機器之心專欄作者:錢利華本文提出了一種為單步並行生成進行詞之間依賴關係建模的方法。基於該方法的模型GLAT在不久前的國際機器翻譯大賽(WMT2021)上擊敗一眾自迴歸翻譯系統,奪
2021-07-16 03:05:43
機器之心專欄
作者:錢利華
本文提出了一種為單步並行生成進行詞之間依賴關係建模的方法。基於該方法的模型GLAT在不久前的國際機器翻譯大賽(WMT2021)上擊敗一眾自迴歸翻譯系統,奪得了德語到英語方向機器翻譯自動評估第一。

目前機器翻譯中常用的神經網路模型(例如 Transformer ,LSTM)基本上都是自迴歸模型(Autoregressive models)。自迴歸模型在輸出句子時是逐詞按順序生成的,每一個輸出的詞都依賴於之前的輸出詞。

雖然自迴歸模型被廣泛應用並取得了不錯的效果,但是自迴歸模型要求每一步輸出都需要按順序等待前面位置的輸出。因此,按順序生成的方式會阻礙自迴歸模型充分利用平行計算,當輸出文字較長或者模型比較複雜的時候導致機器翻譯的速度很慢。
因此,為了充分利用平行計算資源來加速生成,學術界提出了非自迴歸(Non-autoregressive)的機器翻譯模型[1]。非自迴歸模型去除了每一個輸出依賴於前面部分輸出的限制,假定不同位置之間的輸出是條件獨立的(即每一個輸出的具體值與其他位置的輸出具體取值無關),使得模型可以並行輸出文字。得益於並行輸出的方式,非自迴歸模型可以更充分地利用平行計算來加快生成的速度。

雖然在生成速度上存在優勢,但是之前的非自迴歸模型的翻譯質量和自迴歸模型還存在顯著差距。翻譯質量差距的存在主要是因為如果並行輸出語句,任何詞在輸出之間都無法確定語句中其它的詞,難以有效利用詞之間的依賴關係組成連貫的語句。為了在並行生成中建模並利用詞之間的依賴關係,一些工作提出進行多輪並行輸出來迭代修改語句[2,3,4]。雖然多輪迭代提升了輸出語句的質量,但同時也減慢了生成的速度。
那麼是否有可能只進行一次並行的輸出就得到質量不錯的語句呢?
這裡為大家介紹一篇 ACL2021 的研究非自迴歸機器翻譯的工作《Glancing Transformer for Non-autoregressive neural machine translation》[5], 作者來自位元組跳動人工智慧實驗室,上海交通大學和南京大學。
該工作提出了一種為單步並行生成方式進行詞之間依賴關係建模的方法。在不久前的國際機器翻譯大賽(WMT2021)上, GLAT 擊敗一眾自迴歸翻譯系統,奪得了德語到英語方向機器翻譯自動評估第一。

設計動機和方法
自迴歸模型中最為常用的訓練方式是最大似然估計(MLE),不少非自迴歸模型也直接使用 MLE 進行訓練。但是非自迴歸模型的輸出方式是並行的,輸出語句中的任何部分在輸出之前都無法獲得輸出語句中其餘詞的確切值。所以直接使用 MLE 訓練並行輸出的非自迴歸模型無法有效地建模輸出語句中詞之間的依賴關係。值得注意的是,詞之間依賴關係的建模對輸出通順的語句至關重要,擁有良好生成質量的自迴歸模型和多輪迭代解碼的模型均對這種依賴關係進行了有效的建模。
直接訓練完全並行生成來學習目標語句中詞之間的依賴關係對模型並不友好。一種更為簡單有效的依賴關係學習方式是根據部分輸入詞預測其餘目標詞。但是這種學習方式需要部分目標詞作為輸入,不符合非自迴歸模型並行生成的要求。作者觀察到隨著模型自身更好地學習到詞之間的依賴關係,模型對於依賴關係的學習可以逐漸擺脫使用目標語句部分詞作為輸入的需求。基於以上觀察,Glancing Transformer(GLAT)利用了一種 glancing language model 的方法,通過漸進學習的方式進行詞之間依賴關係的建模。在漸進學習的過程中,模型會先學習並行輸出一些較為簡單的語句片段,然後逐漸學習整句話的單步並行生成。

GLAT 在輸出時和常規的非自迴歸模型保持一致,均只使用一次並行解碼來輸出語句。而在訓練時,GLAT 會進行兩次解碼:
(1)第一步解碼 (Glancing Sampling) 主要根據模型的訓練狀況來估計模型需要看到的目標詞的數量,然後取樣相應數量的目標詞並替換到解碼器輸入中。
(2)第二步解碼時 GLAT 會基於用目標詞替換過後的解碼器輸入來讓模型學習剩餘詞的輸出。模型只在第二步解碼時進行參數更新(Optimization),第一步解碼僅輸出語句。

具體地,在第一次解碼的時候,和常規的非自迴歸模型一樣,模型使用完全並行解碼的方式輸出語句。然後將第一次解碼得到的輸出和訓練資料中的目標語句進行對比。如果輸出和目標語句差距較大,說明模型在訓練中難以擬合該訓練樣本,因此這時 GLAT 會選擇提供更多目標詞作為輸入來幫助學習詞之間依賴關係。反之,如果輸出和目標語句比較接近,則模型自身已經較好地學習瞭如何並行生成該目標語句,所需要的目標詞數量也相應減少。
在第二步解碼之前,模型的解碼器可以得到部分目標詞作為輸入,這些詞的數量由第一步的解碼結果所決定。這時,模型在並行輸出之前可以獲得部分目標詞的確切值,所以在學習輸出剩餘目標詞的過程中就可以對目標語句中詞之間的依賴關係進行建模。

上圖給出了模型訓練中的兩個例子(注意模型只有一個 decoder,在訓練中進行了兩次 decoding)。當模型還不能準確地生成目標語句時,GLAT 會在目標語句中隨機取樣目標詞作為解碼器輸入。例如上圖左邊的例子中,模型的翻譯結果是 「travel to to a world」。GLAT 將該結果和目標語句「travel all over the world」 進行對比,發現當前結果較差,僅有兩個詞和目標語句相同。因此 GLAT 隨機取樣了詞 「over」,並把「over」 的詞向量替換到相應位置的解碼器輸入中。
隨著訓練的進行,模型對資料擬合程度更高,因此能夠更準確地生成目標語句。與此同時,需要作為解碼器輸入的目標語句中的詞的數量會越來越少,在訓練後期逐漸接近學習完全並行生成的訓練場景(例如上圖右邊的例子)。具體的方法細節和實現方式可以參考論文。
效果分析
GLAT 在保持高效生成速度的同時顯著提升了單步並行輸出的翻譯質量

在多個翻譯語向上,GLAT 均取得了顯著提升並超越了之前的單步並行生成模型。結合 reranking 和 CTC 等技術之後,GLAT 可以只使用單步並行生成就達到接近自迴歸 Transformer 的翻譯質量。由於 GLAT 只修改訓練過程,在翻譯時只進行單步並行生成,因此保持了高效的生成速度。
GLAT 提升了非自迴歸模型在長句上的翻譯質量

通過對比不同輸入長度下的翻譯質量,我們發現相比於常規的 NAT 模型(NAT-base),GLAT 顯著提升了在長句上的表現。除此之外,我們還發現在輸入長度較短時,GLAT 的效果甚至略優於自迴歸的 Transformer 模型(AT)。
案例分析

GLAT 和自迴歸的 Transformer 在翻譯結果上各有優劣。通過案例分析,我們可以發現 Transformer 在翻譯時可能會產生部分漏翻的情況,而 GLAT 在語序調整上不如 Transformer.
總結
該工作提出了 Glancing Language Model(GLM),一種為單步並行生成方式建模詞之間依賴關係的方法。在多個數據集上的實驗顯示使用了 GLM 的模型——GLAT 可以大幅提升並行生成的質量,並且僅使用一次並行輸出就可以達到接近自迴歸模型的效果。GLAT 已經在火山翻譯的部分語向上線。此外,基於該技術的並行翻譯模型在 WMT2021 比賽中的德英語向上取得了第一。
相關文章

機器之心專欄作者:錢利華本文提出了一種為單步並行生成進行詞之間依賴關係建模的方法。基於該方法的模型GLAT在不久前的國際機器翻譯大賽(WMT2021)上擊敗一眾自迴歸翻譯系統,奪
2021-07-16 03:05:43

金磊 發自 凹非寺量子位 報道 | 公眾號 QbitAI太難了!太難了!清華電子系,只學3節Python課,然後……然後……就直接要求「手擼」一個AI演算法!就這樣,清華再一次因為難,衝上了知乎熱
2021-07-16 03:05:29
有時我們需要通過恢復系統來解決計算機系統故障問題,但Win7系統有時會提示開啟系統保護,那麼Win7應該如何開啟系統保護?讓我們來看看如何與小編來做。Win7開放系統保護方法1,開
2021-07-16 03:05:17

7月15日,據拼多多訊息,聚焦進口商品交易的多多國際從2019年上線至今,總計銷量達7300多萬件,年交易額同比增長達5倍,覆蓋了全球50多個國家和地區的商品,已成為拼多多的新增長點。在
2021-07-16 03:05:11
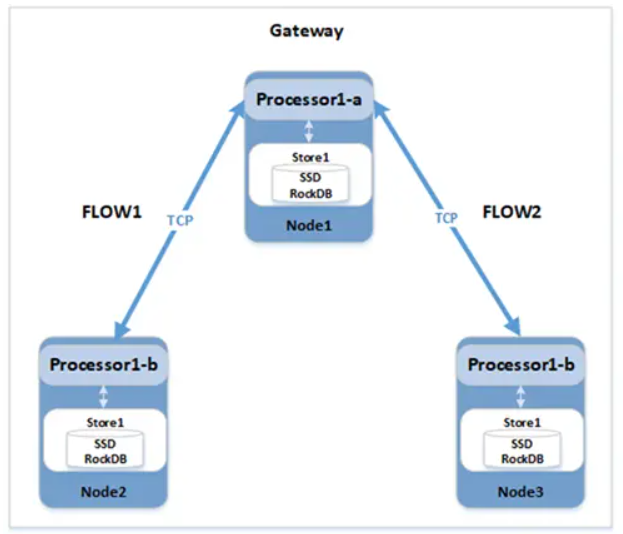
導讀在資料庫系統中,收到一個查詢請求時,執行器會負責解析 SQL 語句,生成執行計劃,然後再一步步實現我們的查詢請求。分散式資料庫擁有分散式執行計劃,與傳統單機資料庫相比擁有
2021-07-16 03:05:04
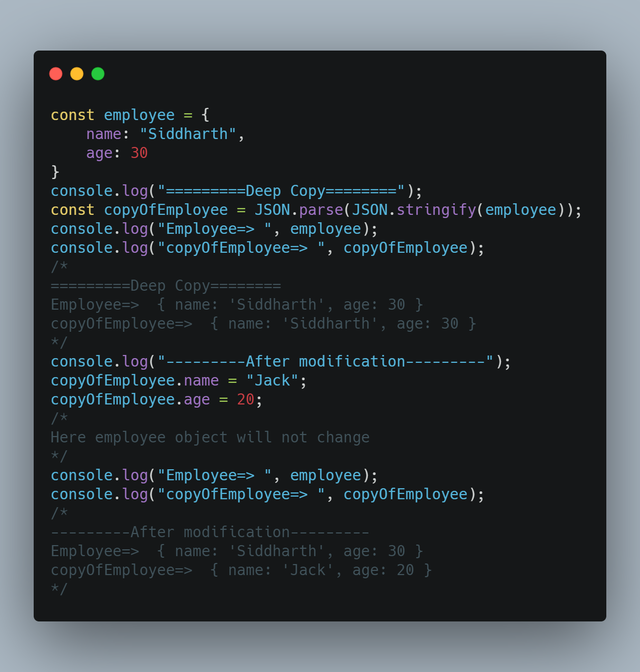
資料複製是我們程式設計中經常會使用到的技術,對於普通數值資料來說,複製很簡單,但是對於複雜類型比如物件的複製,就會有很多需要考慮的東西,比如我們經常說到的深拷貝和淺拷貝。
2021-07-16 03:04:57