導讀在資料庫系統中,收到一個查詢請求時,執行器會負責解析 SQL 語句,生成執行計劃,然後再一步步實現我們的查詢請求。分散式資料庫擁有分散式執行計劃,與傳統單機資料庫相比擁有
2021-07-16 03:05:04
導讀
在資料庫系統中,收到一個查詢請求時,執行器會負責解析 SQL 語句,生成執行計劃,然後再一步步實現我們的查詢請求。分散式資料庫擁有分散式執行計劃,與傳統單機資料庫相比擁有更高的擴展性。本文將介紹 NewSQL 分散式資料庫 ZNBase 的分散式計劃生成機制。
資料庫的服務端,可以劃分為執行器 (Execution Engine) 和儲存引擎 (Storage Engine) 兩部分。其中,執行器負責解析 SQL 命令並執行查詢。資料庫收到查詢請求後,需要先解析 SQL 語句,把這一串文字解析成便於程式處理的結構化資料,然後生成一個邏輯執行計劃,最後再轉換成和資料的物理儲存結構相關的物理執行計劃,從目標節點中調取所需的資料,從而完成整個資料查詢的過程。
執行器執行之前,需要計劃的支撐。計劃分為邏輯計劃和物理計劃。邏輯計劃與物理計劃的關係就好比是我們要出去旅遊,選擇什麼交通工具就相當於邏輯計劃,在這一步比如選擇了飛機後。選擇哪家航空公司就相當於物理計劃。最後,當你真正動身去旅遊就相當於執行。圖1 給出 SQL 語句執行的基本構架圖,從中可以清楚地看到優化器和執行器在整個流程中的執行過程。

圖1 sql 執行基本框架圖
邏輯計劃和物理計劃負責生成執行計劃和索引選擇等功能,可以把它看做優化器。比如執行這樣的語句,執行兩個表的 join:
Select * from t1 join t2 using(ID) where t1.c = 10 and t2.d = 20;
既可以先從 t1 裡取出 c=10 記錄的 ID,再根據 ID 關聯到 t2,再判斷 t2 裡面 d 的值是否等於 20,也可以先從 t2 裡取出 c=20 記錄的 ID,再根據 ID 關聯到 t1,再判斷 t2 裡面 d 的值是否等於 10。這兩種執行方法的邏輯是一樣的,但執行效率不同,優化器可以預估代價決定使用方案。在分散式資料庫中,其中的物理計劃還可以根據要用到的資料 span 所在的節點判斷該運算元在哪個節點上執行,從而實現分散式執行。與分散式相關的物理計劃具體作用在分散式執行概述。
同單機資料庫相比,在執行計劃方面,云溪資料庫 ZNBase 在生成邏輯計劃時是相同的,而在由邏輯計劃生成物理計劃時會有較大的不同。當由邏輯計劃生成物理計劃時,會根據各個節點的資料分佈,新增表資訊和節點資訊,生成分散式的物理計劃。
分散式執行的關鍵思想是如何從邏輯執行計劃到物理執行計劃,這裡主要涉及兩方面的處理,一個是計算的分散式處理,一個是資料的分散式處理。
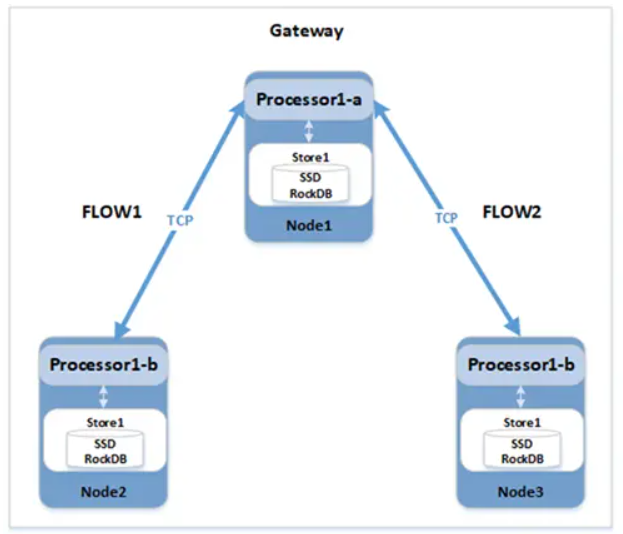
一旦生成了物理計劃,系統就需要將其拆分並分佈到各個 node 之間進行運行。每個 node 負責本地排程 processors 和 inputs。node 還需要能夠彼此通訊以將輸出 output router 連線到 input。特別是,需要一個 streaming interface 來連線這些元件。為了避免額外的同步成本,需要足夠靈活的執行環境以滿足上面的所有這些操作,以便不同的 node 除了執行計劃初始的排程之外,可以相對獨立的啟動相應的資料處理工作,而不會受到 gateway 節點的其他編排影響。
資料庫的叢集中的 Gateway node 會創建一個排程器,它接受一組 Flow,設定輸入和輸出相關的資訊,創建本地 processor 並開始執行。在 node 對輸入和輸出資料進行處理的時候,我們需要對 Flow 進行一些控制,通過這種控制,我們可以拒絕 request 中的某些請求。
每個 Flow 表示整個物理計劃中跨節點執行的一個完整片段,由 processors 和 streams 組成,可以完成該片段的資料拉取、資料計算處理和最終的資料輸出。如圖 2 所示:
 圖2 Flow 執行流程圖
圖2 Flow 執行流程圖對於跨節點的執行,Gateway node 首先會序列化對應的 FlowSpec 為 SetupFlowRequest,並通過 GRPC 傳送到遠端 node,遠端 node 接收後,會先還原 Flow,並創建其包含的 processor 和互動使用的 stream(TCP 通道),完成執行框架的搭建,之後開始由閘道器節點發起驅動的多節點計算。Flow 之間通過 box 快取池進行非同步排程,實現整個分散式框架的並行執行。
對於本地執行,就是並行執行,每個 processor,synchronizer 和 router 都可以作為 goroutine 運行,它們之間由 channel 互聯。這些 channel 可以緩衝通道以使生產者和消費者同步。
為實現分散式併發執行,資料庫在執行時引入了 Router 的概念,對於 JOIN 和 AGGREGATOR 等複雜運算元根據資料分佈特徵,實現了三種資料再分佈方式, 分別是 mirror_router、hash_router 和 range_router。通過資料再分佈,實現了 processor 運算元內部拆分為兩階段執行,第一階段在資料所在節點做部分資料的處理,處理後的結果,根據運算元類型會進行再分佈,然後在第二階段彙集處理,從而實現了單個運算元多節點協作執行。
同單機資料庫相比,ZNBase 的分散式執行計劃使得資料庫有著更高的擴展性,可以有效管理更多的資料,讀寫可以支援更大規模的資料集。
單機資料庫的擴展性是有限的,在單機場景下,資料庫在管理超大規模資料時會有較大的限制,讀寫的效率會隨著表資料的增大而大幅降低。
而在分散式執行計劃中,表資料被分散在多個節點上,這大大降低了單節點的資料量,在儲存同樣資料量的場景下,ZNBase 可以充分利用多個節點的儲存與計算資源。比如在單機場景下,對於某個複雜的表,可能在其資料量從 500 萬行到 1 千萬行的效率衰減十分嚴重,但在分散式場景下,均衡負載時該表被分配到多個節點上,各個節點的實際資料增量並不多,不會有單機場景下的突然效能衰退。
分散式執行計劃還可以做到讀寫,計算的分散式執行。每個節點可以在自己的節點進行獨立的計算,並將最後的結果綜合得到準確的計算結果。在大部分場景下分散式執行比單機資料庫的執行有著較大的優勢。
相關文章
導讀在資料庫系統中,收到一個查詢請求時,執行器會負責解析 SQL 語句,生成執行計劃,然後再一步步實現我們的查詢請求。分散式資料庫擁有分散式執行計劃,與傳統單機資料庫相比擁有
2021-07-16 03:05:04
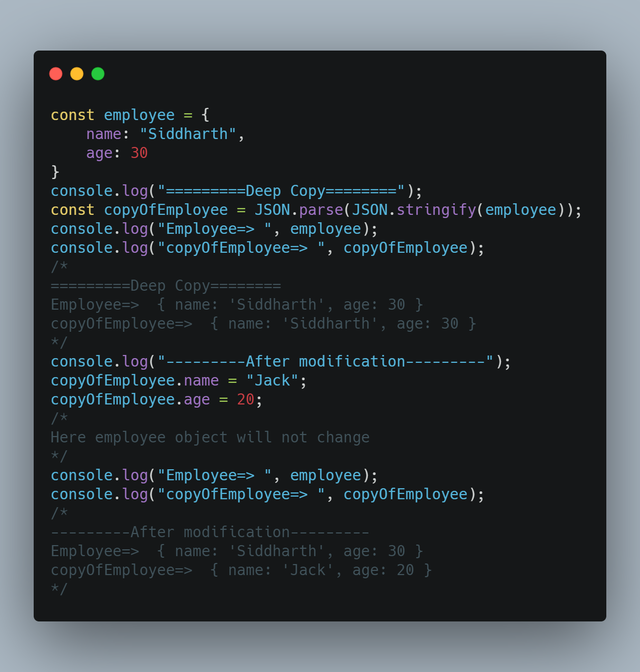
資料複製是我們程式設計中經常會使用到的技術,對於普通數值資料來說,複製很簡單,但是對於複雜類型比如物件的複製,就會有很多需要考慮的東西,比如我們經常說到的深拷貝和淺拷貝。
2021-07-16 03:04:57

這兩天比較熱的新聞事件大概就是谷歌被罰5億了吧,根據法國《巴黎人報》13日的報道,法國消費與競爭管理局因新聞版權紛爭對谷歌公司罰款5億歐元。那麼問題來了,到底是什麼樣的新
2021-07-16 03:04:53
iOS15 Beta3 來臨在今天凌晨,蘋果推送了 iOS15 第三個測試版本,最近蘋果更新頻率還是很高的,在昨天還推出了 iOS14.7 的最終版。從上個測試版本更新上來的話,本次更新包約 1.2GB
2021-07-16 03:04:43

最新訊息,根據Canalys資料統計,2021年Q2季度全球手機銷量迎來了大洗牌,這次Canalys給出的前五名中,有三家來自中國的廠商,分別是小米、OPPO和vivo。根據資料顯示,排名第一的仍然是
2021-07-16 03:04:35

【7月15日訊】相信大家都知道,在最近一段時間,芬蘭的百年通訊巨頭諾基亞正式向國內手機廠商—OPPO發起了5G專利訴訟,目的就是為了收取OPPO手機所使用的諾基亞5G專利技術的專利
2021-07-16 03:04:03