明敏 發自 凹非寺量子位 報道 | 公眾號 QbitAIAI生成的文字好不好,最權威的評估者竟然不是人類自己?最近,華盛頓大學和艾倫人工智慧研究院的學者們在研究中發現:未經過訓練的人
2021-07-17 03:04:18
明敏 發自 凹非寺量子位 報道 | 公眾號 QbitAI
AI生成的文字好不好,最權威的評估者竟然不是人類自己?
最近,華盛頓大學和艾倫人工智慧研究院的學者們在研究中發現:
未經過訓練的人類評估文字時,往往過分關注生成文字像不像人話,而忽略了生成文字更重要的問題,即它的內容是否正確、合乎邏輯。
研究人員就給出了一個例子:

他們分別讓未經訓練的人類和機器來評價一段GPT-3生成的文字。
這段文字翻譯過來為:
從前,有一個海盜。他是那種寧願把時間花在驅趕在船周圍游泳的鯊魚上,也不願駛向外國港口尋找戰利品的海盜。他是個好海盜,高尚的海盜,誠實的海盜。他是個寧願和妻兒呆在家裡也不願出海的海盜。
人類評估員認為這段文字除了有些囉嗦外,沒什麼大毛病。
這可能就是一個海盜想回家陪老婆孩子吧,AI可能沒理解,但是這也沒什麼稀奇的。
機器評估也認為這段文字很囉嗦,不過它對文段的內容提出了質疑:
海盜會有老婆孩子?還不和他一起在船上生活?

對比兩種判斷,人類評估更看重這段話像不像人話,在檢驗過它的確非常流暢後,就會預設這段文字沒什麼大問題了。
而機器的判斷角度則更加多維,會考慮到文字傳達的意思是否正確。
很難分辨出GPT-3生成的文字
為了驗證自己的觀點,研究人員讓未經訓練的評估人員來區分人類寫的文字和AI生成的文字。
他們選擇了故事、新聞、菜譜三種不同的文體進行測試。

具體測試中,受試人員不僅要判斷給出的文字是否人類創作的,還要填寫相應的理由。
結果顯示,在區分人類和GPT-2創作的文字時,被測試群體的正確率為57.9%。
但是在區分GPT-3生成的文字上,正確率就下降到了49.9%。
而二選一問題的隨機概率就有50%……

顯然,普通人已經很難識別出當下最先進的NLG模型所生成的文字。
為了更進一步瞭解受試人員是如何做出判斷的,研究人員對150個回答進行了分析。
結果發現,受試人員在做出判斷後,更加傾向於從文字的格式、風格、語法角度上給出理由。
150個回答中,基於文字形式的判斷幾乎是基於內容判斷的2倍。
但是,GPT-3在文字流暢度方面的表現其實已經非常出色,這或許也是為什麼人類很難分辨GPT-3生成文字。
而且研究人員發現,受試人員給出判斷的理由都不盡相同,這也表明人類評估文字沒有一個明確的標準。

既然NLG模型訓練後可以變強,那培訓一下評估人員呢?
研究人員決定對一些受試人員進行了培訓,提高他們評估文字的能力和速度。
他們準備了3種不同的培訓:
第一種是給出明確的判斷標準,讓受試人員學習後來判斷;
第二種是通過大量的例項訓練,也就是題海戰術;
第三種是通過不斷對比來完成訓練。

然而結果表明,這好像並沒有什麼用。
三種培訓後的判斷正確率分別為52%、55%、53%,相較於未受訓時的表現,沒有顯著提高。
不過從受試人員的回答中可以看到,更多人現在會多維度判斷文字了,還是有進步的。
基於這樣的實驗結果,研究人員認為在評估最先進的NLG模型方面,人類可能真的不太靠譜了。
這實驗不太靠譜
對於這樣的結論,網友們提出了一些不同的看法:
判斷文字質量其實是一件非常艱鉅的任務,需要專家來進行評估。或許是這項研究中的受試人員不太行?

有人就指出了問題所在:他們用的Amazon Mechanical Turk的評估員。
是受試人員不太行。

AMTurk作為一個眾包平臺,近年來實在是飽受詬病。
此前BBC報道稱,由於招募到的志願者所在的地區存在一些觀念偏見,導致最後研究出的演算法也存在偏見。
而且招募到的人員水平也常常參差不齊。
不過有人也表示:這些人可能也是最適合的,因為他們最接近普通大眾水平,專家認為好的文字,普通人未必也這麼認為。
這要取決於生成文字的目標人群是誰。實驗中的志願者對喬伊斯(後現代文學作家)的欣賞程度肯定和英文系教授不同。儘管頂級文學評論家將其描述為「20世紀實驗文學的偉大紀念碑之一」和「英語中最美麗的散文詩之一」,但對於大多數普通讀者而言,它非常晦澀難懂。
此外,也有人就對這項研究提出了改進建議:
我認為他們可以用更簡單的NLG演算法(基於規則,n-gram, rnn)進行更精細的分析,並對「非專家」評估者進行排名,而不是將他們作為一個群體來處理。
而關於NLG模型生成文字的評估問題,谷歌曾給出過一個方案。
2020年,它們提出了一個可量化評估NLG模型效能的指標——BLEURT。
這是一個基於BERT的學習評價指標,在學習了幾千個人類評估案例後,它可以對不同模型生成的文字進行打分。
其最大的優勢就是,評估速度更快。
谷歌研究人員認為這個指標有助於NLG模型的研究和開發,而且可以為開發人員提供更加多維的評判標準。
論文地址:https://arxiv.org/pdf/2107.00061.pdf
參考連結:[1]https://www.reddit.com/r/MachineLearning/comments/ok6c4k/r_human_evaluations_no_longer_the_gold_standard/[2]https://arxiv.org/abs/2004.04696
相關文章

明敏 發自 凹非寺量子位 報道 | 公眾號 QbitAIAI生成的文字好不好,最權威的評估者竟然不是人類自己?最近,華盛頓大學和艾倫人工智慧研究院的學者們在研究中發現:未經過訓練的人
2021-07-17 03:04:18
上次的比試,彪彪(滑鼠代稱)心有不甘,總想找機會,再與鍵鍵(鍵盤代稱)比試一場。他為此在Excel武場苦練了一番,終於覺得略有小成,便急匆匆地去找鍵鍵,約武。彪彪見到鍵鍵說:今日有什麼事
2021-07-17 03:04:08

7 月 15 日晚,央視 CCTV 2 財經頻道《經濟半小時》欄目帶來了一期以「開源軟體」為主題的專題報道。報道指出,開源軟體在當今社會的重要性和影響力不言而喻,人們日常生活中使用
2021-07-17 03:03:53
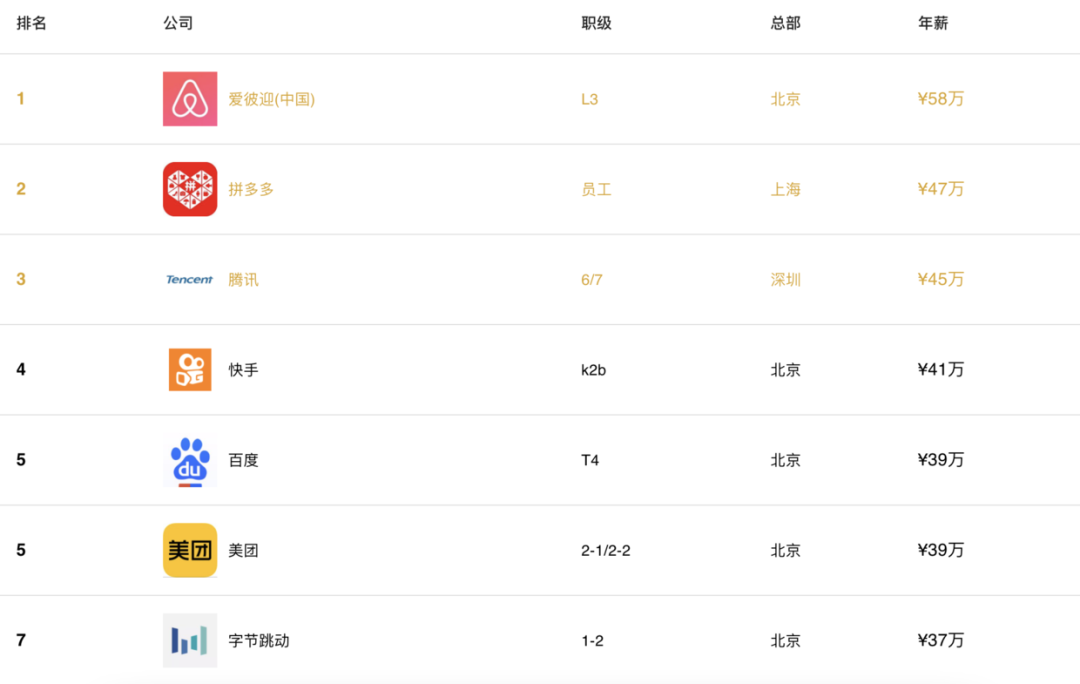
本文中出現數據均以《2021年網際網路產業求職指南》為準。 一、設計和產品競爭最激烈2020年的從求職競爭的角度來看,UI設計崗位以及產品經理崗位是競爭最激烈的。資料顯示一
2021-07-17 03:03:46

最近投了很多簡歷,很多大都石沉大海,小編想通過大廠面試風格、學歷兩方面來說下面試情況和感悟,面試風格可以瞭解到大廠偏向問哪方面;剛畢業那幾年,hr或面試官看簡歷第一眼想看的
2021-07-17 03:03:39

教育優惠來臨在今天,蘋果終於啟動了中國大陸地區的教育網返校季活動!現在購買指定的 Mac 或者 iPad 等產品時候除了可以享受折扣之外,還能獲得贈品。首先要知道,蘋果的教育網優
2021-07-17 03:03:33