出品|開源中國文|局長GitHub 在上週推出了一個名為"GitHub Copilot"的工具,此工具使用了機器學習技術來提供程式碼建議/自動補全,並因此引發了不小的爭議。原因是許多開發者認
2021-08-05 14:23:01
出品|開源中國
文|局長
GitHub 在上週推出了一個名為"GitHub Copilot"的工具,此工具使用了機器學習技術來提供程式碼建議/自動補全,並因此引發了不小的爭議。原因是許多開發者認為,GitHub Copilot 宣稱的基於公開程式碼訓練其實是在未遵循開源許可證的情況下,肆意「抄襲」開原始碼。
個別比較激進的開發者為了抗議 GitHub 未經授權和許可便使用受版權保護的原始碼作為 GitHub Copilot 的訓練資料,宣佈棄用 GitHub。

在眾多的質疑和批評聲中,被討論較多的一個問題是:如果 GitHub Copilot 的訓練模型使用了遵循 GPL 的軟體進行訓練,那麼會發生什麼?
題為"Is GitHub a derivative work of GPL'd software?(GitHub 是 GPL 軟體的衍生作品嗎?)"的部落格文章描述了對這個問題的一些想法。下面是對這篇文章的一些整理。
GPL 的一系列許可證被認為是"Copyleft"許可證,其特點是具備「傳染性」。特別是,Copyleft 作品的常見特徵是要求「衍生作品」使用與原始 Copyleft 許可相同的條款釋出其新作品。
這就引申出了一個有趣的法律問題:機器學習系統生成的作品,甚至是機器學習系統本身,是否屬於「投喂」給訓練模型的資料的衍生作品?如果答案為「否」,是不是意味著可以把 GitHub Copilot 作為一種手段,藉此將自己想使用的 GPL 程式碼進行「清洗」,從而達到無需遵循其許可協議的目的。
但是,如果答案為「是」呢?也就是說機器學習模型生成的作品屬於輸入資料的衍生作品,這樣一來,GitHub 本身也就可以被認為是 Copyleft 軟體的衍生作品。因為 GitHub 的部落格文章在說明"Copilot"的訓練資料時,曾發表如下的表述:
「在 GitHub Copilot 的早期開發過程中,作為內部試用的一部分,近 300 名員工在日常工作中使用了它。」
如果 300 名 GitHub 員工將 Copilot 用作其日常工作流的一部分,他們很可能已將 Copilot 生成的程式碼整合到 GitHub 的幾乎所有軟體資產中,後者為使用者提供了 Web 服務。如果訓練模型是在遵循 AGPL 的軟體上進行訓練,並且 Copilot 使用該模型創造了一個衍生作品。那麼,所有 GitHub 使用者有權根據 AGPL 的條款獲得 GitHub 的原始碼副本——亦即倒逼 GitHub 被迫成為了一個開源項目。
事實上,這裡面還涉及到了機器學習的倫理問題,被納入機器學習訓練資料的內容的所有者應該有什麼權利?
舉個例子,如果我想發表一個不希望被納入訓練模型的作品,或者說如果自己的作品被用於訓練模型,但能讓公眾有權訪問此模型,是否可以實現?是否應該允許我這樣做?如果被使用的作品是我的個人資訊,並且在我不知情或未經同意的情況下被收集,怎麼處理?如果這些被收集的資訊被服務商濫用,甚至是用在一些對自己不利的場景,比如在做貸款決定時,怎麼辦?如果它被用來做違背整個社會利益的事怎麼辦?
相關文章

出品|開源中國文|局長GitHub 在上週推出了一個名為"GitHub Copilot"的工具,此工具使用了機器學習技術來提供程式碼建議/自動補全,並因此引發了不小的爭議。原因是許多開發者認
2021-08-05 14:23:01

國內很多網友不喜歡三星,雖然三星在全球排名第一,但是在中國市場卻排不進前五,三星並不是一直被中國使用者排斥,其實在多年以前,三星曾經也是中國手機市場排名第一的手機廠商,只是
2021-08-05 14:22:50

瓜子最輝煌的時候,曾經一年融資十幾億,拿出10個億去打廣告戰。如果瓜子把這些錢用在嚴格做好質檢上,多補貼消費者,讓買賣雙方真正感受到二手車線上交易平臺的優勢,才能形成良好的
2021-08-05 14:22:37
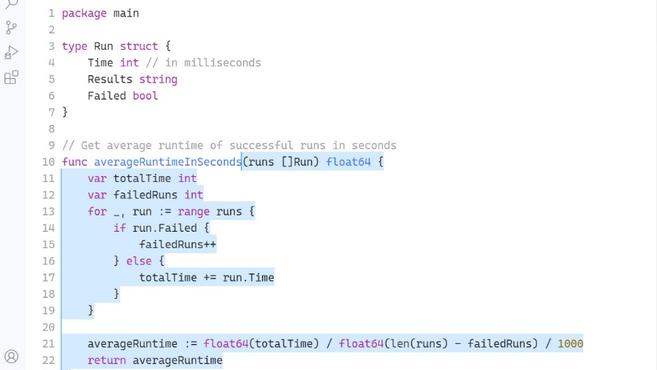
IT之家 8 月 5 日訊息 外媒 MSPoweruser 報道,今年 6 月份,微軟旗下 GitHub 宣佈了 Copilot,是微軟 Visual Studio Code 中內建的一項新的軟體開發人工智慧協助服務。GitHub Co
2021-08-05 14:22:08

最近朋友想買投影儀,預算3000元,但4000多的也可以看看,比較猶豫。實際上,她也不太瞭解投影儀貴了的話,貴在哪裡。那麼,我們不妨看看,在3000-5000元檔,幾款投影儀該怎麼選。首先,我們
2021-08-05 14:02:41

【手機中國新聞】如何用手機拍出一張好照片?可能需要頂級的相機配置,可能需要拍攝者過硬的攝影實力,當然,也需要有一套非常有內容感的濾鏡。現如今,年輕人總愛隨手拍照記錄生活,拍
2021-08-05 14:02:11