在全球疫情背景下,國際間的線下學術交流變得十分困難。這段時間以來,機器之心一直在圍繞國際頂級學術會議在國內舉辦線下活動,促進國內 AI 領域的學術交流。2020 年底,機器之心
2021-07-20 03:03:36
在全球疫情背景下,國際間的線下學術交流變得十分困難。

這段時間以來,機器之心一直在圍繞國際頂級學術會議在國內舉辦線下活動,促進國內 AI 領域的學術交流。
2020 年底,機器之心舉辦了 NeurIPS 2020 中國區 MeetUp,報名人數高達 1300 人,受到了國內 AI 社群的極大關注,眾多高校、企業積极參與。
2021 年 6 月,機器之心又組織了 CVPR 2021 線下論文分享會,邀請到了虞晶怡(視訊致辭)、陶大程、林達華、紀榮嶸、許春景這些業內頂級專家做主題演講,同時也設定了 12 篇論文分享、43 個 Poster 與 9 家企業展臺,充分進行了計算機視覺技術與人才交流。
ACL,作為全球最受關注的自然語言處理頂級會議,每年都吸引了大量華人學者投稿、參會,今年的 ACL 也將於 8 月初線上舉辦。
為了給國內 NLP 社群的從業人員搭建一個自由輕鬆的學術交流平臺,機器之心計劃於 7 月 31 日組織「ACL 2021 論文分享會」,誠邀大家報名參與。
ACL 論文分享會設定 Keynote、 論文分享、 Poster 與企業展臺環節,新增圓桌論壇環節,就業內關注的 Transformer、大規模預訓練模型等熱門主題邀請頂級專家、論文作者與現場參會觀眾進行學術交流。
今日,ACL 2021 論文分享會部分重磅嘉賓正式公佈。我們邀請到了今年的 ACL-IJCNLP 大會主席、中國科學院自動化研究所宗成慶老師現場致辭。兩位 Keynote 嘉賓分別為位元組跳動人工智慧實驗室總監李航和華為諾亞方舟實驗室語音語義首席科學家劉群,兩位 NLP 領域的大咖將為我們介紹對話技術、高效NLP 建模與訓練等相關主題內容。
宗成慶現場致辭

宗成慶,1998 年 3 月在中科院計算所獲得博士學位,現為中科院自動化所研究員、博士生導師,國際計算語言學委員會(ICCL)委員,中國人工智慧學會會士和中國計算機學會會士。主要研究興趣包括自然語言處理、機器翻譯、文字資料探勘和語言認知計算等領域,主持國家自然科學基金重點項目和國家重點研發計劃重點專項等 10 餘項國家項目。在國際權威期刊和一流學術會議上發表論文 150 餘篇,出版專著 3 部、譯著 2 部,其中《統計自然語言處理》(第 2 版)有廣泛的讀者,已被 16 次印刷。曾獲國家科學技術進步獎二等獎、中國電子學會科技進步獎一等獎、中國中文資訊學會「錢偉長中文資訊處理科學技術獎」一等獎和北京市優秀教師、中科院優秀導師等若干獎勵和榮譽。今年擔任 ACL-IJCNLP 大會主席,曾任 ACL-IJCNLP 2015 和 COLING 2020 的程式委員會主席。
李航 Keynote:探索對話技術的未來

李航,位元組跳動科技有限公司人工智慧實驗室總監、ACL 會士、IEEE 會士、ACM 傑出科學家。他碩士畢業於日本京都大學電氣工程系,之後又在東京大學取得電腦科學博士學位。畢業之後,他先後就職於 NEC 公司中央研究所(任研究員)、微軟亞洲研究院(任高階研究員與主任研究員)、華為技術有限公司諾亞方舟實驗室(任首席科學家)。他的主要研究方向包括自然語言處理、資訊檢索、機器學習、資料探勘等。
分享摘要:搜尋和推薦已經成為人們在日常工作和生活中訪問資訊的主要手段。自然語言對話,包括語音對話和文字對話,作為一種新的資訊訪問方式,也開始嶄露頭角,來到了我們的身邊。李航認為,未來的對話,以提供有用的資訊和知識為目標,應該有以下幾個特點:垂直領域、多模態、神經符號處理。對話技術的開發將會圍繞著這些基本特點展開。在這個報告中,他將介紹開發對話技術的體會以及對技術未來發展的看法。首先,他會介紹位元組跳動開發的大力智慧作業燈。這個產品,基於對話等 AI 技術,為小學生使用者提供知識問答、作業批改、作業講解等功能,目的是幫助他們更好地學習、掌握知識和技能。之後,他將討論神經符號處理在對話系統中的重要作用,介紹他們開發的相關技術。最後,他將展望對話技術未來的挑戰和開放性問題。
劉群 Keynote:高效 NLP 建模與訓練,華為諾亞方舟實驗室進展介紹

劉群,華為諾亞方舟實驗室語音語義首席科學家,負責語音和自然語言處理研究,研究方向主要是自然語言理解、語言模型、機器翻譯、問答、對話等。他的研究成果包括漢語詞語切分和詞性標註系統、基於句法的統計機器翻譯方法、篇章機器翻譯、機器翻譯評價方法等。劉群承擔或參與過多項中國、愛爾蘭和歐盟大型科研項目,在國際會議和期刊發表論文 300 餘篇,被引用 10000 多次,培養國內外博士碩士畢業生 50 多人,獲得過 Google Research Award、ACL Best Long Paper、錢偉長中文資訊處理科學技術獎一等獎、國家科技進步二等獎等獎項。他曾任愛爾蘭都柏林城市大學教授、愛爾蘭 ADAPT 中心自然語言處理主題負責人、中國科學院計算技術研究所研究員、自然語言處理研究組負責人,分別在中國科學技術大學、中科院計算所、北京大學獲得計算機學士、碩士和博士學位。
分享摘要:近年來,預訓練大模型在自然語言處理和視覺等相關任務中取得了極大的成功,但這些大模型的訓練和部署都需要消耗大量的計算資源,在很多實際的應用場景中並不適用。華為諾亞方舟語音語義實驗室近年來在高效的 NLP 模型和訓練方面開展了深入的研究,繼前期提出的 TinyBERT、TernaryBERT、DynaBERT 的基礎上,又提出了 BinaryBERT(二值化)、AutoTinyBERT(結構搜尋)、GhostBERT(引入簡單高效的特徵)、MATE-KD(對比資料增強蒸餾)、Annealing-KD(退火蒸餾)等一系列高效的 NLP 建模和訓練方法。本報告將著重介紹他們這方面的研究進展。
Keynote、 論文分享、圓桌論壇、Poster 環節設定暫定如下(以最終公佈日程為準),更多詳細日程請關注機器之心後續公告。
時間:7 月 31 日 9:00-18:00地址:北京燕莎中心凱賓斯基飯店(亮馬橋)

如何報名?
首先,此次活動已獲得贊助支援,因此報名參會免費。
其次,為了保證現場有效交流,我們希望您在報名時填寫正確的身份資訊,我們將在稽核後反饋報名結果。
and,差旅食宿需要參會的小夥伴自行解決,我們將於後續釋出周邊食宿攻略,預祝大家度過愉快的一天。
相關文章

在全球疫情背景下,國際間的線下學術交流變得十分困難。這段時間以來,機器之心一直在圍繞國際頂級學術會議在國內舉辦線下活動,促進國內 AI 領域的學術交流。2020 年底,機器之心
2021-07-20 03:03:36
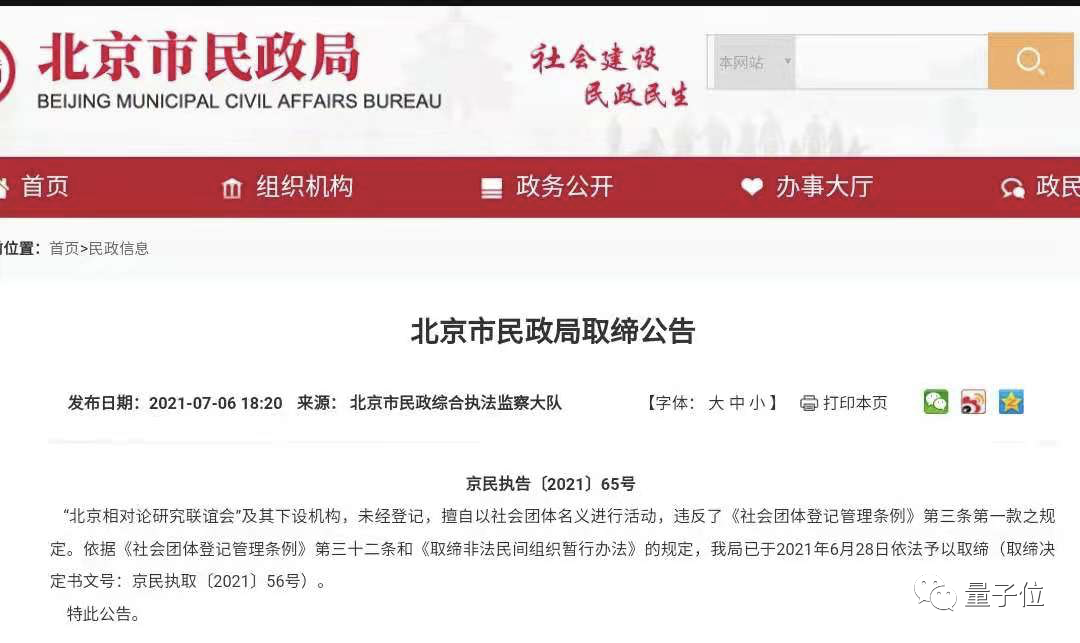
夢晨 發自 凹非寺量子位 報道 | 公眾號 QbitAI據媒體中新網報道,「熟雞蛋返生」論文關聯的非法社會組織「北京相對論研究聯誼會」(簡稱北相)已被依法取締。在北京市民政局網
2021-07-20 03:03:23

出品|開源中國文|白開水為了慶祝世界表情符號日,谷歌方面宣佈對 992 個表情符號進行重新設計,旨在讓表情符號更加真實、通用以及易懂。官方表示,所有的這些新設計的表情符號將
2021-07-20 03:02:36
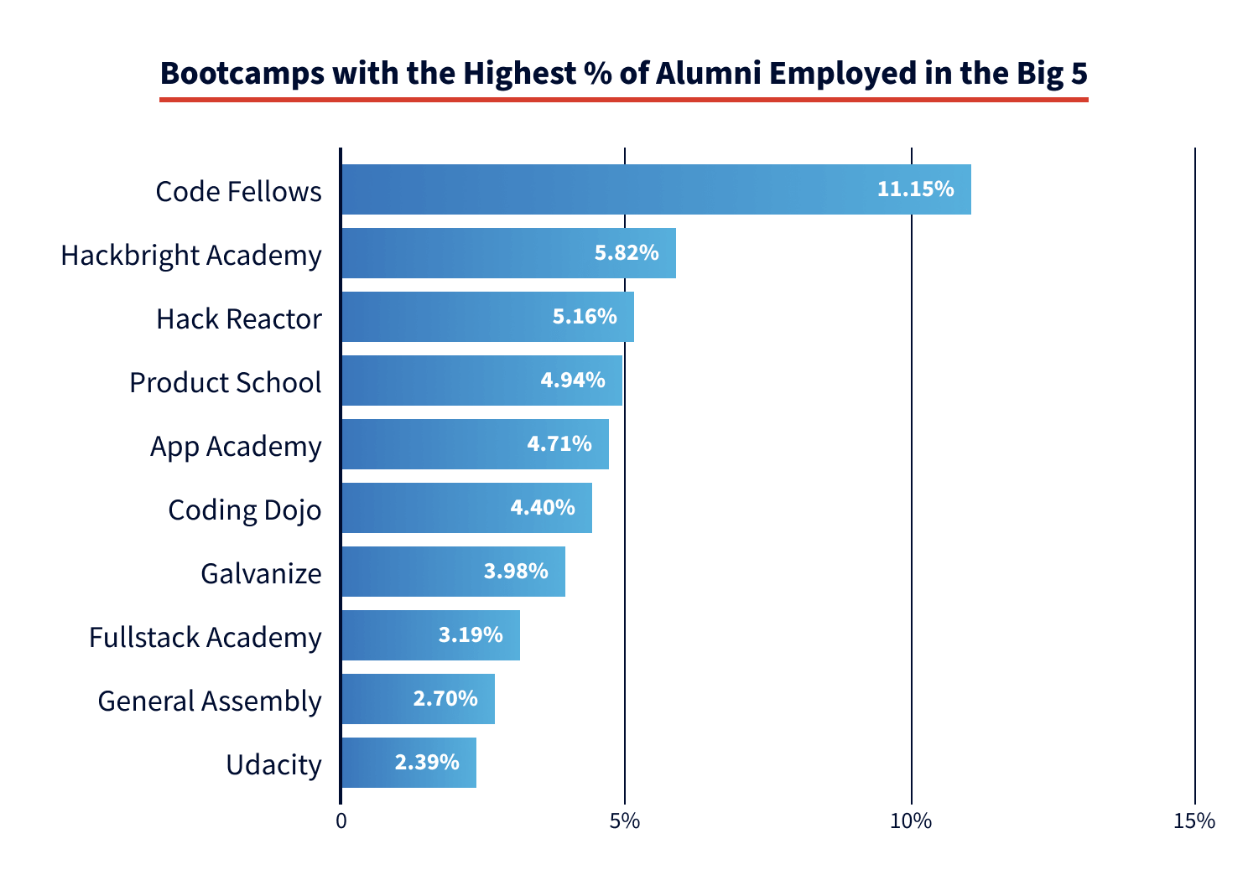
網際網路各行各業推動了IT技術的發展,原來大家只能通過讀計算機專業做IT相關工作,然而在這十年中,各種培訓機構紛紛出現。從傳統線下的,到雙師的到線上的課程,現在還有為時幾天的
2021-07-20 03:02:31
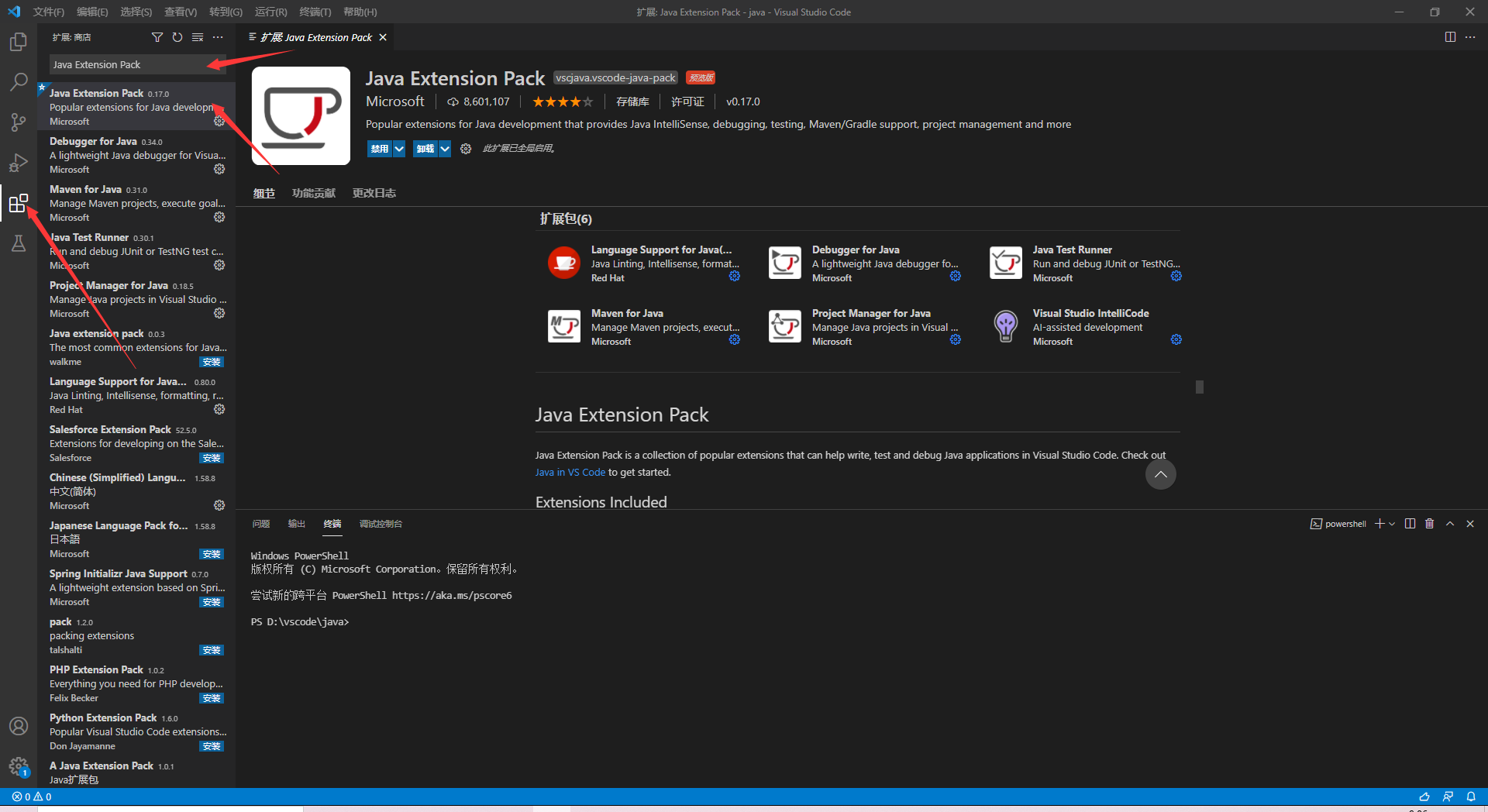
VSCode是微軟開發的簡單而又強大的文字編輯器,使用官方提供的插件市場,可以安裝支援各種程式語言(C/C++/C#等)的偵錯插件,從而將其轉變為各個語言的IDE環境。眾所周知,在Java程式
2021-07-20 03:02:25
MacBook Pro 16 烏龍近日有使用者發現,德國蘋果商城居然出現了一款 MacBook Pro 16 英寸的 M1 版本,使用者在搜尋 MacBook Pro 16 並分享給好友的時候,會出現這款產品。並且這
2021-07-20 03:02:18