如今,在一些疾病的診斷領域,AI的準確率已經超過了醫生。靠譜的診斷結果背後,是建立海量資料集上的機器學習。但實際上,可用於訓練的醫療資料非常分散,想要把世界各地的資料都集合
2021-06-17 13:17:39
如今,在一些疾病的診斷領域,AI的準確率已經超過了醫生。
靠譜的診斷結果背後,是建立海量資料集上的機器學習。
但實際上,可用於訓練的醫療資料非常分散,想要把世界各地的資料都集合起來又會引發對資料所有權、隱私性、保密性、安全性的擔憂,甚至資料壟斷的威脅……
常用的方法如聯邦學習,可以解決上述的一些問題,但該模型的參數由「中央協調員」( central coordinator)處理,造成了「權力」的集中,且它的星形架構也導致容錯性降低。
就沒有好的解決辦法嗎?
有,Nature封面為我們刊登了一種叫做Swarm Learning(群體學習,SL)的全新機器學習方法!
 圖片
圖片該方法結合了邊緣計算、基於區塊鏈的對等網路,無需「中央協調員」,超越了聯邦學習,可以在不違反隱私法的情況下集合來自世界各地的任何醫療資料。
研究人員用了四個異質性疾病 (結核病、COVID-19、白血病和肺部病變),來驗證了Swarm Learning方法使用分散式資料來診斷疾病的可行性。
具體如何實現?
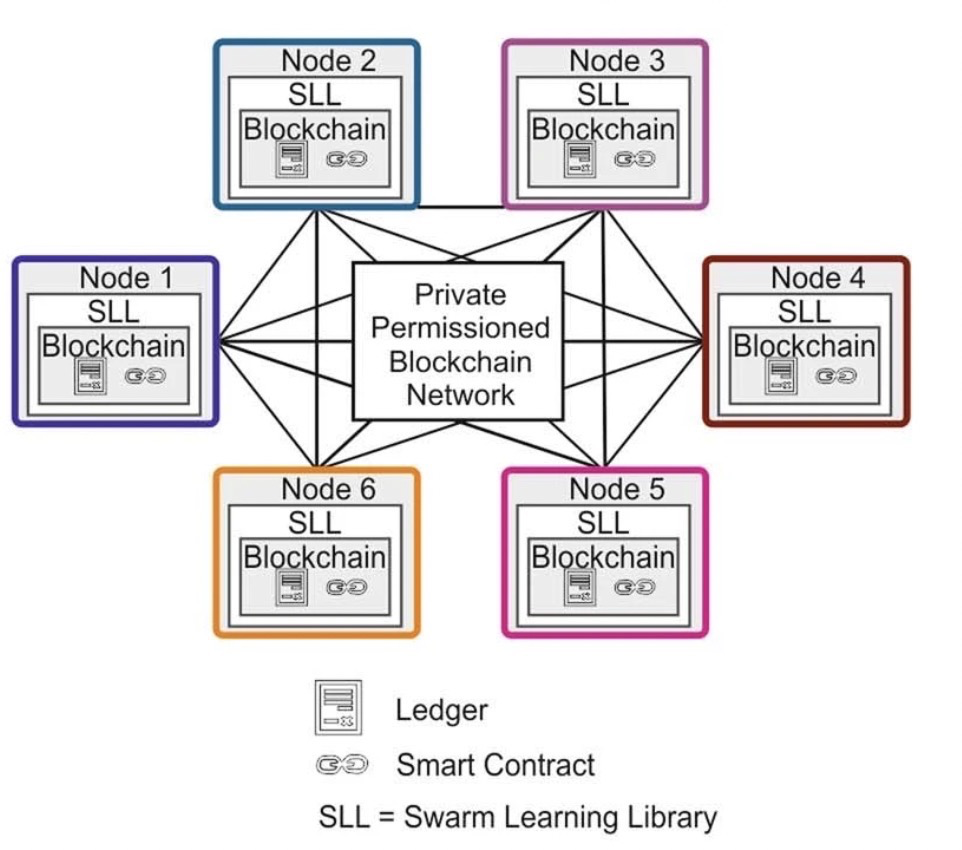
群體學習方法採用去中心化的架構,用私人許可的區塊鏈技術實現。
整個Swarm網路由多個Swarm邊緣節點組成,節點之間通過該網路來共享參數,每個節點使用私有資料和網路提供的模型來訓練自己的模型。
 圖片
圖片該方法提供安全措施,以支援通過私有許可區塊鏈技術保證資料的所有權、安全性和機密性。
 圖片
圖片其中,只有預先授權的參與者才能加入,且新節點的加入是動態的,通過適當的授權措施來識別參與者,並通過區塊鏈智慧合約註冊,讓參與者獲得模型,執行本地模型訓練。
直到本地模型訓練到滿足定義的同步條件後,才可以通過Swarm的API交換模型參數,並在新一輪訓練開始之前,合併新的參數配置來更新模型。
 圖片
圖片△群體學習與其他機器學習方法的架構對比
因此該群體學習方法具有以下特點:
可以將資料所有者的醫療資料儲存在本地;不需要交換原始資料,因此可減少資料流量(data traffic);可以提供高水平地資料安全保護;無需中央管理員就可保證分散成員安全、透明和公平地加入;允許所有成員同等權利地合併參數;保護機器學習模型免受攻擊。為了驗證該方法基於分散式資料開發診斷疾病功能的可行性,研究人員用它來診斷四種疾病。
區分輕度和重度 COVID-19 ,表現優於單個節點
首先是白血病。
研究人員將超過12000多個的樣本資料「孤立」到各個節點,以模擬中現實世界中分佈在世界各地的醫療中心。
再用群體學習訓練這些資料再去診斷未知病人,他們發現,無論如何改變各個節點的樣本分佈情況,群體學習方法的診斷準確率均優於單個節點。
 圖片
圖片接著使用群體學習識別結核病或肺部病變患者,結果也是如此,且減少訓練樣本的數量以後,群體學習的預測效果雖然下降,但仍優於任何一個單獨的節點。
緊跟疫情,研究人員也檢測了群體學習對於診斷新冠病毒的效果。
 圖片
圖片結果顯示,在區分輕度和重度 COVID-19 時,群體學習的表現優於單個節點。
最後,研究人員表示,群體學習作為一個去中心化的學習方法,有望取代目前跨機構醫學研究中的資料共享模式,在保證資料隱私等方面的情況下,幫助AI獲得更豐富全面的資料,為AI診斷疾病提供更高的準確率。
相關文章
如今,在一些疾病的診斷領域,AI的準確率已經超過了醫生。靠譜的診斷結果背後,是建立海量資料集上的機器學習。但實際上,可用於訓練的醫療資料非常分散,想要把世界各地的資料都集合
2021-06-17 13:17:39

作為代表高階的數字機型,榮耀50 Pro採用了後置1億畫素高清主攝的方案,輔以800萬畫素的廣角、200萬畫素微距鏡頭、200萬畫素景深鏡頭也堪稱豪華。值得一提的是,這是榮耀系列
2021-06-17 13:16:34
作者 | 峰華 責編 | 夢依丹出品 | 峰華的個人部落格在前端這個無奇不有的世界裡,有些網站不是正常垂直滾動的,而是橫向滾動的:那麼在沒法把滑鼠滾輪橫過來的前提下(蘋果除
2021-06-17 12:57:54

#Realme#臺版realme narzo 30A開箱評測:廉價的智慧型手機真的好用?REALME NARZO 30A質感外型功能一點都不少realme narzo 30A的背蓋設計非常特別,以兩段式分層設計,背蓋下半部有
2021-06-17 12:57:13

雷鋒網訊息,6 月 16 日,微軟公司宣佈,該公司董事會一致選舉現任 CEO 納德拉(Satya Nadella)為微軟公司董事會主席。納德拉於 2014 年被任命為微軟 CEO,他上任之後首先提出了 "移動
2021-06-17 12:55:44

華為與榮耀,分開有兩百多天了!在特不靠譜晶片限制之前,榮耀有「華為」做背書,在國內可以說擁有著不小的年輕市場,而華為有榮耀這個「幫手」實現了營收、市場佔比雙重爆發。奈何,還
2021-06-17 12:54:23