作者:管延信導讀云溪資料庫 ZNBase 是由浪潮開源的一款 NewSQL 分散式資料庫,具備 HTAP 特性,擁有強一致、高可用的分散式架構。對於一個高可用的分散式系統來說,為了保障不同叢
2021-06-08 11:49:01
作者:管延信
導讀
云溪資料庫 ZNBase 是由浪潮開源的一款 NewSQL 分散式資料庫,具備 HTAP 特性,擁有強一致、高可用的分散式架構。對於一個高可用的分散式系統來說,為了保障不同叢集不同節點的資料一致,一致性演算法尤為重要。Raft 是一種管理日誌複製的分散式一致性演算法,包括 ZNBase 在內的很多分散式系統都採用 Raft 作為底層的一致性協議。本系列文章將為大家介紹 Raft 一致性演算法在 ZNBase 中的落地實踐,並深入解析 ZNBase 技術團隊根據自身業務需求對 Raft 協議做出的五大優化改進。
Raft 簡介
Raft 作為一種管理日誌複製的分散式一致性演算法,由斯坦福大學的 Diego Ongaro 和 John Ousterhout 在論文中提出。在 Raft 出現之前,Paxos 一直是分散式一致性演算法的標準。但 Paxos 相對難以理解,Raft 的設計目標就是簡化 Paxos,使得一致性演算法更容易理解和實現。
Paxos 和 Raft 都是分散式一致性演算法,其過程如同投票選舉領袖(Leader),參選者(Candidate)需要說服大多數投票者(Follower)給他投票,一旦選舉出領袖,就由領袖發號施令。Paxos 和 Raft 的區別在於選舉的具體過程不同,社群中關於 Raft 演算法的詳細講解非常豐富,這裡就不再贅述。檢視詳情
ZNBase 中的 Raft 演算法
云溪資料庫 —— ZNBase 是分散式資料庫,與 OceanBase、CockroachDB、TiDB 一樣都是NewSQL 家族的一員。云溪資料庫具備強一致、高可用的分散式架構,能夠水平擴展,提供企業級的安全特性,完全相容 PostgreSQL 協議,能夠為使用者提供完整的分散式資料庫解決方案。ZNBase 的整體架構如圖 1 所示:

圖1:ZNBase 的整體架構
ZNBase 各方面的強一致性都通過 Raft 演算法實現。首先,Raft 演算法保證分散式多副本之間資料強一致性以及外部讀寫的一致性。簡而言之,ZNBase 中資料會有多個副本,這些副本存放在不同的機器上,當其中一臺機器故障宕機後,資料庫依舊能夠對外提供服務。此外,ZNBase 會根據插入資料的鍵,將資料劃分為多個 Range,每個 Range 上的資料均由一個 Raft Group 來維持多個副本之間資料的一致性。因此,準確地說 ZNBase 使用的是 Multi-Raft 演算法。
具體來說,ZNBase 的儲存層基於 RocksDB 開發,利用單機的 RocksDB,ZNBase 可以將資料快速地儲存在磁碟上;在出現單機故障時,利用 Raft 演算法可以快速地將資料複製到機器上。在這個過程中,資料的寫入是通過 Raft 演算法介面實現的,而不是直接寫入 RocksDB。通過 Raft 演算法,ZNBase 變成了一個分散式的鍵值儲存系統,面對不超過叢集半數的機器故障情況宕機,完全能夠通過 Raft 演算法自動把副本補全,做到業務對故障的無感知。
在項目開發前期,ZNBase 中的 Raft 演算法採用的是開源的 etcd-raft 模組,該模組主要提供如下幾點功能:
Leader 選舉;
成員變更,可以細分為:增加節點、刪除節點、Leader 轉移等;
日誌複製。
ZNBase 利用 etcd-raft 模組進行資料複製,每條資料操作都最終轉化成一條 RaftLog,通過 RaftLog 複製功能,將資料操作安全可靠地同步到 Raft Group 中的每一個節點上。不過在實際操作中,根據 Raft 的協議,只需要同步複製到多數節點,即可安全地認為資料寫入成功。
但是在後續的生產實踐中,ZNBase 研發團隊逐漸發現 etcd-raft 的模組仍存在諸多限制,於是陸續開展瞭如下多個方面的優化工作,具體包括:
新增 Raft 角色
新增 Leader 親和選舉
混合序列化
Raft Log 分離與定製儲存
Raft 心跳與資料分離
下文將著重介紹第一點,即 ZNBase 團隊根據自身業務需要為 Raft 模組新增的三種角色。
ZNBase 對 Raft 模組的改進
新增 Raft 角色
1、強同步角色
為解決部署在跨地域的多資料中心資料同步問題,達到資料在多地共同寫入的效果,實現地域級別的容災能力,ZNBase 研發團隊在 etcd-raft 模組中新增了強同步角色。
具體措施如下:
為副本增加強同步標識以及配置和取消強同步標識的邏輯。
etcd-raft 模組原有的日誌提交策略:Leader 得到超過半數副本(包括 Leader 自身)的投票才能提交 Raft 日誌。ZNBase 在原有的過半數提交策略基礎上,增加了強同步角色的日誌提交策略——日誌提交還需要得到所有強同步副本的投票。
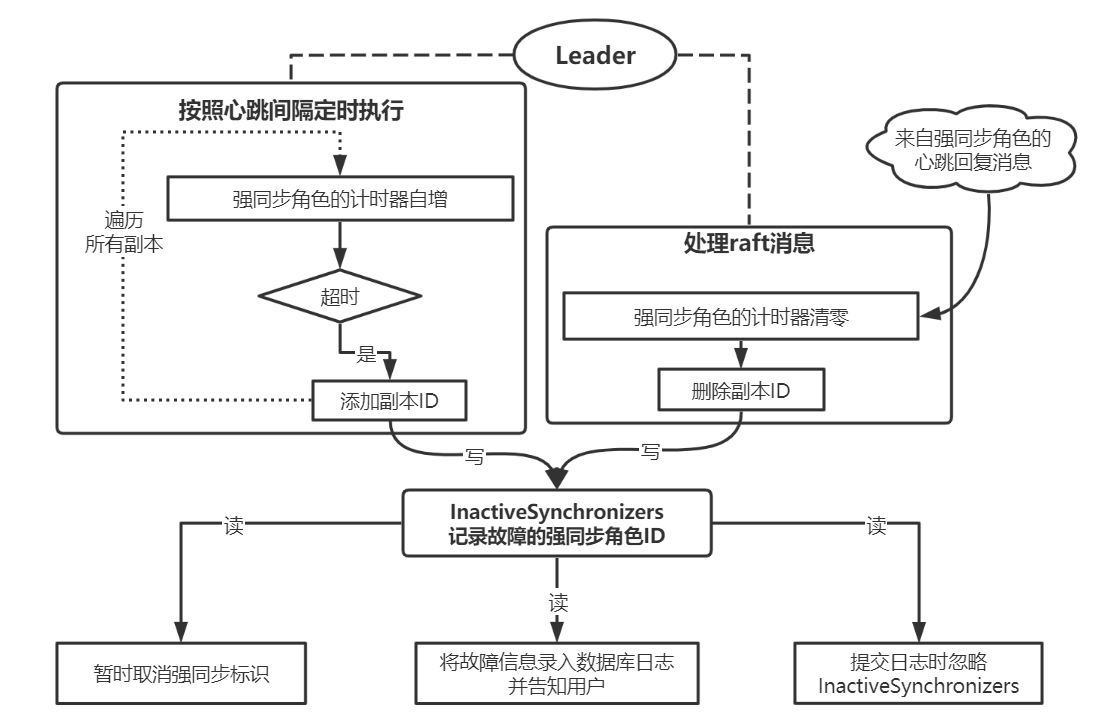
為強同步角色設計瞭如圖 2 所示的故障識別與處理機制:通過心跳超時機制識別強同步故障,提交日誌時忽略故障的強同步角色,並將故障資訊錄入資料庫日誌並告知使用者。
為強同步角色的心跳超時時間增加熱更新功能。

圖2 強同步角色的處理邏輯
經過以上四點改造後,etcd-raft 模組新增強同步角色,能夠實現如下功能:
允許使用者為指定副本配置或取消強同步角色,不影響強同步角色所在副本的原有特性。例如對全能型副本配置強同步角色後,該副本依然儲存 Raft 日誌和使用者資料,參與投票,參與 Leader 選舉,當選為 Leader 可提供讀寫服務,Follower 時可提供非一致性讀。
強同步角色的資料與 leader 保持同步。
允許使用者配置強同步角色的心跳超時時間。如果強同步角色發生故障,Raft 叢集將在該超時時間後恢復寫入功能,故障期間的寫入也會在超時時間後提交。Raft會在識別到強同步角色故障後暫時取消強同步標記,並在該強同步角色故障解決後自動恢復。強同步角色故障和恢復的資訊對使用者可見。
允許使用者在 SQL 終端查詢強同步角色的配置狀態。
2、只讀型角色
由於 ZNBase 具備 HTAP 的特性,因此需要在 Raft Group 中增加一種相對獨立的特殊副本,對外僅提供讀服務(例如將該類型副本的儲存引擎替換成列存引擎)以實現 OLAP 的功能。為了在 Raft Group 中增加這種特殊副本,同時不影響原有的叢集特性,ZNBase 研發團隊在 Raft 中設計了一種新的只讀型角色。
具體實現措施如下:
增加只讀型角色標識,增加只讀型角色的創建、刪除、重平衡邏輯。
增加只讀型副本接收到請求後讀取資料的邏輯:如果只讀型角色的時間戳不小於請求的時間戳,則提供讀服務;否則會重試多次,重試達到限制後會將讀取超時錯誤返回到 SQL 終端。
為只讀型副本的時間戳更新間隔、讀取時的最大重試次數等參數增加熱更新功能。
etcd-raft 模組新增只讀型角色後,能夠實現如下功能:
允許使用者在指定位置創建、刪除或移動只讀型角色。只讀型角色支援基於負載均衡的重平衡功能,移動到壓力相對較小的節點。
該角色對外僅提供讀服務,儲存 Raft 日誌和使用者資料,不參與投票,不參與 Leader 選舉,可提供讀服務。
允許使用者配置只讀型副本的時間戳更新間隔、讀取時的最大重試次數,可以用於對只讀型副本的讀取效能進行調優。
允許使用者在 SQL 終端查詢只讀型角色的配置情況。
3、日誌型角色
ZNBase 不支援在兩資料中心三副本部署模式下提供雙活模式,無論如何部署副本的位置,總有一個數據中心擁有過半數的副本。當擁有過半數副本的資料中心故障時,另一個數據中心由於所擁有的可用副本數不滿足過半數,會導致 ZNBase 無法對外正常提供服務。為解決此類問題,提高 ZNBase 的容災能力,同時充分利用和整合資源,避免出現資源閒置造成的浪費現象,提升雙活資料中心的服務能力,項目團隊在 etcd-raft 模組增加了日誌型角色。
具體實現措施如下:
日誌型副本參與 Leader 選舉,擁有投票權,並且可以成為 Leader。在普通副本缺少最新日誌的故障場景下,為了恢復叢集的可用性,需要日誌型副本當選為 Leader,並向其他副本追加日誌,使得該副本擁有最新的日誌。然後發起 Leader 轉移,擁有最新日誌的副本當選為 Leader 和 Leaseholder,完成叢集恢復。
日誌型副本不能傳送快照。由於日誌型副本不含使用者資料,若傳送快照將導致其他副本丟失資料,因此禁止日誌型副本傳送快照。
日誌型副本不能成為 LeaseHolder。禁止從日誌型副本讀取資料,且在日誌型副本成為Leader 的情況下,在其他副本擁有最新日誌後,將立即轉移 Leader 到該副本上。
日誌型副本保留日誌。日誌型副本的日誌可用於故障恢復,因此延長其日誌保留時間。原有的日誌清理策略為當可清理的日誌 index 數量大於等於 100 或實際大小大於等於 64KB 時,執行日誌清理操作。當出現節點宕機時,待清理的日誌超過 4MB 執行日誌清理操作。日誌型副本的日誌清理策略為:將日誌清理請求按小時打包、延遲處理,預設清理時間值為24,即將日誌清理請求延遲24小時處理,達到日誌保留的效果。使用者可配置清理時間值,可配置範圍是[-1, MaxInt],若配置為 -1 則表示不保留日誌,按照原來的邏輯執行清理操作。
日誌型副本異地重啟。日誌型副本異地重啟時會因嘗試提交心跳訊息攜帶的 Commit 值而宕機。修改 follower 處理心跳的邏輯,如果日誌型 follower 收到心跳訊息的 Commit 值比實際的 lastIndex 值大,就將心跳回復訊息的 Reject 欄位置為 true、RejectHint 欄位置為實際的 lastIndex。Leader 收到 Reject 為 true 的心跳回復訊息時,將對應 follower 副本 progress 的 Match 和 Next 更新為實際值,並向該副本追加日誌,將其丟失的日誌補全。
針對日誌型角色增加 Logonly 語法支援,使用 Alter 語句配置樣例如下,表 t 擁有 3 個副本,其中將 2 個全能型副本放在北京和濟南,日誌型副本放在天津:
ALTER TABLE t CONFIGURE ZONE USING num_replicas=2, num_logonlys=1, constraints='{"+region=beijing": 1,"+region=jinan": 1}', logonly_constraints='{"+region=tianjin":1}';以兩中心三副本(一個全能型、一個強同步、一個日誌型)模式進行部署為例,全能型副本與強同步副本分別存放在 DC-1 與 DC-2 的高配機器(或多數機器)中,日誌型副本存放在 DC-1 或 DC-2 的低配機器(或少量機器)中,日誌增量複製到另一個數據中心的低配機器(或少量機器)。若遭遇資料中心級別的故障,在失去兩個副本(一個全能型、一個日誌型)後,在另一個數據中心手動啟動存放日誌型副本的節點,該日誌型副本含有基於增量複製得到的日誌資料。

遭遇資料中心級別的故障時的容災處理(Node7 的日誌型副本需要手動重啟)
通過給 Raft 演算法增加 3 種新的角色,ZNBase 在跨地域叢集容災、支援 OLAP 等方面的能力得到了顯著加強。
小結
本文介紹了 Raft 一致性演算法在分散式 NewSQL 資料庫 ZNBase 中發揮的重要作用,以及 ZNBase 項目團隊根據自身業務特性與需求,在 Raft 演算法中新設計的三種角色,從而提高了 ZNBase 的異地容災和 HTAP 的能力。除了新增 Raft 角色以外,ZNBase 研發團隊還針對 Raft 模組做了新增 Leader 親和選舉、混合序列化、Raft Log 分離與定製儲存和 Raft 心跳與資料分離等優化改進,受篇幅限制,我們將在後續的文章中詳細解析這四大改進。
相關文章
作者:管延信導讀云溪資料庫 ZNBase 是由浪潮開源的一款 NewSQL 分散式資料庫,具備 HTAP 特性,擁有強一致、高可用的分散式架構。對於一個高可用的分散式系統來說,為了保障不同叢
2021-06-08 11:49:01

以3K-4K價位為例,這是目前除頂級旗艦以外,主打高效能的手機普遍都價位區間,並且相較於頂級旗艦機型,其在產品上的差異幾乎只存在於影像。也就是說,對影像能力並不是特別感興趣的
2021-06-08 11:48:22

科技產業的創新已經從粗放走向精細化,最前沿的科技產品和最專業的媒體洞見將聚焦CTIS 2021 消費科技及創新展覽會。首屆CTIS消費者科技及創新展覽會將於6月9日至11日登陸上海
2021-06-08 11:48:04

眼睛不太行了,準備買一款螢幕素質好點的手機,有不?隨著我們經常使用手機,我們越來越感受到對於我們眼睛的守護,確實非常的重要。所以擁有一款護眼的螢幕,更好的呵護我們的眼睛,真的
2021-06-08 11:29:27

出品|開源中國文|局長在剛剛結束的 WWDC2021 上,蘋果宣佈了 iOS 15、iPadOS 15 以及 macOS Monterey。具體的更新內容這裡不再重複,本文主要介紹幾個和開發者緊密相關的亮點。
2021-06-08 11:27:27
【TechWeb】6月8日訊息,據國外媒體報道,蘋果在全球開發者大會上公佈了針對iOS、iPadOS、watchOS、macOS等蘋果生態內系統的全面升級,其中macOS 12肩負著蘋果過渡到多平臺融合新
2021-06-08 11:27:03