選自arXiv作者:Zhenda Xie等機器之心編譯機器之心編輯部來自清華大學、西安交大、微軟亞研的研究者提出了一種稱為 MoBY 的自監督學習方法,其中以 Vision Transformer 作為其
2021-07-08 03:02:51
選自arXiv
作者:Zhenda Xie等
機器之心編譯
機器之心編輯部
來自清華大學、西安交大、微軟亞研的研究者提出了一種稱為 MoBY 的自監督學習方法,其中以 Vision Transformer 作為其主幹架構,將 MoCo v2 和 BYOL 結合,並在 ImageNet-1K 線性評估中獲得相當高的準確率,效能優於 MoCo v3、DINO 等網路。
近兩年來,計算機視覺領域經歷了兩次重大轉變,第一次是由 MoCo(Momentum Contrast)開創的自監督視覺表徵學習,其預訓練模型經過微調可以遷移到不同的任務上;第二次是基於 Transformer 的主幹架構,近年來在自然語言處理中取得巨大成功的 Transformer 又在計算機視覺領域得到了探索,進而產生了從 CNN 到 Transformer 的建模轉變。
不久前,微軟亞研的研究者提出了一種通過移動視窗(shifted windows)計算的分層視覺 Swin Transformer,它可以用作計算機視覺的通用主幹網路。在各類迴歸任務、影象分類、目標檢測、語義分割等方面具有極強效能。
而在近日,來自清華大學、西安交通大學以及微軟亞洲研究院的研究者也在計算機視覺領域發力,提出了名為 MoBY 自監督學習方法,以 Vision Transformers 作為其主幹架構,將 MoCo v2 和 BYOL 結合在一起,在 ImageNet-1K 線性評估中獲得相當高的準確率:通過 300-epoch 訓練,分別在 DeiT-S 和 Swin-T 獲得 72.8% 和 75.0% 的 top-1 準確率。與使用 DeiT 作為主幹的 MoCo v3 和 DINO 相比,效能略好,但trick要輕得多。
更重要的是,使用 Swin Transformer 作為主幹架構,還能夠評估下游任務中(目標檢測和語義分割等)的學習表徵,其與最近的 ViT/DeiT 方法相比,由於 ViT / DeiT 不適合這些密集的預測任務,因此僅在 ImageNet-1K 上報告線性評估結果。研究者希望該結果可以促進對 Transformer 架構設計的自監督學習方法進行更全面的評估。

論文地址:https://arxiv.org/pdf/2105.04553.pdfGitHub 地址:https://github.com/SwinTransformer/Transformer-SSL
方法介紹
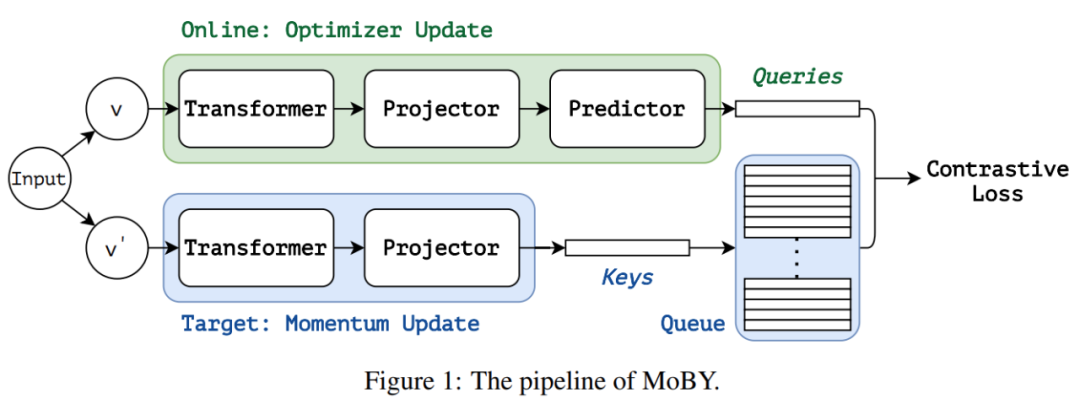
自監督學習方法 MoBY 由 MoCo v2 和 BYOL 這兩個比較流行的自監督學習方法組成,MoBY 名字的由來是各取了 MoCo v2 和 BYOL 前兩個字母。MoBY 繼承了 MoCo v2 中的動量設計、鍵佇列、對比損失,此外 MoBY 還繼承了 BYOL 中非對稱編碼器、非對稱資料擴充、動量排程(momentum scheduler)。MoBY 架構圖如下圖 1 所示:

MoBY 包含兩個編碼器:線上編碼器和目標編碼器。這兩個編碼器都包含一個主幹和 projector head(2 層 MLP),線上編碼器引入了額外的預測頭(2 層 MLP),使得這兩個編碼器具有非對稱性。線上編碼器採用梯度更新,目標編碼器則是線上編碼器在每次訓練迭代中通過動量更新得到的移動平均值。對目標編碼器採用逐漸增加動量更新策略:訓練過程中,動量項值預設起始值為 0.99,並逐漸增加到 1。
學習表徵採用對比損失,具體而言,對於一個線上檢視(online view)q,其對比損失計算公式如下所示:

式中,κ_+ 為同一幅影象的另一個檢視(view)的目標特徵;κ_i 是鍵佇列( key queue )中的目標特性;τ是 temperature 項;Κ是鍵佇列的大小(預設為 4096)。
在訓練中,與大多數基於 Transformer 的方法一樣,研究者還採用了 AdamW 優化器。
MoBY 虛擬碼如下所示:

實驗
在 ImageNet-1K 上的線性評估
在 ImageNet-1K 資料集上進行線性評估是一種常用的評估學得的表徵質量的方式。在該方式中,線性分類器被用於主幹,主幹權重被凍結,僅訓練線性分類器。訓練完線性分類器之後,使用中心裁剪(center crop)在驗證集上取得了 top-1 準確率。
表 1 給出了使用各種自監督學習方法和主幹網路架構的預訓練模型的主要效能結果。

1.與使用 Transformer 架構的其他 SSL 方法進行比較
MoCo v3、DINO 等方法採用 ViT/DeiT 作為主幹網路架構,該研究首先給出了使用 DeiT-S 的 MoBY 的效能結果,以便與該研究的方法進行合理比較。經過了 300 個 epoch 的訓練,MoBY 達到了 72.8% top-1 的準確率,這比 MoCo v3 和 DINO(不含多次裁剪(multi-crop))略勝一籌,結果如表 1 所示。
2.Swin-T VS DeiT-S
研究者還比較了在自監督學習中各種 Transformer 架構的使用情況。如表 1 所示,Swin-T 達到了 75.0% top-1 的準確率,比 DeiT-S 高出 2.2%。值得一提的是,這一效能差距比使用監督學習還大(+1.5%)。
該研究進行的初步探索表明,固定 patch 嵌入對 MoBY 沒有用,並且在 MLP 塊之前用批歸一化代替層歸一化層可以讓 top-1 準確率提升 1.1%(訓練 epoch 為 100),如表 2 所示。

在下游任務上的遷移效能
研究者評估了學得的表徵在 COCO 目標檢測 / 例項分割和 ADE20K 語義分割的下游任務上的遷移效能。
1.COCO 目標檢測和例項分割
評估中採用了兩個檢測器:Mask R-CNN 和 Cascade Mask R-CNN。表 3 給出了在 1x 和 3x 設定下由 MoBY 學得的表徵和預訓練監督方法的比較結果。

2.ADE20K 語義分割
研究者採用 UPerNet 方法和 ADE20K 資料集進行評估。表 4 給出了監督和自監督預訓練模型的比較結果。這表明 MoBY 的效能比監督方法稍差一點,這意味著使用 Transformer 架構進行自監督學習具有改進空間。

消融實驗
研究者又進一步使用 ImageNet-1K 線性評估進行了消融實驗,其中 Swin-T 為主幹網路架構。
1.不對稱的 drop path rate 是有益的
對於使用影象分類任務和 Transformer 架構的監督表徵學習來說,drop path 是一種有效的正則化方法。研究者通過消融實驗探究了該正則化方法的影響,實驗結果如下表 5 所示。

2.其他超參數
第一組消融實驗探究了鍵佇列大小 K 從 1024 到 16384 的影響,實驗結果如表 6(a) 所示。該方法在不同 K(從 1024 到 16384)下都能夠穩定執行,其中採用 4096 作為預設值。
第二組消融實驗探究了溫度(temperature)τ的影響,實驗結果如表 6(b) 所示。其中τ為 0.2 時效能最佳,0.2 也是預設值。
第三組消融實驗探究了目標編碼器的初始動量值的影響,實驗結果如表 6(c) 所示。其中值為 0.99 時效能最佳,並被設為預設值。

相關文章
選自arXiv作者:Zhenda Xie等機器之心編譯機器之心編輯部來自清華大學、西安交大、微軟亞研的研究者提出了一種稱為 MoBY 的自監督學習方法,其中以 Vision Transformer 作為其
2021-07-08 03:02:51

明敏 魚羊 發自 凹非寺量子位 報道 | 公眾號 QbitAI我也是萬萬沒想到,風傳已久的新款switch就這麼突然出現,還被玩家們吐槽上了熱搜。無論是微博知乎,還是推特臉書,中英日各國文
2021-07-08 03:02:38

一、為什麼需要Docker可能每個開發人員都有一種困擾,軟體開發完之後部署項目,明明測試環境部署了一點問題沒有,怎麼一到正式環境就出錯呢?這種情況有時候問題可能就出在環境配置
2021-07-08 03:02:20

新款 Switch 釋出作為目前銷量和知名度最高的遊戲掌機,任天堂 Switch 已經推出四年多,其配置已經算是非常低下了,效能和螢幕經常被使用者吐槽。不過就算是這樣,Switch 依然壟斷
2021-07-08 03:02:11

如今手機行業已經進入2021年下半場,而每年手機行業最熱鬧的還是下半年,今年下半年有蘋果iPhone13系列、三星Note21系列、小米MIX4系列,如今又曝光的vivo X70,同樣是在下半年釋出
2021-07-08 03:02:05

【7月7日訊】相信大家都知道,自從國產手機老大哥華為遭受到重創以後,全球智慧手機市場也再次迎來了大洗牌,在華為手機業務巔峰時期,全球銷量更是突破了兩億臺大關,中海外市場銷量
2021-07-08 03:02:00