楊淨 發自 凹非寺量子位 報道 | 公眾號 QbitAI只需一段語音,就能生成說話視訊。就像這樣。可以看到,表情、動作、神情全都線上,還有不同的穿搭。就連發型、甚至髮際線,都可以不
2021-06-15 18:03:59
楊淨 發自 凹非寺量子位 報道 | 公眾號 QbitAI
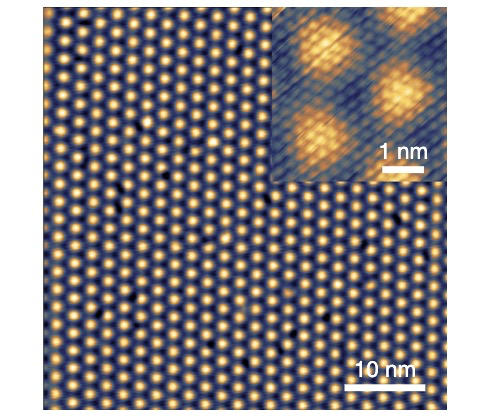
只需一段語音,就能生成說話視訊。
就像這樣。

可以看到,表情、動作、神情全都線上,還有不同的穿搭。

就連發型、甚至髮際線,都可以不同。(手動狗頭)

視訊裡的主人公,是美國一著名主持人John Oliver,這是他主持的一檔節目《Last Week Tonight with John Oliver 》。
而這樣一個視訊生成效果,在Reddit上熱度達580+。

不少網友表示:那這樣,是不是視訊博主就從此省事了?!

彆著急,先康康研究怎麼說。
論文詳情
能實現以上效果的,是一個NWT生成器,用表徵學習來實現音視訊生成。

它由兩個模型組成。
一個用於離散潛在表示的視訊自動編碼器dVAE-Adv。另一個自迴歸先驗模型,用來生成新視訊。
此外,這一生成器可以控制生成的視訊中的潛在屬性,這些屬性在資料中是沒有標註的。
首先,自動編碼器dVAE-Adv,將視訊幀從256×224壓縮到一個16×14的潛在空間。

生成的每個潛在網格元素稱為Memcode,每個Memcode在畫素域中攜帶了大約768個元素的資訊。
而自迴歸模型則作為編解碼器模型,能從離散分類分佈中自動取樣,將音訊轉化為視訊。

研究人員採用的資料集,則是來自這位主持人的節目——《Last Week Tonight with John Oliver (LWT)》組成。
不過這些視訊樣本是經過處理的,研究人員將其分成了16127個視訊片段,平均長度為7.46秒。
最終在主觀評價測試中,這一方法都明顯優於以往的脣語、臉部生成任務。

研究人員表示,這個研究是對話式人類視訊合成技術上的一個新突破,展現了未來將普遍應用的潛力。
srds(雖然但是),目前這個模型還是有一定侷限性。
比如,不能用其他人聲音來生成。
對此作者回應道,嘗試過,但脣語同步會有影響。

還有網友注意到,視訊中人的手很奇怪。

作者則表示,跟GAN出現的問題不同,主要是由自迴歸生成過程中的錯誤分類造成的。
接下來,他們將進一步擴大資料集和模型,來處理不同個體。還有一個想法就是,給定一個框架或部分影象,模型能夠模仿一個特定的情節。
論文地址:https://arxiv.org/pdf/2106.04283.pdf
參考連結:[1]https://next-week-tonight.github.io/NWT_blog/[2]https://www.youtube.com/watch?v=HctArhfIGs4
相關文章
楊淨 發自 凹非寺量子位 報道 | 公眾號 QbitAI只需一段語音,就能生成說話視訊。就像這樣。可以看到,表情、動作、神情全都線上,還有不同的穿搭。就連發型、甚至髮際線,都可以不
2021-06-15 18:03:59
區域網通常在企業中建立,但還將遇到計算機上共享檔案。可以訪問一些本地計算機,但Intranet無法使用此計算機。你怎麼解決這個問題?以下小系列將向您介紹LAN無法訪問的操作方法
2021-06-15 18:03:42
計算機中有各種格式檔案。你知道DBF格式檔案嗎?這是一種特殊的檔案格式,資料庫檔案的副檔名,用於資料交換的許多企業單位。如何開啟DBF格式檔案?我們可以使用FoxPro或Excel開啟
2021-06-15 18:03:11
在刷朋友圈的時候,我們經常會看到廣告的影子。這時我們不得不思考了,這些個性化推薦的廣告,是不是洩露了個人隱私呢?比如你正準備去旅遊,可能會刷到攜程、馬蜂窩的廣告;你正準備買
2021-06-15 18:02:57

影馳 RTX 3070 Ti系列顯示卡現已集結完畢,除了HOF系列稍晚上市外,RTX 3070 Ti GAMER/星曜/金屬大師/黑將四位全新成員已全面上市,售價低至4499元。我們快科技已經拿到了影馳GeF
2021-06-15 18:02:06

6·18年中促銷正在繼續,可能很多小夥伴還在等6·18當天的最大優惠。實際上,有很多產品早已開啟了歷史低價模式。這不,現在就要給大家推薦幾款希捷旗下儲存裝備,軍工級三防保護、
2021-06-15 17:43:11