英偉達GPU在AI領域的成功引來了大量的挑戰者。在國外,雲端晶片初創公司幾乎都採用DSA(Domain Specific Architecture,領域專用架構)挑戰英偉達,比如已經被英特爾收購的Habana Lab
2021-07-13 03:05:19
英偉達GPU在AI領域的成功引來了大量的挑戰者。在國外,雲端晶片初創公司幾乎都採用DSA(Domain Specific Architecture,領域專用架構)挑戰英偉達,比如已經被英特爾收購的Habana Labs。在國內,也有多家初創公司用GPGPU的架構研發AI雲端晶片。
「用相同的架構競爭,專利就是一個問題。DSA是不同的道路,特別在雲端AI推理方面,DSA可以完勝GPU。」 瀚博半導體創始人兼CEO錢軍解釋了創業前的技術路線思考。
雷鋒網此前的文章介紹過,錢軍有25年以上高階晶片設計經驗,離職前在AMD任Senior Director,全面負責GPU(影象處理器)和AI伺服器晶片設計和生產,現在市場上的AMD Radeon影象處理器和AI伺服器晶片都是由其帶隊開發。

瀚博半導體創始人兼CEO錢軍
瀚博的另一個創始人,也是CTO和總架構師的張磊有23年以上晶片和IP架構設計的豐富經驗,2013年晉升為AMD Fellow,負責AI、深度學習,視訊編解碼和視訊處理領域。
外界不少人誤以為有多款GPU成功經驗的兩位創始人會選擇用GPU挑戰英偉達,但瀚博在2021世界人工智慧大會(WAIC 2021)開幕前夕釋出的首款產品SV102雲端推理晶片採用的是DSA架構,而這款AI晶片獲取客戶的祕訣是TCO(Total Cost of Ownership,總體擁有成本)。
GPU不是雲端推理最好的架構
初創公司要與巨頭競爭,差異化是必然的選擇。對於晶片公司而言,市場規模和技術路線是關鍵的考量因素。就雲端晶片而言,隨著AI模型的成熟,市場對雲端AI訓練需求的增速會降低,雲端AI推理的市場規模將會迅速增加。有資料顯示,2021年雲端推理晶片市場已經大於訓練市場。
雲端AI晶片市場的變化是挑戰英偉達的一個好機會。根據MLPerf此前釋出的基準測試,英偉達在訓練測試中一直保持著較高的水平,但在推理測試中,GPU並不如其在訓練中的表現那麼亮眼。
本月初,英國初創公司Graphcore的IPU首度公開MLPerf基準測結果,結果顯示在Inference v1.0基準測試下,IPU相比GPU有1倍多的價效比收益。
「GPU在推理側不是最好的架構,我們更好的DSA架構,能夠在雲端推理市場完勝GPU。」錢軍表示。
但即便如此,能夠定義和推出客戶願意買單的AI推理晶片才能夠挑戰英偉達。錢軍分享了他的一些思考。他表示,計算機視覺佔了AI市場的大半壁江山,視訊流又佔近70%的資料流,未來視訊相關的資料只會越來越多,因此基於視訊的AI應用首先要有強大的解碼能力。
錢軍認為,AI晶片視訊處理能力可以用三個指標去衡量,包括延遲、吞吐量和能效。
當然,晶片的效能也是核心指標,同時,對於各種資料類型和AI模型的支援也是吸引客戶的關鍵。錢軍介紹,「我們的產品對於支援主流AI模型很全面,晶片設計也有前瞻性,支援計算機視覺、自然語言處理、搜尋推薦、智慧視訊處理領域的眾多常用神經網路,軟體棧支援靈活擴展,支援使用者自定義運算元。」
雲端推理DSA架構晶片完勝GPU
英偉達的眾多挑戰者中,有底氣說出完勝的公司並不多。雷鋒網瞭解到,瀚博的首款晶片研發週期大概是兩年半,這也是業界高效能晶片普遍的研發週期。2018年底瀚博半導體創立之後,瀚博的團隊就開始自主IP的研發,到了今年6月份,首款晶片SV102測試成功。
「SV102開始測試後的8分鐘就全部點亮,也就是通過PCIe就能看到所有功能模組,在30多個小時內,所有模組基礎測試都提前完成。」錢軍說,「這對於一個全新設計的高階晶片是一個奇蹟。」
雖然錢軍沒有具體介紹瀚博的DSA架構,不過CTO張磊用一組資料展示了瀚博首款產品相比GPU的競爭優勢。
瀚博SV102是面向雲端高效能推理的AI晶片,強調AI推理、視訊處理以及可擴展性三大能力。AI推理效能表現在高效、高能耗比和低延時三方面,具體而言,SV102在Int8精度下的峰值效能為200TOPS,在75功耗下,吞吐率是GPU的2-10倍,延時更是不到GPU的5%。

瀚博半導體創始人兼CTO張磊
張磊介紹,SV102採用的是單寬半高半長的設計,儲存最高支援32GB,介面是16個PCIe Gen4,採用被動散熱的方式。之所以單獨給出Int8的效能資料是因為最新和主流雲端推理GPU都只用了Int8做推理基準測試,SV102也支援FP16和BF16的資料類型。

從給出的資料可以看到,在ResNet50和BERT兩個模型下,瀚博SV102對比英偉達最新的A10和主流的T4有2-10倍的效能優勢。
視訊處理則是瀚博AI晶片的一大特色。「國內外已經推出的雲端AI推理晶片幾乎都沒有內建視訊解碼功能,如果客戶需要做視訊解碼,就需要用單獨的晶片進行解碼。SV102就支援64路以上H.264、H.265或AVS2 1080P解碼,支援8K解析度。」張磊表示。

由此帶來的是TCO的優勢,這裡的TCO主要包含伺服器+AI晶片+晶片功耗+運營成本。張磊給出的測算是,基於SV102的效能、功耗以及尺寸的特性,相比T4的伺服器可以節省60%以上的TCO,對比A10的伺服器也可以節省50%的成本。在高密度視訊處理場景,瀚博給出的資料也顯示出其效能和價格的優勢。

贏得網際網路客戶
即便從產品效能層面瀚博有完勝GPU的信心,但客戶的認可才是最終的成功。所以,首要問題就是客戶的遷移成本。張磊告訴雷鋒網:「從AI推理的角度看,遷移到我們的AI晶片上的成本比較小。對於那些有自己演算法的客戶,遷移的成本也是很小的一部分。更重要的是要讓客戶看到TCO的巨大節省,這樣對於客戶來說才能具有足夠的吸引力,應用落地也會非常快。」
錢軍補充表示:「一定要理解客戶的需求,然後針對需求投入精力。」

對於瀚博來說,就是儘快完善軟體和生態的建設。瀚博的VastStream軟體平臺支援TensorFlow、 PyTorch、Caffe2等常見的深度學習框架模型與ONNX格式的模型,藉助高度定製的AI編譯器可以充分優化模型的執行效率。
錢軍介紹,「我們在網際網路側的落地速度更快一些,現已與國內外多家頭部網際網路公司合作。同時,我們還在大力增加軟體團隊,未來軟體人員的數量會是硬體團隊規模的3-5倍。」
雖然錢軍沒有透露具體的合作客戶,不過快手作為瀚博的A輪投資人,雙方應該在業務上更容易達成合作。但無論如何,瀚博的首款晶片的大規模落地還有一段距離。
「瀚博今年的產能已經確定,明年大部分的產能也已經提前預知。」錢軍透露。
小結
今年四月份第一次和錢軍深度對話的時候,對於其產品錢軍僅僅透露了技術路線的選擇。在首款產品流片和完成測試之後,瀚博對外透露了有限的產品資訊,但核心的架構以及內建多路視訊解碼能力的特性並未公佈更多訊息,雷鋒網認為這些才是瀚博最核心的競爭力。
當然,對於網際網路客戶以及行業客戶而言,TCO以及易用程度才是更直接的考量因素。瀚博能否用TCO打動足夠多的客戶,仍需觀察。但同樣值得關注的是,在瀚博的產品規劃裡,有15瓦到150瓦的硬體產品,覆蓋邊緣和雲端。
相關文章

英偉達GPU在AI領域的成功引來了大量的挑戰者。在國外,雲端晶片初創公司幾乎都採用DSA(Domain Specific Architecture,領域專用架構)挑戰英偉達,比如已經被英特爾收購的Habana Lab
2021-07-13 03:05:19

大資料文摘出品 作者:Caleb沒想到,太空旅行的競爭也越來越激烈了。就在美國東部時間7月11日10點30,維珍銀河成功地實現了第4次太空飛行測試。兩組巨大的尾翼,主體呈流線型,尾部有
2021-07-13 03:05:03

CDA資料分析師 出品編譯:Mika【導讀】研究表明,幫助人們應對資訊過載最基本的方法之一就是將其視覺化。用外行的話來說,這意味著把資料畫成圖形,甚至用資料來創建互動式的圖表。
2021-07-13 03:04:52

從強化學習到MCTS,從星際爭霸AI到自動駕駛,上海人工智慧實驗室開源決策智慧平臺OpenDILab,自帶最優參數,一鍵上手SOTA決策AI演算法,AI開發者們趕快試試這個新開源的國產決策AI平
2021-07-13 03:04:24
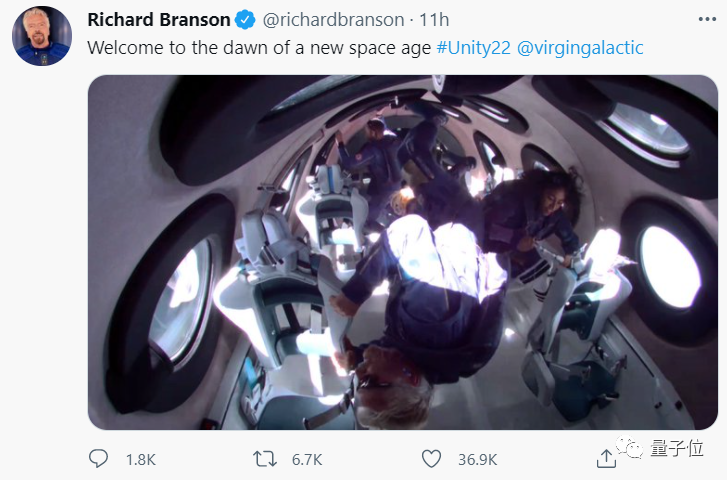
博雯 發自 凹非寺量子位 報道 | 公眾號 QbitAI就在昨天晚上,世界上首架私人太空飛船成功進入太空了!並不是高空,而是真的能看到地球邊緣:還能經歷失重:這架太空飛船名叫VSS Unity
2021-07-13 03:03:47

近日,由開放原子開源基金會與 Linux 基金會聯合開源中國共同舉辦的「GOTC 全球開源技術峰會」在上海世博中心圓滿落幕。本屆 GOTC 吸引了來自全球各個頂級開源基金會的負責人
2021-07-13 03:03:34