嗨嘍,各位同學又到了公佈CDA資料分析師認證考試Level Ⅲ的模擬試題時間了,今天給大家帶來的是模擬試題(一)中的46-50題。(單選題)不過,在出題前,要公佈上一期Level Ⅲ 中36-40題的
2021-08-05 14:23:17
嗨嘍,各位同學又到了公佈CDA資料分析師認證考試Level Ⅲ的模擬試題時間了,今天給大家帶來的是模擬試題(一)中的46-50題。(單選題)
不過,在出題前,要公佈上一期Level Ⅲ 中36-40題的答案,大家一起來看!
41、A
42、A
43、A
44、B
45、D
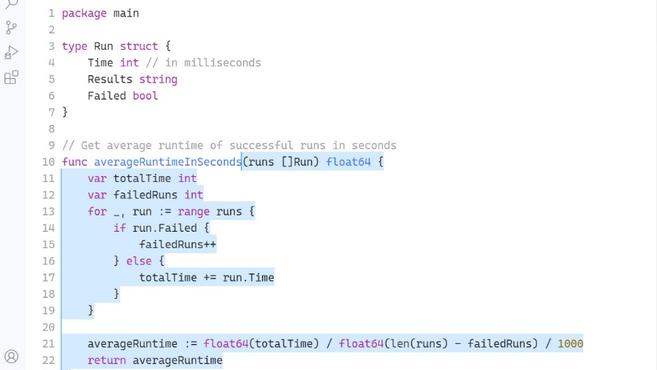
46、特徵縮放是對輸入資料進行標準化/標準化所需的重要預處理之一 。關於min-max特徵縮放的描述錯誤的是:
A.會將資料縮放到0-1範圍之內
B.如果資料存在異常值,資料縮放效果很可能不好
C.作用是將不同量綱資料的量綱進行統一
D.縮放後資料標準差為1
47.常見的缺失值填充方法有填充預設值、均值、眾數等方式。下面可以對分類變數的缺失值填充的方法是?
A.均值
B.中位數
C.眾數
D.最小值
48、特徵工程是將原始資料轉化為特徵的過程,這些特徵可以更好地向預測模型描述潛在問題,從而提高模型對未見資料的準確性。以下不屬於特徵工程的涵蓋範圍的是
A.特徵轉換
B.特徵儲存
C.特徵選擇
D.特徵學習
49、隨機森林(Random Forest,簡稱RF)擁有廣泛的應用前景,從市場營銷到醫療保健保險,既可以用來做市場營銷模擬的建模,統計客戶來源,保留和流失,也可用來預測疾病的風險和病患者的易感性。以下關於隨機森林描述中錯誤的是:
A.隨機森林是一種隨機演算法
B.隨機森林是多棵決策樹共同構成的
C.隨機森林演算法法通常可以防止過擬合
D.隨機森林演算法中的基分類器都是迴歸樹
50、XGBoost是"極端梯度提升"(eXtreme Gradient Boosting)的簡稱,下面關於Xgboost演算法描述錯誤的是
A.Xgboost是在GBDT的基礎上改造而來的
B.Xgboost是一個提升演算法
C.Xgboost的基分類器只能是樹模型
D.GBDT在模型訓練時只使用了代價函數的一階導數資訊,Xgboost對代價函數進行二階泰勒展開
認真答題哦,我們將在下一期公佈正確答案,敬請期待。

登入CDA認證考試官網註冊報名
Level Ⅰ:1200 RMB
Level Ⅱ:1700 RMB
Level Ⅲ:2000 RMB
Level Ⅰ:隨報隨考。
Level Ⅱ:隨報隨考。
Level Ⅲ:一年四屆(3、6、9、12月的最後一個週六),每屆考前一個月截止該屆報名。
Level Ⅰ+Ⅱ:中國內地30+省市,70+城市,250+考場。考生可選擇就近考場預約考試。
Level Ⅲ:中國內地30所城市,北京/上海/天津/重慶/成都/深圳/廣州/濟南/南京/杭州/蘇州/福州/太原/武漢/長沙/西安/貴陽/鄭州/南寧/昆明/烏魯木齊/瀋陽/哈爾濱/合肥/石家莊/呼和浩特/南昌/長春/大連/蘭州。
相關文章

嗨嘍,各位同學又到了公佈CDA資料分析師認證考試Level Ⅲ的模擬試題時間了,今天給大家帶來的是模擬試題(一)中的46-50題。(單選題)不過,在出題前,要公佈上一期Level Ⅲ 中36-40題的
2021-08-05 14:23:17

出品|開源中國文|局長GitHub 在上週推出了一個名為"GitHub Copilot"的工具,此工具使用了機器學習技術來提供程式碼建議/自動補全,並因此引發了不小的爭議。原因是許多開發者認
2021-08-05 14:23:01

國內很多網友不喜歡三星,雖然三星在全球排名第一,但是在中國市場卻排不進前五,三星並不是一直被中國使用者排斥,其實在多年以前,三星曾經也是中國手機市場排名第一的手機廠商,只是
2021-08-05 14:22:50

瓜子最輝煌的時候,曾經一年融資十幾億,拿出10個億去打廣告戰。如果瓜子把這些錢用在嚴格做好質檢上,多補貼消費者,讓買賣雙方真正感受到二手車線上交易平臺的優勢,才能形成良好的
2021-08-05 14:22:37
IT之家 8 月 5 日訊息 外媒 MSPoweruser 報道,今年 6 月份,微軟旗下 GitHub 宣佈了 Copilot,是微軟 Visual Studio Code 中內建的一項新的軟體開發人工智慧協助服務。GitHub Co
2021-08-05 14:22:08

最近朋友想買投影儀,預算3000元,但4000多的也可以看看,比較猶豫。實際上,她也不太瞭解投影儀貴了的話,貴在哪裡。那麼,我們不妨看看,在3000-5000元檔,幾款投影儀該怎麼選。首先,我們
2021-08-05 14:02:41