來源:資料STUDIO作者:雲朵君導讀:大家好,我是雲朵君!自從分享了一篇能夠寫在簡歷裡的企業級資料探勘實戰項目,深受讀者朋友們青睞,許多讀者私信雲朵君,希望多一些類似的資料探勘實際
2021-07-06 03:03:35
來源:資料STUDIO
作者:雲朵君
導讀:大家好,我是雲朵君!自從分享了一篇能夠寫在簡歷裡的企業級資料探勘實戰項目,深受讀者朋友們青睞,許多讀者私信雲朵君,希望多一些類似的資料探勘實際案例。這就來了。
本項目旨在探討影響學生學業表現的人口統計學和家庭特徵。本項目中,使用多種不平衡資料處理方法以及各種分類器,如決策樹,邏輯迴歸,k近鄰,隨機森林和多層感知器的分類機器。

資料集描述
本案例資料集來自Balochistan的6000名學生。其基本情況:一共13個欄位,其中RESULT為結果標籤;語言欄位是經過獨熱編碼後的四個欄位,分別為Lang1, Lang2, Lang3, Lang4;
另外性別、學校、是否殘疾、宗教信仰四個欄位為二分類離散欄位;
其餘如兄弟姐妹、在校兄弟姐妹數量為連續性變數。
本次資料為清洗過後"乾淨"資料,可以直接輸入到機器學習模型中直接建模使用。
欄位說明如下表所示

資料樣例

探索性資料分析
探索性資料分析有多種方法,這裡直接通過繪製柱狀圖檢視每個欄位的分佈狀況。
從資料集特點來看,13個欄位可以分為四大類。
結果標籤離散型變數連續型變數啞變數結果標籤
考試結果為PASS的共有4562名學生,而結果為FAIL的共有1047名學生,從下圖中也可以明顯看出,該樣本為不平衡資料集,因此本次案例重點在於不平衡資料分類方法。

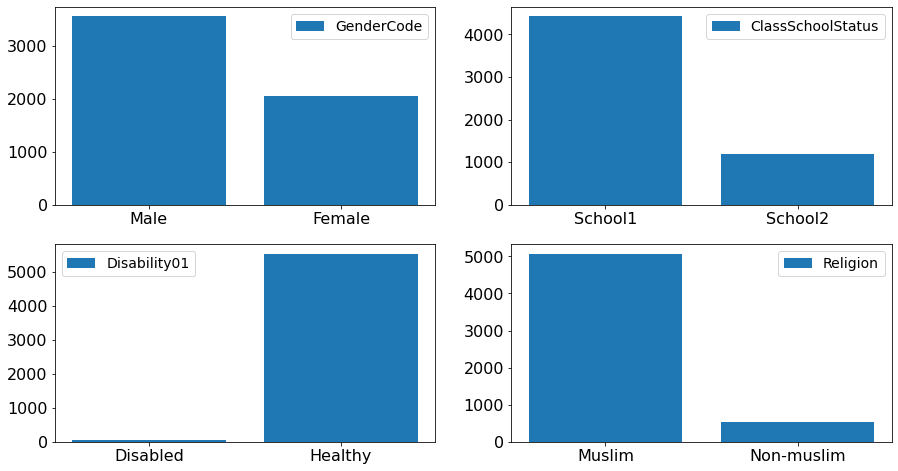
離散型變數
性別有男女,學校有學校1和學校2,身體健康狀況有是否殘疾,宗教信仰分是否是穆斯林。

連續型變數
本次資料集中兄弟姐妹數量及在校兄弟姐妹數量分佈情況可以由下面四張分佈圖很好地展示出來。
大部分學生家中的兄弟姐妹有2-4個大部分學生家中的姐妹都不是在校生大部分學生家中的兄弟中也只有1-2個是在校生

啞變數
本次資料集共有四種語言,其數量分佈由下圖所示。接近一半的學生都是說的一種語言(Lang1)。

不平衡資料集處理方法
從上一步的探索性資料分析結果,本次學生成績資料集為不平衡資料集,那麼處理不平衡資料集處理方法都有哪些呢。
在本文雲朵君從三個方面總結了多種處理方法,見下面思維導圖。

資料重取樣
這裡主要介紹下資料預處理層面的資料重取樣方法。資料重取樣主要分為上取樣和下采樣。
下采樣,也稱為欠取樣(Under-Sampling),是一個為平衡資料類分佈的移除大類資料的非啟發式的方法。此方法的底層邏輯是平衡資料集進而克服演算法的特異性。
常用的方法有隨機欠取樣(Random Under-Sampling, RUS),即隨機排除大類的觀察值,和聚焦欠取樣(Focused Under-Sampling, FUS), 即移除兩類邊界處的大類資料。
上取樣,也稱為過取樣(Over-Samplig),是通過複製小類觀察值,從而增加小類比例的一個方法。類似的,過取樣也有隨機過取樣和聚焦過取樣兩種方法。
 來源:kaggle
來源:kaggle上取樣
過取樣代表SMOTE方法,其主要概念也就是在少數樣本位置近的地方,人工合成一些樣本,整個演算法的流程如下:
設定一個取樣倍率N,也就是對每個樣本需要生成幾個合成樣本設定一個近鄰值K ,針對該樣本找出K 個最近鄰樣本並從中隨機選一個根據以下公式來創造 N 個樣本下采樣
相對於過取樣,欠取樣是將多數樣本按比例減少,使得模型的加權權重改變,少考慮一些多數樣本,上圖很好地展示了兩種方法的差異 。
Tomek Link 演算法
會針對所有樣本去遍歷一次,如有兩個樣本點x, y分屬不同的class,即一個為多數樣本而另一個為少數樣本,則可以去計算它們之間的距離d(x , y) 。
此時如果找不到第三個樣本點z,使得任一樣本點到z 的距離比樣本點之間的距離還小,則稱為Tomek Link,一張圖幫助理解 :
 來源:Kaggle
來源:KaggleTomek Link 的關鍵思路在於,找出邊界那些鑑別度不高的樣本,認為這些樣本點屬於雜訊,應該剔除,因此可以見上圖最右邊,剔除以後兩種類別的樣本點可以更好地區分開來。
ENN演算法(Edited Nearest Neighbor)
與上面Tomek Links的觀念相同,ENN演算法也是透過某種方式來剔除鑑別度低的樣本,只是這邊的方式改成了對多數類的樣本尋找K個近鄰點,如果有一半以上(當然,門檻可以自己設定)都不屬於多數樣本,就將該樣本剔除,通常這些樣本也會出現在少數樣本之中。
混合取樣
SMOTE + ENN、SMOTE + Tomek Links演算法都是結合過取樣與欠取樣演算法SMOTEENN使用 SMOTE 進行過取樣,然後使用 Edited Nearest Neighbours 進行欠取樣。
SMOTETomek使用 SMOTE 進行過取樣,然後使用 Tomek Links 進行欠取樣。
不平衡資料集處理方法選擇
控制變數法選擇合適的處理方法。選用決策樹為基分類器,並分別選擇不使用資料重取樣,使用SMOTE、SMOTEENN和SMOTETomek共三種資料重取樣方法,比較這四種情況下的模型評價指標AUC得分情況。
最後分別選用五種不同分類器,且分別採用不同的資料重取樣方法,繪製ROC曲線及得到的AUC得分情況。
ROC和AUC
ROC曲線繪製採用不同分類閾值的TPR和FPR,降低分類閾值會將更多的樣本判為正類別,從而增加FP和TP的個數。為了繪製ROC曲線,需要使用不同的分類閾值多次評估迴歸模型,很麻煩。有一種基於排序的高效演算法可以為我們提供此類資訊,這種演算法稱為曲線下的面積(AUV,area under roc curve)。
ROC曲線的橫軸為FPR,越低越好,縱軸為TPR,越高越好,故如果有兩個不同的模型,曲線位於左上方的模型優於曲線位於右下方的模型,這一點可以拿曲線的面積(AUV)來量化。
完美的分類為TPR=1,FPR=0;ROC曲線過(0,0)和(1,1)點
AUC = 1,是完美分類器,採用這個預測模型時,不管設定什麼閾值都能得出完美預測。絕大多數預測的場合,不存在完美分類器。0.5 < AUC < 1,優於隨機猜測。這個分類器(模型)妥善設定閾值的話,能有預測價值。AUC = 0.5,跟隨機猜測一樣(例:丟銅板),模型沒有預測價值。AUC < 0.5,比隨機猜測還差;但只要總是反預測而行,就優於隨機猜測。AUC計算的物理意義為:任取一對(正、負)樣本,正樣本的score大於負樣本的score的概率,也即是隨機正類別樣本位於隨機負類別樣本右側的概率。
核心程式碼
將所有主要方法定義為函數,包括資料重取樣、劃分測試集和訓練集、模型訓練、模型評價和結果視覺化。
此外,由於是比較不平衡資料集處理方法選擇的優劣,這裡所有的機器學習模型都採用預設參數。
def reSampler(X, y, samp):"""不同的資料重取樣策略""" if(samp == 'None'): return splitter(X, y, 0.1) if(samp == 'SMOTE'): sm = SMOTE('auto', 42) X_resampled , y_resampled = sm.fit_resample(X, Y) return splitter(X_resampled , y_resampled, 0.1) if(samp == 'SMOTEENN'): sm = SMOTEENN() X_resampled , y_resampled = sm.fit_resample(X, Y) return splitter(X_resampled , y_resampled, 0.1) if(samp == 'SMOTETomek'): sm = SMOTEENN() X_resampled , y_resampled = sm.fit_resample(X, Y) return splitter(X_resampled , y_resampled, 0.1)def splitter(X, y, test_Size): """劃分測試集和訓練集""" xtrain, xtest, ytrain, ytest = train_test_split( X, y, test_size = test_Size, random_state=12) return xtrain, xtest, ytrain, ytestdef rocPlotter(actu, pred, clf, samp): """AUC曲線繪圖函數""" false_positive_rate, true_positive_rate, thresholds = roc_curve(actu, pred) roc_auc = auc(false_positive_rate, true_positive_rate) Title = str('ROC: ' + str(clf) + ' using ' + str(samp)) plt.title(Title) plt.plot(false_positive_rate, true_positive_rate, 'b', label='AUC = %0.2f'% roc_auc) plt.legend(loc='lower right') plt.plot([0,1],[0,1],'r--') plt.xlim([-0.1,1.2]) plt.ylim([-0.1,1.2]) plt.ylabel('True Positive Rate') plt.xlabel('False Positive Rate') plt.show() return roc_aucdef applyModel(clfr, X_, y_, xt, yt): """使用模型""" a = globals()[clfr]() a.fit(X_, y_) scor = a.score(xt, yt)*100 pred = a.predict(xt) actu = yt return pred, actu, scordef tryAll(clfList, sampList, Inputs, Outputs): """主函數""" rep = np.zeros( (len(clfList), len(sampList)), dtype=float) for clf, clfIndex in zip(clfList, range(len(clfList))): # 不同的分類器 for samp, sampIndex in zip(sampList, range(len(sampList))): # 不同的重取樣策略 X_train, X_test, Y_train, Y_test = reSampler(Inputs, Outputs, samp) prediction , actual, score =applyModel( clf, X_train, Y_train, X_test, Y_test) currentAUC = rocPlotter( prediction, actual, clf, samp) print(clf, ' with ', samp, ' scored = ', score, ' on test set with AUC = ', currentAUC) rep[clfIndex, sampIndex] = currentAUC return rep
函數執行
Classifiers = ['DecisionTreeClassifier', 'KNeighborsClassifier', 'LogisticRegression', 'MLPClassifier', 'RandomForestClassifier']Samplers = ['None', 'SMOTE', 'SMOTETomek', 'SMOTEENN']report = tryAll(Classifiers, Samplers, X, Y)
結果視覺化
下面以單個模型四種不同重取樣策略,和五種模型單個重取樣策略為例展示視覺化結果。大家可以運行上述程式碼以得到完整的結果展示。
決策樹模型在四種不同重取樣策略下,得到的四種不同的結果。很明顯地看到沒有使用資料重取樣的模型得分最差只有0.54,而使用混合取樣演算法的兩個結果的得分都比較理想,分別是0.973275和0.979196分。

接下來以上述結果中得分最高的混合取樣演算法SMOTETomek為例,將不平衡資料集經過SMOTETomek演算法處理後,分別用
DecisionTreeClassifier決策樹分類器,KNeighborsClassifierK近鄰分類器,LogisticRegression邏輯迴歸,MLPClassifier多層感知機,RandomForestClassifier隨機森林分類器 五種機器學習模型訓練和測試資料,並得到如下結果。
從結果可知道,並不是所有模型在使用混合取樣演算法SMOTETomek後都能達到令人滿意的效果。

結果彙總
為方便檢視所有結果,將所模型、所有重取樣方法彙總到如下圖所示的DataFrame中。從AUC結果看,使用混合取樣演算法SMOTEENN對資料集處理,並使用決策樹模型對結果進行預測,將會得到最佳預測效果。其AUC=0.979。
pd.DataFrame(report, columns = Samplers, index = Classifiers)

交叉驗證
上節中選用五種不同分類器,三種不同的資料重取樣方法,結合ROC曲線及AUC得分情況來確定重取樣方法對選擇。
本節可以理解為是上節的拓展。
核心程式碼
# 例項化五種分類器模型dTree = DecisionTreeClassifier() logReg = LogisticRegression()knn = KNeighborsClassifier(n_neighbors=5)rF = RandomForestClassifier()MLP = MLPClassifier()# 例項化十種資料重取樣模型rmun = RandomUnderSampler()cnn = CondensedNearestNeighbour()nm = NearMiss()enn = EditedNearestNeighbours()renn = RepeatedEditedNearestNeighbours()tkLink = TomekLinks()rmov = RandomOverSampler()sm = SMOTE()sm_en = SMOTEENN()sm_tk = SMOTETomek()# 以SMOTEENN取樣方法為例sm_en = SMOTEENN()X_resampled, Y_resampled = sm_en.fit_resample(X, Y)# 分別使用10折交叉驗證的方法得到平均得分scores_dTree = cross_val_score(dTree, X_resampled, Y_resampled, cv = 10, scoring='roc_auc')scores_dTree = scores_dTree.mean()# 打印出每次的結果print('After appling SMOTENN: ')print(' dTree, logReg , KNN , rF , MLP')print(scores_dTree, scores_logReg, scores_knn, scores_rF, scores_MLP)將所有結果儲存在一個DataFrame裡Classifiers = ['DecisionTreeClassifier', 'LogisticRegression', 'KNeighborsClassifier', 'RandomForestClassifier', 'MLPClassifier']Samplers = ['None','Random Undersampling', 'CNN', 'NearMiss', 'ENN', 'RENN','Tomek Links','SMOTE', 'Random Oversampling', 'SMOTEENN','SMOTETomek']pd.DataFrame(report, columns = Samplers, index = Classifiers)

並用熱圖視覺化更加直觀地展示出結果來import seaborn as snsplt.figure()ax = sns.heatmap(report,xticklabels=Samplers, yticklabels=Classifiers, annot = True, vmin=0, vmax=1, linewidth=0.1, cmap="YlGnBu",)

從熱圖的特性可以看出,藍色越深,模型效果越好。本案例中可以得到如下幾個結論
隨機森林分類器在使用RENN及SMOTEENN重取樣處理後的資料時,模型效果均比較理想,AUC得分分別為0.94和0.98採用SMOTEENN重取樣處理後的資料,在所有模型中均表現良好,其次是RENN重取樣策略隨機下采樣,CNN及NearMiss等取樣策略效果並不明顯邏輯迴歸模型對於所有的取樣策略均不敏感本例採用的來自Balochistan的6000名學生不平衡資料集。本項目旨在探討影響學生學業表現的人口統計學和家庭特徵。
本例使用清洗後的資料集,以探索資料變數的分佈特徵開篇,重點介紹了資料不平衡處理的各種方法,以及演示如何通過交叉驗證方法選擇合適的資料不平衡處理以及選擇合適的機器學習分類模型。
本文後續工作可以是通過正文中得到的結果,選擇幾個合適的模型,通過適當的模型調參方法選擇恰當的參數,以確定本次資料探勘的最終模型。
相關文章
來源:資料STUDIO作者:雲朵君導讀:大家好,我是雲朵君!自從分享了一篇能夠寫在簡歷裡的企業級資料探勘實戰項目,深受讀者朋友們青睞,許多讀者私信雲朵君,希望多一些類似的資料探勘實際
2021-07-06 03:03:35

機器之心報道機器之心編輯部IEEE 獎項委員會公佈了 2022「IEEE 技術領域獎」的名單。又到了 IEEE 集中頒發榮譽的時間。7 月 2 日,國際電氣電子工程師學會 IEEE 的獎項委員會
2021-07-06 03:03:26

楊淨 子豪 發自 凹非寺量子位 報道 | 公眾號 QbitAI我也是沒想到,AI換臉能以這種方式出圈。PDD、大司馬、智勳等一眾電競圈網紅們,集體上頭「辣舞」,還是秀肌肉的那種。畫風是
2021-07-06 03:02:35

如今,基於開源軟體的商業模式席捲全球,國內外陸續湧現出不少成功的創業案例,比如已經上市的 MongoDB、Elastic,國內屢獲資本青睞的 PingCAP、濤思資料等。此外,很多頭部的大廠近
2021-07-06 03:02:14

知名應用被通報據昨天晚上最新訊息表示,接大量使用者的舉報,經過國家網際網路資訊辦公室的核實,中國知名的網約車應用「滴滴出行」因為存在嚴重違法違規收集使用個人資訊問題被
2021-07-06 03:02:02

如今已經進入2021年下半年了,很多手機品牌也開始為下半年準備釋出新機了,下半年手機競爭更加激烈,更加熱鬧了,除了蘋果釋出iPhone13系列外,還有小米MIX4、華為P50系列和三星Note2
2021-07-06 03:01:57