機器之心報道編輯:小舟、陳萍通用人工智慧,用強化學習的獎勵機制就能實現嗎?幾十年來,在人工智慧領域,電腦科學家設計並開發了各種複雜的機制和技術,以復現視覺、語言、推理、運動
2021-06-10 14:47:17
機器之心報道
編輯:小舟、陳萍
通用人工智慧,用強化學習的獎勵機制就能實現嗎?
幾十年來,在人工智慧領域,電腦科學家設計並開發了各種複雜的機制和技術,以復現視覺、語言、推理、運動技能等智慧能力。儘管這些努力使人工智慧系統在有限的環境中能夠有效地解決特定的問題,但卻尚未開發出與人類和動物一般的智慧系統。
人們把具備與人類同等智慧、或超越人類的人工智慧稱為通用人工智慧(AGI)。這種系統被認為可以執行人類能夠執行的任何智慧任務,它是人工智慧領域主要研究目標之一。關於通用人工智慧的探索正在不斷髮展。近日強化學習大佬 David Silver、Richard Sutton 等人在一篇名為《Reward is enough》的論文中提出將智慧及其相關能力理解為促進獎勵最大化。

論文地址:https://www.sciencedirect.com/science/article/pii/S0004370221000862
該研究認為獎勵足以驅動自然和人工智慧領域所研究的智慧行為,包括知識、學習、感知、社交智慧、語言、泛化能力和模仿能力,並且研究者認為藉助獎勵最大化和試錯經驗就足以開發出具備智慧能力的行為。因此,他們得出結論:強化學習將促進通用人工智慧的發展。
AI 的兩條路徑
創建 AI 的一種常見方法是嘗試在計算機中複製智慧行為的元素。例如,我們對哺乳動物視覺系統的理解催生出各種人工智慧系統,這些系統可以對影象進行分類、定位照片中的物體、定義物體的邊界等。同樣,我們對語言的理解也幫助開發了各種自然語言處理系統,比如問答、文字生成和機器翻譯。
但這些都是狹義人工智慧的例項,只是被設計用來執行特定任務的系統,而不具有解決一般問題的能力。一些研究者認為,組裝多個狹義人工智慧模組將產生更強大的智慧系統,以解決需要多種技能的複雜問題。
而在該研究中,研究者認為創建通用人工智慧的方法是重新創建一種簡單但有效的規則。該研究首先提出假設:獎勵最大化這一通用目標,足以驅動自然智慧和人工智慧中至少大部分的智慧行為。」
這基本上就是大自然自身的運作方式。數十億年的自然選擇和隨機變異讓生物不斷進化。能夠應對環境挑戰的生物才能得以生存和繁殖,其餘的則被淘汰。這種簡單而有效的機制促使生物進化出各種技能和能力來感知、生存、改變環境,以及相互交流。
研究者說:「人工智慧體未來所面臨的環境和動物與人類面臨的自然世界一樣,本質上是如此複雜,以至於它們需要具備複雜的能力才能在這些環境中成功生存。」因此,以獎勵最大化來衡量的成功,需要智慧體表現出相關的智慧能力。從這個意義上說,獎勵最大化的一般目標包含了許多甚至可能是所有的智慧目標。並且,研究者認為最大化獎勵最普遍和可擴展的方式是藉助與環境互動學習的智慧體。
獎勵就足夠了
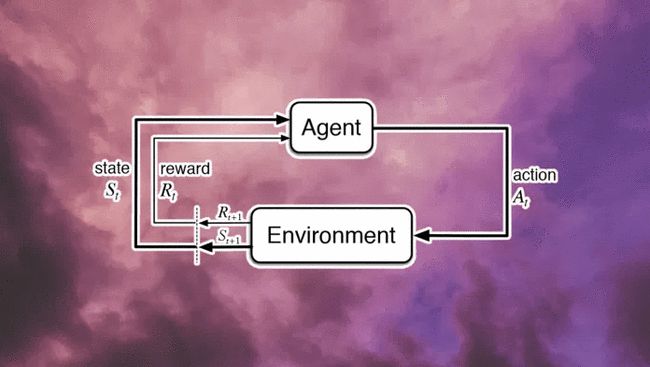
與人工智慧的許多互動式方法一樣,強化學習遵循一種協議,將問題分解為兩個隨時間順序互動的系統:做出決策的智慧體(解決方案)和受這些決策影響的環境(問題)。這與其他專用協議形成對比,其他專用協議可能考慮多個智慧體、多個環境或其他互動模式。
基於強化學習的思想,該研究認為獎勵足以表達各種各樣的目標。智慧的多種形式可以被理解為有利於對應的獎勵最大化,而與每種智慧形式相關的能力能夠在追求獎勵的過程中隱式產生。因此該研究假設所有智慧及相關能力可以理解為一種假設:「獎勵就足夠了」。智慧及其相關的能力,可以理解為智慧體在其環境中的行為獎勵最大化。
這一假設很重要,因為如果它是正確的,那麼一個獎勵最大化智慧體在服務於其實現目標的過程中,就可以隱式地產生與智慧相關的能力,具備出色智慧能力的智慧體將能夠「適者生存」。研究者從以下幾個方面論述了「獎勵就足夠了」這一假設。

知識和學習
該研究將知識定義為智慧體內部資訊,例如,知識可以包含於用於選擇動作、預測累積獎勵或預測未來觀測特徵的函數參數中。有些知識是先驗知識,有些知識是通過學習獲得的。獎勵最大化的智慧體將根據環境情況包含前者,例如藉助自然智慧體的進化和人工智慧體的設計,並通過學習獲取後者。隨著環境的不斷豐富,需求的平衡將越來越傾向於學習知識。
感知
人類需要各種感知能力來積累獎勵,例如分辨朋友和敵人,開車時進行場景解析等。這可能需要多種感知模式,包括視覺、聽覺、嗅覺、軀體感覺和本體感覺。
相比於監督學習,從獎勵最大化的角度考慮感知,最終可能會支援更廣泛的感知行為,包括如下具有挑戰性和現實形式的感知能力:
動作和觀察通常交織在多種感知形式中,例如觸覺感知、視覺掃視、物理實驗、回聲定位等;感知的效用通常取決於智慧體的行為;獲取資訊可能具有顯式和隱式成本;資料的分佈通常依賴於上下文,在豐富的環境中,潛在資料多樣性可能遠遠超過智慧體的容量或已存在資料的數量——這需要從經驗中獲取感知;感知的許多應用程式無法獲得有標記的資料。
社交智慧
社交智慧是一種理解其他智慧體並與之有效互動的能力。根據該研究的假設,社交智慧可以被理解為在智慧體環境中的某一智慧體最大化累積獎勵。按照這種標準智慧體 - 環境協議,一個智慧體觀察其他智慧體的行為,並可能通過自身行為影響其他智慧體,就像它觀察和影響環境的其他方面一樣。一個能夠預測和影響其他智慧體行為的智慧體通常可以獲得更大的累積獎勵。因此,如果一個環境需要社交智慧(例如包含動物或人類的環境),獎勵最大化將能夠產生社交智慧。
語言
語言一直是自然和人工智慧領域大量研究的一個主題。由於語言在人類文化和互動中起著主導作用,智慧本身的定義往往以理解和使用語言的能力為前提,尤其是自然語言。
然而,當前的語言建模本身不足以產生更廣泛的與智慧相關的語言能力,包括:
語言通常是上下文相關的,不僅與所說的內容相關,還與智慧體周圍環境中正在發生的其他事情有關,有時需要通過視覺和其他感官模式感知。此外,語言經常穿插其他表達行為,例如手勢、面部表情、音調變化等。語言是有目的並能對環境產生影響的。例如,銷售人員學習調整他們的語言以最大化銷售額。語言的具體含義和效用因智慧體的情況和行為而異。例如,礦工可能需要有關岩石穩定性的語言,農民可能需要有關土壤肥力的語言。此外,語言可能存在機會成本,例如討論農業的人並不一定是從事農業工作)。在豐富的環境中,語言處理不可預見事件的潛在用途可能超出任何語料庫的能力。在這些情況下,可能需要通過經驗動態地解決語言問題。例如開發一項新技術或找到一種方法來解決一個新的問題。
該研究認為基於「獎勵就足夠了」的假設,豐富的語言能力,包括所有這些更廣泛的能力,都應該源於對獎勵的追求。
泛化
泛化能力通常被定義為將一個問題的解決方案轉換為另一個問題的解決方案的能力。例如,在監督學習中,泛化可能專注於將從一個數據集(例如照片)學到的解決方案轉移到另一個數據集(例如繪畫)。
根據該研究的假設,泛化可以通過在智慧體和單個複雜環境之間的持續互動流中最大化累積獎勵來實現,這同樣遵循標準的智慧體 - 環境協議。人類世界等環境需要泛化,因為智慧體在不同的時間會面對環境的不同方面。例如,一隻吃水果的動物可能每天都會遇到一棵新樹,這個動物也可能會受傷、遭受乾旱或面臨入侵物種。在每種情況下,動物都必須通過泛化過去狀態的經驗來快速適應新狀態。動物面臨的不同狀態並沒有被整齊地劃分為具有不同標籤的任務。相反,狀態取決於動物的行為,它可能結合了在不同時間尺度上重複出現的各種元素,可以觀察到狀態的重要方面。豐富的環境同樣需要智慧體從過去的狀態泛化到未來的狀態,以及所有相關的複雜性,以便有效地積累獎勵。
模仿
模仿是與人類和動物智慧相關的一種重要能力,它可以幫助人類和動物快速獲得其他能力,例如語言、知識和運動技能。在人工智慧中,模仿通常被表述為通過行為克隆,從演示中學習,並提供有關教師行為、觀察和獎勵的明確資料時。相比之下,觀察學習的自然能力包括從觀察到的其他人類或動物的行為中進行的任何形式的學習,並且不要求直接訪問教師的行為、觀察和獎勵。這表明,與通過行為克隆的直接模仿相比,在複雜環境中可能需要更廣泛和現實的觀察學習能力,包括:
其他智慧體可能是智慧體的環境的組成部分(例如嬰兒觀察其母親),而無需假設存在包含教師資料的特殊資料集;智慧體可能需要學習它自己的狀態與另一個智慧體的狀態之間的關聯,或者智慧體自己的動作和另一個智慧體的觀察結果,這可能會產生更高的抽象級別;其他智慧體可能只能被部分觀察到,因此他們的行為或目標可能只是被不完美地推斷出來;其他智慧體可能會表現出應避免的不良行為;環境中可能有許多其他智慧體,表現出不同的技能或不同的能力水平。
該研究認為這些更廣泛的觀察學習能力能夠由獎勵最大化驅動的,從單個智慧體的角度來看,它只是將其他智慧體視為其環境的組成部分,這可能會帶來許多與行為克隆相同的好處。例如樣本高效的知識獲取,但這需要更廣泛和更綜合的背景下。
通用智慧
基於該研究的假設,通用智慧可以理解為通過在單一複雜的環境中最大化一個特殊獎勵來實現。例如,自然智慧在其整個生命週期中都面向從與自然世界的互動中產生的連續經驗流。動物的經驗流足夠豐富和多樣,它可能需要靈活的能力來實現各種各樣的子目標(例如覓食、戰鬥、逃跑等),以便成功地最大化其整體獎勵(例如飢餓或繁殖) 。類似地,如果人工智慧體的經驗流足夠豐富,那麼單一目標(例如電池壽命或生存)可能隱含地需要實現同樣廣泛的子目標的能力,因此獎勵最大化應該足以產生一種通用人工智慧。
強化學習智慧體
該研究的主要假設是智慧及其相關能力可以被理解為促進獎勵最大化,這與智慧體的性質無關。因此,如何構建最大化獎勵的智慧體是一個重要問題。該研究認為這個問題同樣可以通過問題本身,即「獎勵最大化」來回答。具體來說,研究者設想了一種具有一般能力的智慧體,然後從他們與環境互動的持續經驗中學習如何最大化獎勵。這種智慧體,被稱之為強化學習智慧體。

在所有可能的最大化獎勵的解決方法中,最自然的方法當然是通過與環境互動,從經驗中學習。隨著時間的推移,這種互動體驗提供了大量關於因果關係、行為後果以及如何積累獎勵的資訊。與其預先確定智慧體的行為(相信設計者對環境的預知),不如賦予智慧體發現自己行為的一般能力(相信經驗)是很自然的。更具體地說,最大化獎勵的設計目標是通過從經驗中學習最大化獎勵的行為的持續內部過程來實現的。
獎勵真的足夠了嗎?
對於該研究「獎勵就足夠了」的觀點,有網友表示不贊成:「這似乎是對個人效用函數這一共同概念的重新語境化。所有生物都有效用函數,他們的目標是最大化他們的個人效用。效用理論有著深厚而豐富的歷史淵源,但本文對效用理論的認識並不多見。Silver 和 Sutton 都是 RL 領域的大牛,但對我而言,這篇論文給我的感覺很糟糕。」
還有網友認為這是重新包裝進化論:
如此優秀的兩位電腦科學家這是在重新包裝進化論?這裡的實際意義是什麼?如果有足夠的時間和複雜性,進化(獎勵訊號)可以發明智慧。這有什麼意義?智慧需要從獎勵中獲得就像是在表述「人會呼吸」,這似乎是句廢話。
甚至有人質疑「備受尊敬的研究者更容易陷入過度自信」:
還有網友表示:「這篇文章沒有對可以做什麼和不能做什麼設定任何界限。難道無需直接分析函數即可知道在嘗試最大化函數時可以或不能出現什麼嗎?獎勵函數與獲得這些獎勵的系統相結合,完全確定了 「可出現」 行為的空間,而無論出現什麼,對它們來說都是智慧行為。」
不過,也有人提出了一個合理的問題:
最終目標獎勵是否會產生一般的智慧,或者是否會產生一些額外的訊號?純獎勵訊號是否會陷入局部最大值?他們的論點是,對於一個非常複雜的環境,它不會。
但如果你有一個足夠複雜的環境,模型有足夠的參數,並且你不會陷入局部最大值,那麼一旦系統解決了問題中的瑣碎,簡單的部分,唯一的方法是提高效能,創建更通用的解決方案,即變得更智慧。
相關文章
機器之心報道編輯:小舟、陳萍通用人工智慧,用強化學習的獎勵機制就能實現嗎?幾十年來,在人工智慧領域,電腦科學家設計並開發了各種複雜的機制和技術,以復現視覺、語言、推理、運動
2021-06-10 14:47:17

豐色 發自 凹非寺量子位 報道 | 公眾號 QbitAI深更半夜,當鄰居吵架、蹦迪、小孩哭鬧把你吵得睡不著的時候,你是怎麼處理的?去敲門?帶耳塞?默默忍受到神經衰弱?國外一位小哥被樓上
2021-06-10 14:46:03

很多CV開發,都會有這樣的問題,畢竟很多科班出身的從大一就開始接觸程式設計了,但是很多函數和庫還是沒辦法記住。需要的時候就要去百度,到現在工作了還是一樣。 先看看網友的神
2021-06-10 14:45:45

小米在去年12月28日提前釋出了小米11,於今年1月1日上市,僅用21天就突破了百萬臺銷量。雖然小米在高階市場上斬獲頗豐,但在5000元以上的價位,消費者還是傾向於蘋果。根據小米官方
2021-06-10 14:45:04

近年來,會議軟體異軍突起。然而,與之相匹配的遠端會議硬體裝置發展相對滯後。要複製一個線下的會議場景到線上容易,複製線下會議中應有的氛圍與體驗卻難,無法做到真正意義上的眼
2021-06-10 14:44:29

對於喜愛攝影的朋友來說,富士這個品牌一定不陌生,從銀鹽時代的經典膠片到數碼時代的無反機型。富士一直致力於為我們留住瞬間的感動與精彩。618促銷季,富士熱銷機型都有著力度
2021-06-10 14:44:04