的實驗結果
MPLP模型下吸收不同特徵的實驗結果 與基準比較結果
與基準比較結果