蕭簫 發自 凹非寺量子位 報道 | 公眾號 QbitAI這年頭,真是什麼樣的資料集都有了。IBM的5億行程式碼(bug)資料集、清華&阿里的460萬少樣本NER資料集、還有假貨資料集、「黑話」
2021-06-08 09:37:17
蕭簫 發自 凹非寺量子位 報道 | 公眾號 QbitAI
這年頭,真是什麼樣的資料集都有了。
IBM的5億行程式碼(bug)資料集、清華&阿里的460萬少樣本NER資料集、還有假貨資料集、「黑話」資料集、小黃圖資料集……咳咳。
沒錯,相比遭遇瓶頸的演算法,資料現在成了AI行業的「香餑餑」——
他們發現,當年一個ImageNet走天下,微調AI模型參數就能取得SOTA的時代已經過去。
來自谷歌AI的最新研究表明,要想在細分領域取得更好的模型效果,精準優質的資料十分重要,它在極大程度上決定了AI模型的效能。

例如,谷歌曾經做過一款流感趨勢預測模型,但由於資料質量太差,預測結果甚至偏離了流感峰值的140%。
連斯坦福大學副教授、Coursera聯合創始人吳恩達,也強調資料質量對於AI的重要性:
80%的資料+20%的模型=更好的AI。
真正「有用」的AI模型,離不開資料
一直以來,資料質量對於AI模型的影響程度都在被低估。
隨著大模型如BERT、Alphafold2、GPT-3、DALL·E逐漸成為人工智慧產業的潮流,更多的資料也在被「投喂」進各種AI模型中。
資料質量的問題,也因此更加突出。
來自谷歌、蘋果、斯坦福、哈佛等七家頂級機構的一項研究表明,越大的語言模型,隱私洩露風險就越高。
他們用OpenAI的GPT-3模型做了實驗,發現只需要一串「暗號」,就能讓它報出某個人的姓名、電話、住址等隱私資訊。

由於AI模型不能完全「消化」資料,只會把訓練資料中的一部分原樣展示出來,導致模型越大,對資料的記憶能力就越強,洩露隱私、輸出虛假資訊片段的可能性就越高。
不少大型AI公司,已經開始從根本上解決資料質量問題。
谷歌就已經開始研發資料處理演算法,其中的TEKGEN模型,能將資料質量靠譜的知識圖譜轉換成文字資料庫,再用於AI模型的訓練。

而IBM、清華大學、阿里達摩院等國內外研究機構,也開始建立類似程式碼bug、假貨、少樣本NER一樣的細分領域資料集。
但這些做法都需要足夠的人力和精力,相比之下,外包/眾包可能是更多AI企業的選擇。然而在這種情況下,又可能獲得不合要求、甚至良莠不齊的資料,質量難以保障。
現在,AI訓練資料處理行業中迸現出一匹黑馬——
一家對AI演算法落地有所研究的AI訓練資料服務商,自主研發了一個名為「雲測資料標註平臺4.0」的資料處理平臺,直接將資料標註的最高準確率提升到了99.99%。
據云測資料表示,這一平臺使得企業服務成本平均降低了60%以上,至於研發AI項目的效率,則提升了2倍不止。
這樣的標註效率,並非有口無據。在4.0正式版上線前,「雲測資料標註平臺」一直是雲測資料內部自用的AI訓練資料處理平臺。
正是憑藉著這一平臺,結合其高精準資料標註能力和場景化訓練資料方案等實力,雲測資料連續兩年在資料標註公司排行榜上奪得TOP 1的位置。

他們的平臺,憑什麼拿下行業TOP 1?
憑的是三大技術特點:穩、全、快。
首先,對於目前成熟的標註場景,保證AI輔助標註穩定不出錯。
對於智慧資料標註技術來說,目前比較成熟的場景包括OCR(光學字元識別)、語音切割等任務。
以OCR為例,識別準確率是基本要求,更重要的是文字識別的效率:

至於ASR(語音識別)也是基本操作:

當然,如果需要的是TTS(智慧轉寫)方面的資料,將一段話迅速轉成拼音也非常easy:

其次,平臺的效率不僅體現在識別速度和準確率上。
「雲測資料標註平臺4.0」另一個重要的特性,體現在它的場景全面性上——既能做2D邊界框這種最簡單的標註,也能做業內公認非常難的多端資料融合。
從影象、文字、語音、音視訊……只有你想不到,沒有平臺做不到的資料類型。
先以進階一點的NLP實體抽取為例。
這項技術的難點在於,必須迅速找出一段長文字中最有用的關鍵資訊,過程中不僅涉及大量學術名詞,而且分類的合理性也必須考慮。
在這種情況下,「雲測資料標註平臺4.0」對於醫療專業的學術名詞也能輕鬆處理,且能準確地按照資料要求進行分類:

更重要的是,這一平臺也能做行業公認較難的一項技術——多端資料融合。
這項技術包括多模態融合和多感測器融合兩種類型,每種類型對於融合演算法的要求都非常高。
以這項技術目前應用最廣泛的自動駕駛領域來看,多感測器融合不僅要將多個感測器如鐳射雷達的資料進行融合,使得系統獲取比單一感測器資料更多的資訊,還得確保這一過程的準確率。
例如,一個簡單的框就能將車輛的3D鐳射點雲資料自動識別出來,更重要的是還能做智慧貼合:

除此之外,在這些資料中,還涉及語音、影象、文字等多種模態資訊的融合,即使只是影象資訊,也涉及2D和3D資料的融合。
而在實現了感測器和多模態融合後,也還需要面臨由於感測器硬體更迭,導致資料類型更新的問題,因此在工程實現時,可擴展性也是考慮因素之一。
最後,也是最重要的,就是對資料標註效率的提升了。
不同的AI模型,所用的資料類型並不一樣,因此在獲取AI訓練資料時,也必須相應地調整標註方式,然而有些方法由於標註效率很低,從而導致成本的提升。

以影象分割為例,這項技術目前主流的標註方法有兩種:多邊形分割、畫素級標註。
其中,多邊形分割是一個成本巨大的標註方式,操作者必須像用PS裡的「鋼筆」一樣,一點點地描出目標物體的邊緣形狀,將它與背景分割開來。
如果採用智慧多邊形分割的話,往往會出現細節卻需要反覆調整的情況,甚至比人工描邊還慢(以某開源平臺的智慧標註效果為例):

相比之下,目前比較先進的標註方法畫素級標註,以2D邊界框的簡單操作就能迅速標註出物體的形狀,準確率比多邊形分割要高得多:

然而,並非所有AI影象分割模型都採用畫素級標註的資料訓練。
這就導致在AI模型要求多邊形分割資料時,會出現標註成本極高的情況。
為此,「雲測資料標註平臺4.0」背後的程式設計師們,對多邊形分割進行了優化:以畫素級標註的簡單操作,也能標註出多邊形分割的效果,極大地加快了不同類型資料標註的效率。
或許有的人還對資料標註行業有所誤讀。但「雲測資料標註平臺」已經用實力證明,做出精準高質量的資料,同樣是一個技術活。
現在,這一平臺的4.0正式版,已經對外商業化使用。
雲測資料,行業中的「資料科學家」
自人工智慧爆發以來,「雲測資料標註平臺」已有近5年的沉澱。
2017年,正值AI技術爆發一年有餘,各行業對於資料處理的需求只增不減,隨著AI模型變得越來越多樣化,更多元的資料需求也在被提出。
雲測資料能走到如今行業資料質量TOP 1的位置,客戶涉及智慧駕駛、智慧金融、智慧城市到智慧家居等多個行業,涵蓋計算機視覺、語音識別、自然語言處理、知識圖譜等AI主流技術領域,所做的遠不止把控AI訓練資料的準確率。

資料標註,只是控制AI訓練資料質量中的一環。
事實上,從AI企業提出對應需求的那一刻起,雲測資料就開始對質量進行把控了。
接到需求後,雲測資料採集團隊需要根據客戶所用的AI演算法模型,對所採集的資料進行評估梳理,確定貼合模型訓練的資料採集需求,通過行業首創的資料場景實驗室進行相應的採集。
同時,在資料採集階段,雲測資料團隊就會先對採集的資料進行稽核清洗。
這一步非常關鍵,許多未經稽核清洗就用作標註的資料,可能包含有不適合用作模型訓練的隱私資料、或低質量資料。
對於隱私資料,需要適當對資料進行脫敏化處理;至於低質量資料,則需要對資料進行清洗,確保這批資料適合標註。
至於資料標註和質檢的過程也堪稱嚴苛,雲測資料設計了從創建任務、分配任務、標註流轉、到質檢/抽檢環節和最後的驗收等更完善的管理流程,每個環節有相應專業人員來把控資料標註的質量和時間節點,得以在保證質量的前提現下可以真正提高效率。

這意味著,即使AI企業只提供一個模糊需求,雲測資料也能通過從採集到標註的一整套流程,將能夠直接使用的AI訓練資料呈現給企業。
因此,要想從根本上控制資料質量,即使是資料行業也得掌握AI演算法工程師的技術:
只有理解AI演算法的原理,才能明確最適合模型的資料條件和類型,最終交付合適的AI訓練資料。
這幾年時間裡,雲測資料其實遇見過不少以「一篇AI論文」為需求的資料處理客戶。
尤其是在AI技術爆發初期,許多企業對AI演算法有一定了解,但並不清楚應該怎麼處理資料,也沒有任何可以用於AI模型訓練的資料資源。
而且隨著自動駕駛、金融、醫療等專業領域開始用上更復雜的AI演算法,資料質量開始成為「重點關注物件」,任何一個錯誤的資料,都可能降低模型的準確率。
日新月異的AI演算法、和更加複雜的場景,讓一路走過來的雲測資料,磨鍊出了如今的「雲測資料標註平臺4.0」,不僅資料類型全面,而且資料質量高。
接下來,他們還希望能將這個平臺進一步智慧化,以迎接接下來的行業挑戰。
雲測資料總經理賈宇航表示,這或許最終會演變成一場「質量與效率上的博弈」:
最近,自動駕駛行業很火,我們需要處理的資料也呈現出一個數量級的增長。例如,去年一家企業只需要採集10輛RoboTaxi的資料,今年就增加到了百千輛RoboTaxi。但我們希望,在保證資料質量不變的情況下,資料處理成本不會呈線性增長,而是利用智慧化平臺,讓資料處理的成本更合理、效率更高。
雲測資料的真實身份,其實是AI訓練資料行業中的「資料科學家」:
他們的目標,是讓AI行業能真正實現資料驅動。
相關文章

蕭簫 發自 凹非寺量子位 報道 | 公眾號 QbitAI這年頭,真是什麼樣的資料集都有了。IBM的5億行程式碼(bug)資料集、清華&阿里的460萬少樣本NER資料集、還有假貨資料集、「黑話」
2021-06-08 09:37:17

近日凌晨,蘋果在WWDC21 開發者大會上,正式釋出了 iOS 15、iPadOS 15、WatchOS 8、macOS 12 以及 tvOS 15 系統,開幕式結束後,iOS 15首個測試版就推送了(公測版下個月推送,正式版將
2021-06-08 09:36:39
很多人肯定有和筆者一樣感嘆,連iOS14上的新功能還沒弄明白,iOS15這麼快就來了。其實除了春秋兩個釋出會,6月份的WWDC(蘋果全球開發者大會)也相當重磅,因為這場大會相比較噱頭沒那
2021-06-08 09:36:15

華為前段時間釋出了Harmony OS 2.0正式版,並且宣佈實現了「萬物互聯」;那麼,Harmony OS是如何做到的呢?小宅帶小夥伴們來看一下。首先需要對Harmony生態進行分析,這個生態實際上
2021-06-08 09:16:53
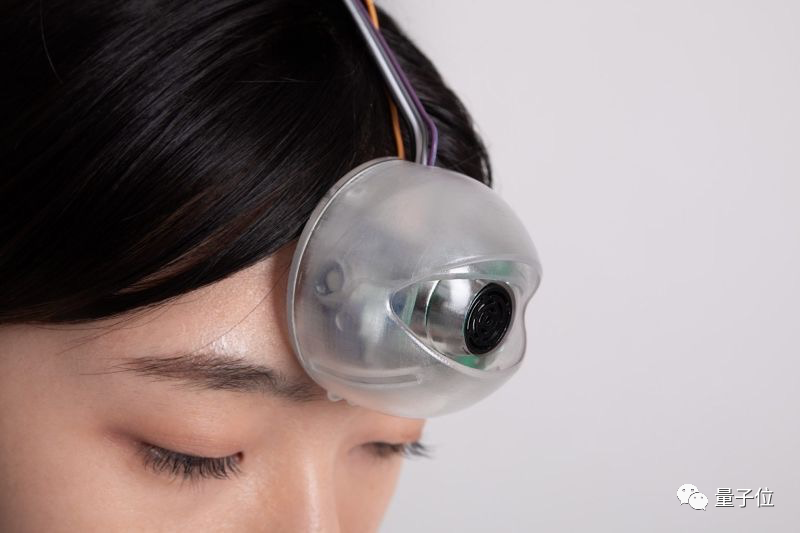
月石一 發自 凹非寺量子位 報道 | 公眾號 QbitAI撞樹、撞電線杆、撞玻璃門……經歷過這些的低頭族們,是不是隻恨沒有「多一隻眼睛幫自己看路」?△圖源:minwookpaeng@instagram
2021-06-08 09:15:00

#蘋果WWDC釋出會#【iOS 15 懶人包】預告:iPhone 13 系列 11 個新功能Apple全球開發者大會WWDC 2021,難得地最先登場的,就是iOS,也是我們每年最期待的項目之一。而今年推出的,就是
2021-06-08 08:55:47