很多人學Python都想掌握爬蟲,覺得爬蟲在手天下我有。可是太多人都是從基礎學起,學著學著就不知道該學習哪裡了。介於此原因,專門出一篇爬蟲相關的內容。 先來了解一下爬蟲的流
2021-06-02 13:38:47
很多人學Python都想掌握爬蟲,覺得爬蟲在手天下我有。可是太多人都是從基礎學起,學著學著就不知道該學習哪裡了。介於此原因,專門出一篇爬蟲相關的內容。
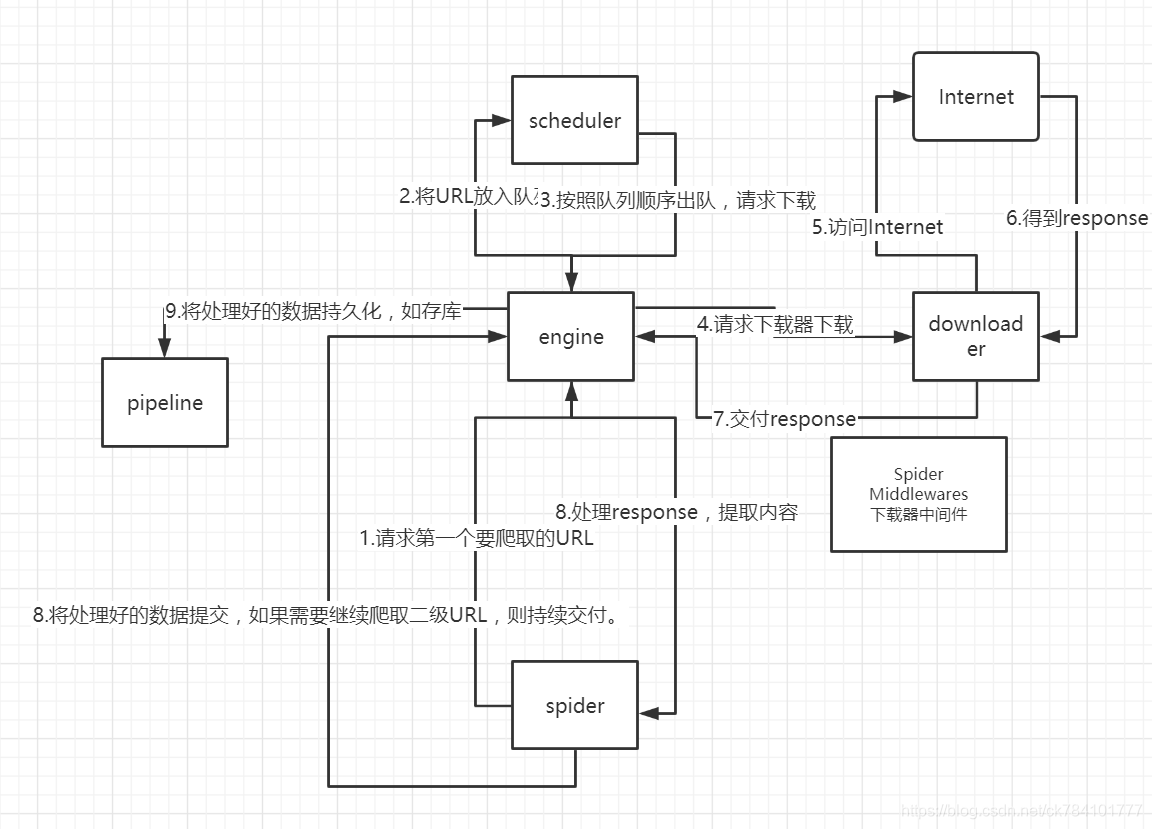
先來了解一下爬蟲的流程:傳送請求—獲取頁面—解析頁面—抽取並存儲內容這樣的流程來進行爬蟲。這樣模擬了我們使用瀏覽器獲取網頁資訊的過程,向伺服器傳送請求後,會得到返回的頁面,通過解析頁面之後,可以抽取我們想要的部分資訊,並且儲存在了我們制定的文件和資料中。
接下來看看爬蟲這條路你需要掌握什麼。
從一個程式設計小白系統入門,開始上手爬蟲,爬蟲出了必要的一些理論知識以外其實更多的就是實操。那麼主流網站資料抓取的能力也就是這個階段要學習的內容。
爬蟲所需的計算機網路/前端/正則//xpath/CSS選擇器等基礎知識;實現靜態網頁,動態網頁兩大主流網頁類型資料抓取;模擬登陸、應對反爬、識別驗證碼等難點詳細講解;多執行緒,多程序等工作常見應用場景難題講解。
(1)準備工作
首先就是下載Python,可以下載最新的版本的。其次就是需要準備運行環境,可以選擇PyChram;
(2)教程
儘量找到合適自己的教程,儘量是配套課程資料源碼都有的那種。但是切記自己要敲一遍程式碼,再對著源碼找到自己的問題。
爬蟲的框架主要是Scrapy實現海量資料抓取,從原生的爬蟲到框架能力,這是一個提升的階段,如果自己可以開發一套分散式爬蟲系統,基本上符合python爬蟲的崗位了。可以高效的獲取到海量資料,並且可以做外包。
這個階段的主要學習內容:Scrapy框架知識講解spider/FormRequest/CrawlSpider等;從單機爬蟲到分散式爬蟲系統講解;Scrapy突破反爬蟲的限制以及Scrapy原理;Scrapy的更多高階特性包括sscrapy訊號、自定義中介軟體;已有的海量資料結合Elasticsearch打造搜尋引擎。

這裡大家不要覺得很難,學會基礎的scrapy的使用是很快的,因為很多的demo,但是對於實際爬蟲來說不簡單,因為會出現robots.txt禁止爬蟲的原因。
所以基礎爬蟲很簡單,是反爬蟲就沒那麼容易。
深入APP資料抓取也是提升自己爬蟲的能力,應對APP的資料抓取和資料視覺化的能力,這就拓展了自己的業務能力,增強了在市場中的競爭力。
所以抓取是一步,視覺化是另外一部分。
學習重點:學會主流抓包工具Fiddler/Mitmproxy 的應用;4種App資料抓取實戰,學練結合深入掌握App爬蟲技巧;基於Docker打造多工抓取系統,提升工作效率;掌握Pyecharts庫基礎,繪製基本圖形,地圖等實現資料視覺化。
其實爬蟲可以應用在很多領域,爬蟲也是資料分析市場調研的主要步驟。更進階的就是機器學習,原始資料的挖掘。
其實從爬蟲入手開始學Python也是非常建議的一條路,因為有目標才更容易找到學習重點。
相關文章
很多人學Python都想掌握爬蟲,覺得爬蟲在手天下我有。可是太多人都是從基礎學起,學著學著就不知道該學習哪裡了。介於此原因,專門出一篇爬蟲相關的內容。 先來了解一下爬蟲的流
2021-06-02 13:38:47

【微創WEC科技】目前市面上的安卓手機,絕大多數電池都超過了四千毫安時,唯獨iPhone的電池卻一直沒有突破到四千,只有iPhone 11 Pro Max勉強接近了,擁有3969毫安電池,但去年的iPho
2021-06-02 13:18:51

【科技犬】寶馬官方正式釋出了全新純電中型車i4,該車將搭載寶馬最新的iDrive 8車載系統,並將推出i4 eDrive40和i4 M50兩款車型,其也是含M的首款電動車。該車的車身尺寸為4785/1
2021-06-02 13:18:37

之前AMD已經發布了新一代APU產品,算是Ryzen 5000移動處理器的桌面版,核心代號為Cezanne,實際上是Zen3處理器加上Vega顯示卡所組成。雖然集顯架構沒有變化,但是處理器核心架構的
2021-06-02 13:18:21

月石一 發自 凹非寺量子位 報道 | 公眾號 QbitAI英偉達的新款顯示卡RTX 3080 Ti和3070Ti終於來了。沒有意外,在這波礦潮中,兩張新卡仍然限制挖礦效率。這兩款顯示卡都支援Nvid
2021-06-02 13:17:15

【6月2日訊】相信大家都知道,在國內智慧手機市場上,雷軍所創立的小米手機一直都有著「價格屠夫」、「價效比之王」美譽,可以說在過去很長一段時間,小米手機總可以憑藉更低的售價
2021-06-02 13:16:48