Kafka是一個多分區、多副本的分散式訊息系統。在實際應用中,kafka通常可以用作訊息系統、儲存系統和流式處理平臺。本主要整理了kafka入門實踐知識,以備查閱。文章內容參考《
2021-08-25 03:04:18
Kafka是一個多分區、多副本的分散式訊息系統。在實際應用中,kafka通常可以用作訊息系統、儲存系統和流式處理平臺。本主要整理了kafka入門實踐知識,以備查閱。
文章內容參考《深入理解Kafka:核心設計與實踐原理》
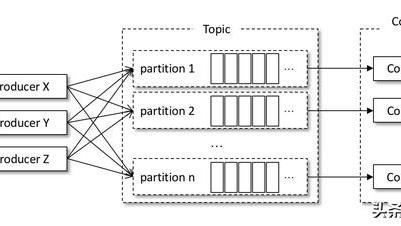
通常情況下,一個kafka體系架構包括多個Producer、多個Consumer、多個broker以及一個Zookeeper叢集。具體結構如下圖所示:

生產者傳送訊息給kafka的時候,必須指定訊息的主題(Topic),消費者也是通過訂閱Topic才能進行訊息消費的。
kafka只保證分區有序,不保證主題有序。
此外,Kafka為分區引入了多副本(Replica)機制,副本之間是「一主多從」的關係,其中leader副本負責處理讀寫請求,follower 副本只負責與 leader 副本的訊息同步。當leader副本出故障時,會從follow副本中重新選舉新的leader副本。

leader副本負責維護和跟蹤 ISR 集合中所有follower副本的滯後狀態,當 follower 副本落後太多或失效時,leader 副本會把它從 ISR 集合中剔除。如果 OSR 集合中有 follower 副本「追上」了 leader 副本,那麼 leader 副本會把它從 OSR 集合轉移至 ISR 集合。

分區ISR 集合中的每個副本都會維護自身的LEO,而ISR集合中最小的LEO 即為分區的HW,對消費者而言只能消費 HW 之前的訊息。
在Java版本的kafka客戶端中,構建訊息的物件是ProducerRecord,它並不是單純意義上的訊息,它包含了多個屬性:
public class ProducerRecord<K, V> { private final String topic; //主題 private final Integer partition; //分區號 private final Headers headers; //訊息頭部 private final K key; //鍵 private final V value; //值 private final Long timestamp; //訊息的時間戳 //省略其他成員方法和構造方法}生產者需要用序列化器(Serializer)把物件轉換成位元組陣列才能通過網路傳送給 Kafka。在Java版本的kafka客戶端中,序列化器通過實現org.apache.kafka.common.serialization.Serializer介面實現。介面定義如下:
public interface Serializer<T> extends Closeable { /** * 配置 */ void configure(Map<String, ?> configs, boolean isKey); /** * 將data轉換為位元組陣列 */ byte[] serialize(String topic, T data); /** * 關閉序列化器 */ @Override void close();}通過key.serializer和value.serializer可以分別指定訊息key和value的序列化器,指定之後,kafka客戶端就會採用相應的序列化器對key和value執行序列化處理。
訊息經過序列化之後就需要確定它發往的分區,如果訊息 ProducerRecord 中指定了partition欄位,那麼就不需要分區器。如果沒有指定,就需要依賴分區器,分區器的作用就是為訊息分配分區。
Kafka中提供的預設分區器是org.apache.kafka.clients.producer.internals.DefaultPartitioner,它實現了org.apache.kafka.clients.producer.Partitioner介面,這個介面中定義了2個方法,具體如下所示。
public interface Partitioner extends Configurable, Closeable { /** * 根據主題、鍵、序列化後的鍵、值、序列化後的值,以及叢集的元資料資訊來計算分區 */ public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster); public void close();}預設的分區器會對key進行雜湊,最終根據得到的雜湊值來計算分區號,擁有相同key的訊息會被寫入同一個分區。如果Key為null,則會隨機分配一個分區。這個隨機是在這個參數metadata.max.age.ms的時間範圍內隨機選擇一個。對於這個時間段內,如果key為null,則只會傳送到唯一的分區。這個值預設情況下是10分鐘更新一次。
通過配置參數partitioner.class來配置分區器。
生產者攔截器既可以用來在訊息傳送前做一些準備工作,也可以用來在傳送回撥邏輯前做一些定製化的需求。其介面為org.apache.kafka.clients.producer. ProducerInterceptor,包含以下3個介面:
/** * 在訊息傳送之前,對訊息內容進行前置處理 */public ProducerRecord<K, V> onSend(ProducerRecord<K, V> record);/** * 在訊息被應答(Acknowledgement)之前或訊息傳送失敗時會呼叫本方法。 * 優先於使用者設定的 Callback 之前執行 */public void onAcknowledgement(RecordMetadata metadata, Exception exception);public void close();通過配置參數interceptor.classes來配置生產者攔截器。

更多可參考:juejin.cn/book/684473…
消費者(Consumer)負責訂閱Kafka中的主題(Topic),並且從訂閱的主題上拉取訊息。在Kafka的消費理念中還有一層消費組(Consumer Group)的概念,每個消費者都有一個對應的消費組。當訊息釋出到主題後,只會被投遞給訂閱它的每個消費組中的一個消費者。
與生產者的序列化相反,消費者的反序列化是將位元組陣列轉換為具體的物件的。反序列器實現了org.apache.kafka.common.serialization.Deserializer介面。
public interface Deserializer<T> extends Closeable { /** * 配置 */ void configure(Map<String, ?> configs, boolean isKey); /** * 反序列化,將data位元組陣列轉換為例項T */ T deserialize(String topic, byte[] data); @Override void close();}消費者消費到的每條訊息的類型為ConsumerRecord,和生產者傳送的訊息類型ProducerRecord相對應,不過 ConsumerRecord中的內容更加豐富,具體的結構參考如下程式碼:
public class ConsumerRecord<K, V> { private final String topic; // 主題 private final int partition; // 分區 private final long offset; // 偏移量 private final long timestamp; // 時間 private final TimestampType timestampType; private final int serializedKeySize; // 序列化key大小 private final int serializedValueSize; // 序列化value大小 private final Headers headers; // 頭 private final K key; // key private final V value; // value private volatile Long checksum; // 校驗和 //省略若干方法}對於 Kafka中的分區而言,它的每條訊息都有唯一的offset,用來表示訊息在分區中對應的位置。對於消費者而言,它也有一個offset的概念,表示消費到分區中某個訊息所在的位置。
對於訊息在分區中的位置,我們將 offset 稱為「偏移量」;對於消費者消費到的位置,將 offset 稱為「位移」,有時候也會更明確地稱之為「消費位移」。

KafkaConsumer類提供了position(TopicPartition)和committed(TopicPartition)兩個方法來分別獲取上下一次拉取訊息的位置和當前已經消費到的位置。
在Kafka中預設的消費位移的提交方式是自動提交,這個由消費者客戶端參數enable.auto.commit配置,預設值為true。當然這個預設的自動提交不是每消費一條訊息就提交一次,而是定期提交,這個定期的週期時間由客戶端參數auto.commit.interval.ms配置,預設值為5秒。
在預設的方式下,消費者每隔5秒會將拉取到的每個分區中最大的訊息位移進行提交。自動位移提交的動作是在 poll()方法的邏輯裡完成的,在每次真正向服務端發起拉取請求之前會檢查是否可以進行位移提交,如果可以,那麼就會提交上一次輪詢的位移。
在 Kafka 中還提供了手動位移提交的方式,這樣可以使得開發人員對消費位移的管理控制更加靈活。手動提交可以細分為同步提交和非同步提交,對應於KafkaConsumer中的commitSync()和commitAsync()兩種類型的方法。
對於採用 commitSync() 的無參方法而言,它提交消費位移的頻率和拉取批次訊息、處理批次訊息的頻率是一樣的,如果想尋求更細粒度的、更精準的提交,那麼就需要使用 commitSync() 的另一個含參方法,具體定義如下:
public void commitSync(final Map<TopicPartition, OffsetAndMetadata> offsets)
在 Kafka 中每當消費者查詢不到所記錄的消費位移時,就會根據消費者客戶端參數auto.offset.reset的配置來決定從何處開始進行消費,這個參數的預設值為「latest」,表示從分區末尾開始消費訊息。如果將 auto.offset.reset 參數配置為「earliest」,那麼消費者會從起始處。
此外,KafkaConsumer還提供了seek()方法,支援追前消費或回溯消費。
public void seek(TopicPartition partition, long offset)總之,seek()方法為我們提供了從特定位置讀取訊息的能力,我們可以通過這個方法來向前跳過若干訊息,也可以通過這個方法來向後回溯若干訊息,這樣為訊息的消費提供了很大的靈活性。seek()方法也為我們提供了將消費位移儲存在外部儲存介質中的能力,還可以配合再均衡監聽器來提供更加精準的消費能力。
再均衡是指分區的所屬權從一個消費者轉移到另一消費者的行為,並且在再均衡發生期間,消費組內的消費者是無法讀取訊息的。 另外,當一個分區被重新分配給另一個消費者時,消費者當前的狀態也會丟失,因此容易發生重複消費問題。在一個訊息者消費了部分訊息還沒來得及提交位移時,如果發生再均衡,另一個消費者會重新消費這部分訊息。 kafka提供了再均衡監聽器ConsumerRebalanceListener,允許在再均衡發生之前以及再均衡完成之後做一些處理邏輯。介面定義如下:
public interface ConsumerRebalanceListener { /** * 這個方法會在再均衡開始之前和消費者停止讀取訊息之後被呼叫。 * 可以通過這個回撥方法來處理消費位移的提交,以此來避免一些不必要的重複消費現象的發生。 */ void onPartitionsRevoked(Collection<TopicPartition> partitions); /** * 這個方法會在重新分配分區之後和消費者開始讀取消費之前被呼叫。 */ void onPartitionsAssigned(Collection<TopicPartition> partitions);}消費者攔截器主要在消費訊息前或在提交消費位移後進行一些定製化的操作。介面為org.apache.kafka.clients.consumer. ConsumerInterceptor,定義如下:
public interface ConsumerInterceptor<K, V> extends Configurable { /** * 在KafkaConsumer.poll()方法返回之前會呼叫本方法對訊息進行相應的定製化操作。 * 比如修改返回的訊息內容、按照某種規則過濾訊息等。 */ public ConsumerRecords<K, V> onConsume(ConsumerRecords<K, V> records); /** * 在提交完消費位移之後呼叫。可以使用這個方法來記錄跟蹤所提交的位移資訊。 */ public void onCommit(Map<TopicPartition, OffsetAndMetadata> offsets);}通過配置參數interceptor.classes來配置消費者攔截器。
KafkaProducer是執行緒安全的,然而KafkaConsumer卻是非執行緒安全的。KafkaConsumer 中定義了一個私有acquire()方法,用來檢測當前是否只有一個執行緒在操作,若有其他執行緒正在操作則會拋出ConcurrentModifcationException異常。KafkaConsumer中的基本所有的公用方法在執行所要執行的動作之前都會呼叫這個acquire()方法。另外,KafkaConsumer還定義了私有release()方法,跟acquire()方法成對出現,可以理解成加鎖操作和解鎖操作。
為了提高整體的消費能力,我們可以通過多執行緒方式實現訊息消費。

一個執行緒對應一個KafkaConsumer例項,一個消費執行緒可以消費一個或多個分區中的訊息,所有的消費執行緒都隸屬於同一個消費組。這種實現方式的併發度受限於分區的實際個數,當消費執行緒的個數大於分區數時,就有部分消費執行緒一直處於空閒的狀態。
這個通過assign()、seek()等方法實現,這樣可以打破原有的消費執行緒的個數不能超過分區數的限制,進一步提高了消費的能力。不過這種實現方式對於位移提交和順序控制的處理就會變得非常複雜,實際應用中使用得極少,也並不推薦。
一般來說,處理訊息才是消費的效能瓶頸。因此,我們可以使用多執行緒方式來非同步處理訊息,進而提高整個消費效能。當然這種方式的缺點一是無法保證訊息的順序處理,而是消費位移提交難以控制。
ConsumerRecords<String, String> records = kafkaConsumer.poll(Duration.ofMillis(100));if (!records.isEmpty()) { executorService.submit(new RecordsHandler(records));}為了實現消費位移控制,需要引入更加複雜的機制實現。這裡暫且不說了,具體可以看看作者原文。

作者:陳添明
連結:https://juejin.cn/post/6999504790715629576
來源:掘金
相關文章
Kafka是一個多分區、多副本的分散式訊息系統。在實際應用中,kafka通常可以用作訊息系統、儲存系統和流式處理平臺。本主要整理了kafka入門實踐知識,以備查閱。文章內容參考《
2021-08-25 03:04:18

早在七月,就有媒體報道稱國產手機品牌vivo在自研晶片,並將推出首款搭載自研影像晶片的新一代旗艦手機,但vivo方面一直未曾做出迴應。就在今日,知名數碼博主@數碼閒聊站再次爆料,
2021-08-25 03:04:11

Callkit是很多朋友期待已久的一個功能,目前 iOS版 微信 和 QQ 都已處於內測階段,引發大量使用者的關注。不過,還有很多人對Callkit是什麼意思,有什麼用,怎麼看自己QQ/微信是否有C
2021-08-25 03:04:04

因為眾所周知的原因,跳票多次才正式亮相的華為P50系列旗艦,一經上線就受到了全國消費者的高度關注。畢竟華為正值前所未有的困難時期,這款高階旗艦的釋出意義非凡。華為P50系列
2021-08-25 03:03:56

8月20日,特斯拉的「AI Day」正式召開,在活動上,馬斯克向全世界展示了特斯拉的AI晶片 Dojo,還介紹了自己的FSD軟體,以及自研的超級計算機。另外在釋出會上,特斯拉還搞了一個讓人驚
2021-08-25 03:03:49

記得在8月18日的時候,華碩天選2遊戲本在京東商城開啟了新款預售,不少小夥伴們都支付了定金,只待補尾款的那一刻,就可以摸到心心念唸的華碩天選2遊戲本了。此次預售的尾款部分將
2021-08-25 03:03:43