引言Kubernetes 在生產環境應用的普及度越來越廣、複雜度越來越高,隨之而來的穩定性保障挑戰也越來越大。如何構建全面深入的可觀測性架構和體系,是提升系統穩定性的關鍵之因
2021-06-10 06:42:52
Kubernetes 在生產環境應用的普及度越來越廣、複雜度越來越高,隨之而來的穩定性保障挑戰也越來越大。
如何構建全面深入的可觀測性架構和體系,是提升系統穩定性的關鍵之因素一。ACK將可觀測性最佳實踐進行沉澱,以阿里雲產品功能的能力對使用者透出,可觀測性工具和服務成為基礎設施,賦能並幫助使用者使用產品功能,提升使用者 Kubernetes 叢集的穩定性保障和使用體驗。
本文會介紹 Kubernetes 可觀測性系統的構建,以及基於阿里云云產品實現 Kubernetes 可觀測系統構建的最佳實踐。
Kubernetes 系統對於可觀測性方面的挑戰包括:
K8s 系統架構的複雜性。系統包括控制面和資料面,各自包含多個相互通訊的元件,控制面和資料間之間通過 kube-apiserver 進行橋接聚合。
動態性。Pod、Service 等資源動態創建以及分配 IP,Pod 重建後也會分配新的資源和 IP,這就需要基於動態服務發現來獲取監測物件。
微服務架構。應用按照微服務架構分解成多個元件,每個元件副本數可以根據彈性進行自動或者人工控制。
針對 Kubernetes 系統可觀測性的挑戰,尤其在叢集規模快速增長的情況下,高效可靠的 Kubernetes 系統可觀測效能力,是系統穩定性保障的基石。
那麼,如何提升建設生產環境下的 Kubernetes 系統可觀測效能力呢?
Kubernetes 系統的可觀測性方案包括指標、日誌、鏈路追蹤、K8s Event 事件、NPD 框架等方式。每種方式可以從不同維度透視 Kubernetes 系統的狀態和資料。在生產環境,我們通常需要綜合使用各種方式,有時候還要運用多種方式聯動觀測,形成完善立體的可觀測性體系,提高對各種場景的覆蓋度,進而提升 Kubernetes 系統的整體穩定性。下面會概述生產環境下對 K8s 系統的可觀測性解決方案。
Prometheus 是業界指標類資料採集方案的事實標準,是開源的系統監測和報警框架,靈感源自 Google 的 Borgmon 監測系統。2012 年,SoundCloud 的 Google 前員工創造了 Prometheus,並作為社群開源項目進行開發。2015 年,該項目正式釋出。2016 年,Prometheus 加入 CNCF 雲原生計算基金會。
Prometheus 具有以下特性:
多維的資料模型(基於時間序列的 Key、Value 鍵值對)
靈活的查詢和聚合語言 PromQL
提供本地儲存和分散式儲存
通過基於 HTTP 的 Pull 模型採集時間序列資料
可利用 Pushgateway(Prometheus 的可選中介軟體)實現 Push 模式
可通過動態服務發現或靜態配置發現目標機器
支援多種圖表和資料大盤
Prometheus 可以週期性採集元件暴露在 HTTP(s) 端點的/metrics 下面的指標資料,並存儲到 TSDB,實現基於 PromQL 的查詢和聚合功能。
對於 Kubernetes 場景下的指標,可以從如下角度分類:
1. 容器基礎資源指標
採集源為 kubelet 內建的 cAdvisor,提供容器記憶體、CPU、網路、檔案系統等相關的指標,指標樣例包括:
容器當前記憶體使用位元組數 container_memory_usage_bytes;
容器網路接收位元組數 container_network_receive_bytes_total;
容器網路傳送位元組數 container_network_transmit_bytes_total,等等。
2. Kubernetes 節點資源指標
採集源為 node_exporter,提供節點系統和硬體相關的指標,指標樣例包括:節點總記憶體 node_memory_MemTotal_bytes,節點檔案系統空間 node_filesystem_size_bytes,節點網路介面 ID node_network_iface_id,等等。基於該類指標,可以統計節點的 CPU/記憶體/磁碟使用率等節點級別指標。
3. Kubernetes 資源指標
採集源為 kube-state-metrics,基於 Kubernetes API 物件生成指標,提供 K8s 叢集資源指標,例如 Node、ConfigMap、Deployment、DaemonSet 等類型。以 Node 類型指標為例,包括節點 Ready 狀態指標 kube_node_status_condition、節點資訊kube_node_info 等等。
4. Kubernetes 元件指標
Kubernetes 系統元件指標。 例如 kube-controller-manager, kube-apiserver,kube-scheduler, kubelet,kube-proxy、coredns 等。
Kubernetes 運維元件指標。 可觀測類包括 blackbox_operator, 實現對使用者自定義的探活規則定義;gpu_exporter,實現對 GPU 資源的透出能力。
Kubernetes 業務應用指標。 包括具體的業務 Pod在/metrics 路徑透出的指標,以便外部進行查詢和聚合。
除了上述指標,K8s 提供了通過 API 方式對外透出指標的監測介面標準,具體包括 Resource Metrics,Custom Metrics 和 External Metrics 三類。

Resource Metrics 類對應介面 metrics.k8s.io,主要的實現就是 metrics-server,它提供資源的監測,比較常見的是節點級別、pod 級別、namespace 級別。這些指標可以通過 kubectl top 直接訪問獲取,或者通過 K8s controller 獲取,例如 HPA(Horizontal Pod Autoscaler)。系統架構以及訪問鏈路如下:

Custom Metrics 對應的 API 是 custom.metrics.k8s.io,主要的實現是 Prometheus。它提供的是資源監測和自定義監測,資源監測和上面的資源監測其實是有覆蓋關係的,而這個自定義監測指的是:比如應用上面想暴露一個類似像線上人數,或者說呼叫後面的這個資料庫的 MySQL 的慢查詢。這些其實都是可以在應用層做自己的定義的,然後並通過標準的 Prometheus 的 client,暴露出相應的 metrics,然後再被 Prometheus 進行採集。
而這類的介面一旦採集上來也是可以通過類似像 custom.metrics.k8s.io 這樣一個介面的標準來進行資料消費的,也就是說現在如果以這種方式接入的 Prometheus,那你就可以通過 custom.metrics.k8s.io 這個介面來進行 HPA,進行資料消費。系統架構以及訪問鏈路如下:

External Metrics 。因為我們知道 K8s 現在已經成為了雲原生介面的一個實現標準。很多時候在雲上打交道的是雲服務,比如說在一個應用裡面用到了前面的是訊息佇列,後面的是 RBS 資料庫。那有時在進行資料消費的時候,同時需要去消費一些雲產品的監測指標,類似像訊息佇列中訊息的數目,或者是接入層 SLB 的 connection 數目,SLB 上層的 200 個請求數目等等,這些監測指標。
那怎麼去消費呢?也是在 K8s 裡面實現了一個標準,就是 external.metrics.k8s.io。主要的實現廠商就是各個雲廠商的 provider,通過這個 provider 可以通過雲資源的監測指標。在阿里雲上面也實現了阿里巴巴 cloud metrics adapter 用來提供這個標準的 external.metrics.k8s.io 的一個實現。
概要來說包括:
主機核心的日誌。主機核心日誌可以協助開發者診斷例如:網路棧異常,驅動異常,檔案系統異常,影響節點(核心)穩定的異常。
Runtime 日誌。最常見的運行時是 Docker,可以通過 Docker 的日誌排查例如刪除 Pod Hang 等問題。
K8s 元件日誌。APIServer 日誌可以用來審計,Scheduler 日誌可以診斷排程,etcd 日誌可以檢視儲存狀態,Ingress 日誌可以分析接入層流量。
應用日誌。可以通過應用日誌分析檢視業務層的狀態,診斷異常。 日誌的採集方式分為被動採集和主動推送兩種,在 K8s 中,被動採集一般分為 Sidecar 和 DaemonSet 兩種方式,主動推送有 DockerEngine 推送和業務直寫兩種方式。
DockerEngine 本身具有 LogDriver 功能,可通過配置不同的 LogDriver 將容器的 stdout 通過 DockerEngine 寫入到遠端儲存,以此達到日誌採集的目的。這種方式的可定製化、靈活性、資源隔離性都很低,一般不建議在生產環境中使用;
業務直寫是在應用中整合日誌採集的 SDK,通過 SDK 直接將日誌傳送到服務端。這種方式省去了落盤採集的邏輯,也不需要額外部署 Agent,對於系統的資源消耗最低,但由於業務和日誌 SDK 強繫結,整體靈活性很低,一般只有日誌量極大的場景中使用;
DaemonSet 方式在每個 node 節點上只運行一個日誌 agent,採集這個節點上所有的日誌。DaemonSet 相對資源佔用要小很多,但擴展性、租戶隔離性受限,比較適用於功能單一或業務不是很多的叢集;
Sidecar 方式為每個 POD 單獨部署日誌 agent,這個 agent 只負責一個業務應用的日誌採集。Sidecar 相對資源佔用較多,但靈活性以及多租戶隔離性較強,建議大型的 K8s 叢集或作為 PaaS 平臺為多個業務方服務的叢集使用該方式。
掛載宿主機採集、標準輸入輸出採集、Sidecar 採集。

總結下來:
DockerEngine 直寫一般不推薦;
業務直寫推薦在日誌量極大的場景中使用;
DaemonSet 一般在中小型叢集中使用;
Sidecar 推薦在超大型的叢集中使用。
事件監測是適用於 Kubernetes 場景的一種監測方式。事件包含了發生的時間、元件、等級(Normal、Warning)、類型、詳細資訊,通過事件我們能夠知道應用的部署、排程、運行、停止等整個生命週期,也能通過事件去了解系統中正在發生的一些異常。
K8s 中的一個設計理念,就是基於狀態機的一個狀態轉換。從正常的狀態轉換成另一個正常的狀態的時候,會發生一個 Normal 的事件,而從一個正常狀態轉換成一個異常狀態的時候,會發生一個 Warning 的事件。通常情況下,Warning 的事件是我們比較關心的。事件監測就是把 Normal 的事件或者是 Warning 事件匯聚到資料中心,然後通過資料中心的分析以及報警,把相應的一些異常通過像釘釘、簡訊、郵件等方式進行暴露,實現與其他監測的補充與完善。
Kubernetes中的事件是儲存在 etcd 中,預設情況下只儲存 1 個小時,無法實現較長週期範圍的分析。將事件進行長期儲存以及定製化開發後,可以實現更加豐富多樣的分析與告警:
對系統中的異常事件做實時告警,例如 Failed、Evicted、FailedMount、FailedScheduling 等。
通常問題排查可能要去查詢歷史資料,因此需要去查詢更長時間範圍的事件(幾天甚至幾個月)。
事件支援歸類統計,例如能夠計算事件發生的趨勢以及與上一時間段(昨天/上週/釋出前)對比,以便基於統計指標進行判斷和決策。
支援不同的人員按照各種維度去做過濾、篩選。
支援自定義的訂閱這些事件去做自定義的監測,以便和公司內部的部署運維平臺整合。
Kubernetes 叢集及其運行容器的穩定性,強依賴於節點的穩定性。 Kubernetes 中的相關元件只關注容器管理相關的問題,對於硬體、作業系統、容器運行時、依賴系統(網路、儲存等)並不會提供更多的檢測能力。NPD(Node Problem Detector)針對節點的穩定性提供了診斷檢查框架,在預設檢查策略的基礎上,可以靈活擴展檢查策略,可以將節點的異常轉換為 Node 的事件,推送到 APIServer 中,由同一的 APIServer 進行事件管理。
NPD 支援多種異常檢查,例如:
基礎服務問題:NTP 服務未啟動
硬體問題:CPU、記憶體、磁碟、網卡損壞
Kernel 問題:Kernel hang,檔案系統損壞
容器運行時問題:Docker hang,Docker 無法啟動
資源問題:OOM 等

綜上,本章節總結了常見的 Kubernetes 可觀測性方案。在生產環境,我們通常需要綜合使用各種方案,形成立體多維度、相互補充的可觀測性體系;可觀測性方案部署後,需要基於上述方案的輸出結果快速診斷異常和錯誤,有效降低誤報率,並有能力儲存、回查以及分析歷史資料;進一步延伸,資料可以提供給機器學習以及 AI 框架,實現彈性預測、異常診斷分析、智慧運維 AIOps 等高階應用場景。
這需要可觀測性最佳實踐作為基礎,包括如何設計、插件化部署、配置、升級上述各種可觀測性方案架構,如何基於輸出結果快速準確診斷分析跟因等等。阿里雲容器服務 ACK 以及相關雲產品(監測服務 ARMS、日誌服務 SLS 等),將雲廠商的最佳實踐通過產品化能力實現、賦能使用者,提供了完善全面的解決方案,可以讓使用者快速部署、配置、升級、掌握阿里雲的可觀測性方案,顯著提升了企業上雲和雲原生化的效率和穩定性、降低技術門檻和綜合成本。
下面將以 ACK 最新的產品形態 ACK Pro 為例,結合相關雲產品,介紹 ACK 的可觀測性解決方案和最佳實踐。
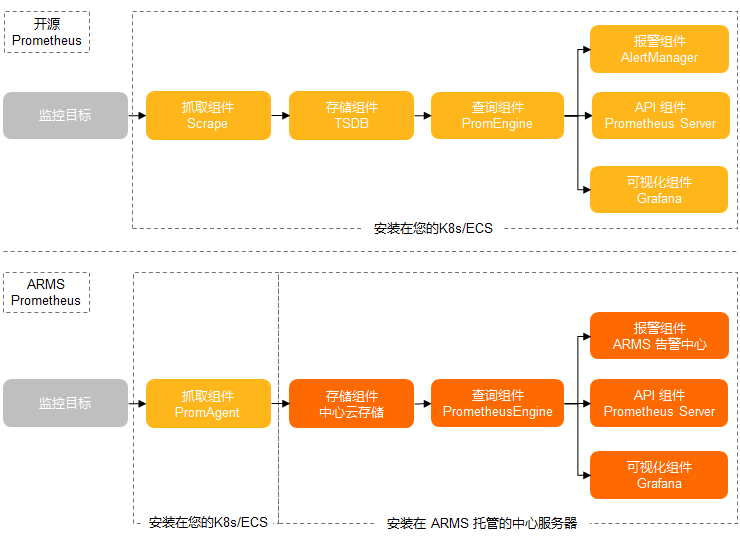
對於指標類可觀測性,ACK 可以支援開源 Prometheus 監測和阿里雲 Prometheus 監測(阿里雲 Prometheus 監測是 ARMS 產品子產品)兩種可觀測性方案。
開源 Prometheus 監測,以 helm 包形式提供、適配阿里雲環境、集成了釘釘告警、儲存等功能;部署入口在控制檯的應用目錄中 ack-prometheus-operator,使用者配置後可以在 ACK 控制檯一鍵部署。使用者只需要在阿里雲 ACK 控制檯配置 helm 包參數,就可以定製化部署。

阿里雲 Prometheus監測,是 ARMS 產品子產品。應用實時監測服務 (Application Real-Time Monitoring Service, 簡稱 ARMS) 是一款應用效能管理產品,包含前端監測,應用監測和 Prometheus 監測三大子產品。
在 2021 年的 Gartner 的 APM 魔力象限評測中,阿里雲應用實時監測服務(ARMS)作為阿里雲 APM 的核心產品,聯合雲監測以及日誌服務共同參與。Gartner 評價阿里雲 APM:
中國影響力最強:阿里雲是中國最大的雲服務提供商,阿里雲使用者可以使用雲上監測工具來滿足其可觀測性需求。
開源整合:阿里雲非常重視將開源標準和產品(例如 Prometheus)整合到其平臺中。
成本優勢:與在阿里雲上使用第三方 APM 產品相比,阿里雲 APM 產品具有更高的成本效益。
下圖概要對比了開源 Prometheus 和阿里雲 Prometheus 的模組劃分和資料鏈路。

ACK 支援 CoreDNS、叢集節點、叢集概況等 K8s 可觀測效能力;除此之外,ACK Pro 還支援託管的管控元件 Kube API Server、Kube Scheduler 和 Etcd 的可觀測效能力,並持續迭代。使用者可以通過在阿里雲 Prometheus 中豐富的監測大盤,結合告警能力,快速發現 K8s 叢集的系統問題以及潛在風險,及時採取相應措施以保障叢集穩定性。監測大盤集成了 ACK 最佳實踐的經驗,可以幫助使用者從多維度分析分析、定位問題。下面介紹如何基於最佳實踐設計可觀測性大盤,並列舉使用監測大盤定位問題的具體案例,幫助理解如何使用可觀測效能力。
首先來看 ACK Pro 的可觀測效能力。監測大盤入口如下:

APIServer 是 K8s 核心元件之一,是 K8s 元件進行互動的樞紐,ACK Pro APIServer 的監測大盤設計考慮到使用者可以選擇需要監測的 APIServer Pod 來分析單一指標、聚合指標以及請求來源等,同時可以下鑽到某一種或者多種 API 資源聯動觀測 APIServer 的指標,這樣的優勢是既可以全局觀測全部 APIServer Pod 的全局檢視,又可以下鑽觀測到具體 APIServer Pod 以及具體 API 資源的監測,監測全部和局部觀測能力,對於定位問題非常有效。所以根據 ACK 的最佳實踐,實現上包含了如下 5 個模組:
提供 APIServer Pod、API 資源(Pods,Nodes,ConfigMaps 等)、分位數(0.99,0.9,0.5)、統計時間間隔的篩選框,使用者通過控制篩選框,可以聯動控制監測大盤實現聯動
凸顯關鍵指標以便識別系統關鍵狀態
展示 APIServer RT、QPS 等單項指標的監測大盤,實現單一維度指標的觀測
展示 APIServer RT、QPS 等聚合指標的監測大盤,實現多維度指標的觀測
展示對 APIServer 訪問的客戶端來源分析,實現訪問源的分析
下面概要介紹模組的實現。

顯示了核心的指標,包括 APIServer 總 QPS、讀請求成功率、寫請求成功率、Read Inflight Request、Mutating Inflight Request 以及單位時間丟棄請求數量 Dropped Requests Rate。
這些指標可以概要展示系統狀態是否正常,例如如果 Dropped Requests Rate 不為 NA,說明 APIServer 因為處理請求的能力不能滿足請求出現丟棄請求,需要立即定位處理。

包括讀非 LIST 讀請求 RT、LIST 讀請求 RT、寫請求 RT、讀請求 Inflight Request、修改請求 Inflight Request 以及單位時間丟棄請求數量,該部分大盤的實現結合了 ACK 最佳實踐經驗。
對於響應時間的可觀測性,可以直觀的觀察到不同時間點以及區間內,針對不同資源、不同操作、不同範圍的響應時間。可以選擇不同的分位數,來篩選。有兩個比較重要的考察點:
曲線是否連續
RT 時間
先來解釋曲線的連續性。通過曲線的連續性,可以很直觀的看出請求是持續的請求,還是單一的請求。
下圖表示在取樣週期內,APIServer 收到 PUT leases 的請求,每個取樣期內 P90 RT 是 45ms。
因為圖中曲線是連續,說明該請求在全部取樣週期都存在,所以是持續的請求。

下圖表示在取樣週期內,APIServer 收到 LIST daemonsets 的請求,有樣值的取樣週期內 P90 RT 是 45ms。 因為圖中只有一次,說明該請求只是在一次取樣週期存在。該場景來自於使用者執行 kubectl get ds --all-namespaces 產生的請求記錄。
 再來解釋曲線體現的 RT。
再來解釋曲線體現的 RT。
使用者執行命令創建 1MB 的 configmap,請求連線到公網 SLBkubectl create configmap cm1MB --from-file=cm1MB=./configmap.file
APIServer 記錄的日誌中,該次請求 POST configmaps RT 為 9.740961791s,該值可以落入 apiserver_request_duration_seconds_bucket 的(8, 9]區間,所以會在 apiserver_request_duration_seconds_bucket 的 le=9 對應的 bucket 中增加一個樣點,可觀測性展示中按照 90 分位數,計算得到 9.9s 並圖形化展示。這就是日誌中記錄的請求真實RT與可觀測性展示中的展示 RT 的關聯關係。
所以監測大盤既可以與日誌可觀測功能聯合使用,又可以直觀概要的以全局檢視展示日誌中的資訊,最佳實踐建議結合監測大盤和日誌可觀測性做綜合分析。


下面解釋一下RT與請求的具體內容以及叢集規模有直接的關聯。
在上述創建 configmap 的例子中,同樣是創建 1MB 的 configmap,公網鏈路受網路頻寬和時延影響,達到了 9s;而在內網鏈路的測試中,只需要 145ms,網路因素的影響是顯著的。
所以 RT 與請求操作的資源物件、位元組尺寸、網路等有關聯關係,網路越慢,位元組尺寸越大,RT 越大。
對於大規模 K8s 叢集,全量 LIST(例如 pods,nodes 等資源)的資料量有時候會很大,導致傳輸資料量增加,也會導致 RT 增加。所以對於 RT 指標,沒有絕對的健康閾值,一定需要結合具體的請求操作、叢集規模、網路頻寬來綜合評定,如果不影響業務就可以接受。
對於小規模 K8s 叢集,平均 RT 45ms 到 100ms 是可以接受的;對於節點規模上 100 的叢集,平均 RT 100ms 到 200ms 是可以接受的。
但是如果 RT 持續達到秒級,甚至 RT 達到 60s 導致請求超時,多數情況下出現了異常,需要進一步定位處理是否符合預期。
這兩個指標通過 APIServer /metrics 對外透出,可以執行如下命令檢視 inflight requests,是衡量 APIServer 處理併發請求能力的指標。如果請求併發請求過多達到 APIServer 參數 max-requests-inflight和 max-mutating-requests-inflight 指定的閾值,就會觸發 APIServer 限流。通常這是異常情況,需要快速定位並處理。

該部分可以直觀顯示請求 QPS 以及 RT 按照 Verb、API 資源進行分類的情況,以便進行聚合分析。還可以展示讀、寫請求的錯誤碼分類,可以直觀發現不同時間點下請求返回的錯誤碼類型。
 該部分可以直觀顯示請求的客戶端以及操作和資源。
該部分可以直觀顯示請求的客戶端以及操作和資源。
QPS By Client 可以按客戶端維度,統計不同客戶端的QPS值。
QPS By Verb + Resource + Client 可以按客戶端、Verb、Resource 維度,統計單位時間(1s)內的請求分佈情況。
基於 ARMS Prometheus,除了 APIServer 大盤,ACK Pro 還提供了 Etcd 和 Kube Scheduler 的監測大盤;ACK 和 ACK Pro 還提供了 CoreDNS、K8s 叢集、K8s 節點、Ingress 等大盤,這裡不再一一介紹,使用者可以檢視 ARMS 的大盤。這些大盤結合了 ACK 和 ARMS 的在生產環境的最佳實踐,可以幫助使用者以最短路徑觀測系統、發現問題根源、提高運維效率。
SLS 阿里雲日誌服務是阿里雲標準的日誌方案,對接各種類型的日誌儲存。 對於託管側元件的日誌,ACK 支援託管叢集控制平面元件(kube-apiserver/kube-controller-manager/kube-scheduler)日誌透出,將日誌從 ACK 控制層採集到到使用者 SLS 日誌服務的 Log Project 中。
對於使用者側日誌,使用者可以使用阿里雲的 logtail、log-pilot 技術方案將需要的容器、系統、節點日誌收集到 SLS 的 logstore,隨後就可以在 SLS 中方便的檢視日誌。


Kubernetes 的架構設計基於狀態機,不同的狀態之間進行轉換則會生成相應的事件,正常的狀態之間轉換會生成 Normal 等級的事件,正常狀態與異常狀態之間的轉換會生成 Warning 等級的事件。
ACK 提供開箱即用的容器場景事件監測方案,通過 ACK 維護的 NPD(node-problem-detector)以及包含在 NPD 中的 kube-eventer 提供容器事件監測能力。
NPD(node-problem-detector)是 Kubernetes 節點診斷的工具,可以將節點的異常,例如 Docker Engine Hang、Linux Kernel Hang、網路出網異常、檔案描述符異常轉換為 Node 的事件,結合 kube-eventer 可以實現節點事件告警的閉環。
kube-eventer 是 ACK 維護的開源 Kubernetes 事件離線工具,可以將叢集的事件離線到釘釘、SLS、EventBridge 等系統,並提供不同等級的過濾條件,實現事件的實時採集、定向告警、非同步歸檔。
NPD 根據配置與第三方插件檢測節點的問題或故障,生成相應的叢集事件。而Kubernetes叢集自身也會因為叢集狀態的切換產生各種事件。例如 Pod 驅逐,映象拉取失敗等異常情況。日誌服務 SLS(Log Service)的 Kubernetes 事件中心實時匯聚 Kubernetes 中的所有事件並提供儲存、查詢、分析、視覺化、告警等能力。

ACK 以及相關雲產品對 Kubernetes 叢集已經實現了全面的觀測能力,包括指標、日誌、鏈路追蹤、事件等。後面發展的方向包括:
挖掘更多應用場景,將應用場景與可觀測性關聯,幫助使用者更好的使用K8s。例如監測一段時間內 Pod 中容器的記憶體/CPU 等資源水位,利用歷史資料分析使用者的Kubernets 容器資源 requests/limits 是否合理,如果不合理給出推薦的容器資源 requests/limits;監測叢集 APIServer RT 過大的請求,自動分析異常請求的原因以及處理建議;
聯動多種可觀測性技術方案,例如K8s事件和指標監測,提供更加豐富和更多維度的可觀測效能力。
我們相信 ACK 可觀測性未來的發展方向會越來越廣闊,給客戶帶來越來越出色的技術價值和社會價值!
相關文章
引言Kubernetes 在生產環境應用的普及度越來越廣、複雜度越來越高,隨之而來的穩定性保障挑戰也越來越大。如何構建全面深入的可觀測性架構和體系,是提升系統穩定性的關鍵之因
2021-06-10 06:42:52

【CNMO新聞】6月2日晚,全球首款搭載HarmonyOS 2的平板電腦——華為MatePad Pro 12.6英寸正式釋出,產品一經發布便受到了諸多網友的關注,不論是硬體配置還是HarmonyOS的特性,亦或
2021-06-10 06:19:45

這次應小夥伴的要求,來總結下這個 MySQL 主要版本的新特性那麼,我們一起往下看看叭~我們直接來到官網檢視可以看到這裡有三個版本 5.6 , 5.7 , 8.0額 既然 5.5 找不到了,那我們就
2021-06-10 06:19:33

如今,選購一款能夠暢爽遊戲的手機已經成為一種「流行」,自然是因為手機遊戲已經成為了人們碎片化時間消遣的快捷方式,加上手機遊戲的質量不斷提高,選擇一款能夠流暢運行遊戲的手
2021-06-10 06:18:04
開源項目 OpenHarmony 是什麼一圖勝萬語,開發者拿到OpenHarmony 2.0程式碼後跑起來的樣子OpenHarmony是自主研發、不相容安卓的全領域下一代開源作業系統。開放原子開源基金
2021-06-10 05:58:52

三駕馬車拉動半導體市場本月初三星、臺積電等晶片製造廠已經相繼發出公告,稱由於供需關係、產能等一系列問題,晶片、感測器等出貨價將上漲15%-40%。2021年剛剛開年行業就傳來
2021-06-10 05:34:02