夢晨 發自 凹非寺量子位 報道 | 公眾號 QbitAIAlphaGo在圍棋界大殺四方時就有人不服:有本事讓AI鬥地主試試?試試就試試。快手團隊開發的鬥地主AI命名為DouZero,意思是像AlphaZe
2021-06-18 15:51:48
夢晨 發自 凹非寺量子位 報道 | 公眾號 QbitAI
AlphaGo在圍棋界大殺四方時就有人不服:有本事讓AI鬥地主試試?
試試就試試。
快手團隊開發的鬥地主AI命名為DouZero,意思是像AlphaZero一樣從零開始訓練,不需要加入任何人類知識。
只用4個GPU,短短几天的訓練時間,就在Botzone排行榜上的344個鬥地主AI中排名第一。
而且還有線上試玩(連結在文章最後),手機也能運行。
線上試玩中演示的是三人鬥地主,玩家可以選擇扮演地主、地主的上家或下家。

選擇當地主來玩玩看,可以開啟顯示AI手牌功能,更容易觀察AI決策過程。另外可以設定AI考慮時間,預設是3秒。

在AI的回合,會顯示面臨的決策和每種打法的預測勝率。

有時可以看到AI並不是簡單的選擇當前勝率最高的打法,而是有更全局的考慮。

鬥地主對AI來說,很難
從博弈論的角度看,鬥地主是「不完全資訊博弈」。
圍棋是所有棋子都擺在棋盤上,對弈雙方都能看到的完全資訊博弈。
而鬥地主每個玩家都看不到其他人的手牌,對於AI來說更有挑戰性。

在棋牌類遊戲中,雖然鬥地主的資訊集的大小和數量不如麻將,但行動空間有10^4,與德州撲克相當,而大多數強化學習模型只能處理很小的行動空間。

鬥地主的所有牌型總共有27472種可能。

像下圖的手牌就有391種打法。

且鬥地主的行動不容易被抽象化,使搜尋的計算成本很高,像Deep Q-Learning和A3C等強化學習模型都只有不到20%的勝率。
另外作為不對稱遊戲,幾個農民要在溝通手段有限的情況下合作並與地主對抗。
像撲克遊戲中最流行的「反事實後悔最小化」(Counterfactual Regret Minimization)演算法,就不擅長對這種競爭和合作建模。

全局、農民和地主網路並行學習
首先將手牌狀態編碼成4x15的獨熱(one-hot)矩陣,也就是15種牌每種最多能拿到4張。

DouZero是在Deep Q-Learning的基礎上進行改進。

使用LSTM(長短期記憶神經網路)編碼歷史出牌,獨熱矩陣編碼預測的牌局和當前手牌,最終用6層,隱藏層維度為512的MLP(多層感知機)算出Q值,得出打法。
除了「學習者」全局網路以外,還用3個「角色」網路分別作為地主、地主的上家和下家進行並行學習。全局和本地網路之間通過共享緩衝區定期通訊。
 △學習者和角色的演算法
△學習者和角色的演算法DouZero在48個核心和4個1080Ti的一臺伺服器上訓練10天擊敗了之前的冠軍,成為最強鬥地主AI。
下一步,加強AI間的協作
對於之後的工作,DouZero團隊提出了幾個方向:
一是嘗試用ResNet等CNN網路來代替LSTM。
以及在強化學習中嘗試Off-Policy學習,將目標策略和行為策略分開以提高訓練效率。
最後還要明確的對農民間合作進行建模。好傢伙,以後AI也會給隊友倒卡布奇諾了。

柯潔在圍棋被AlphaGO擊敗以後,2019年參加了鬥地主錦標賽獲得了冠軍。
不知道會不會有AI「追殺」過來繼續挑戰他。
線上試玩:https://www.douzero.org
GitHub項目地址:https://github.com/kwai/DouZero
論文地址:https://arxiv.org/pdf/2106.06135.pdf
參考連結:[1]https://www.sohu.com/a/285835432_498635
相關文章

夢晨 發自 凹非寺量子位 報道 | 公眾號 QbitAIAlphaGo在圍棋界大殺四方時就有人不服:有本事讓AI鬥地主試試?試試就試試。快手團隊開發的鬥地主AI命名為DouZero,意思是像AlphaZe
2021-06-18 15:51:48
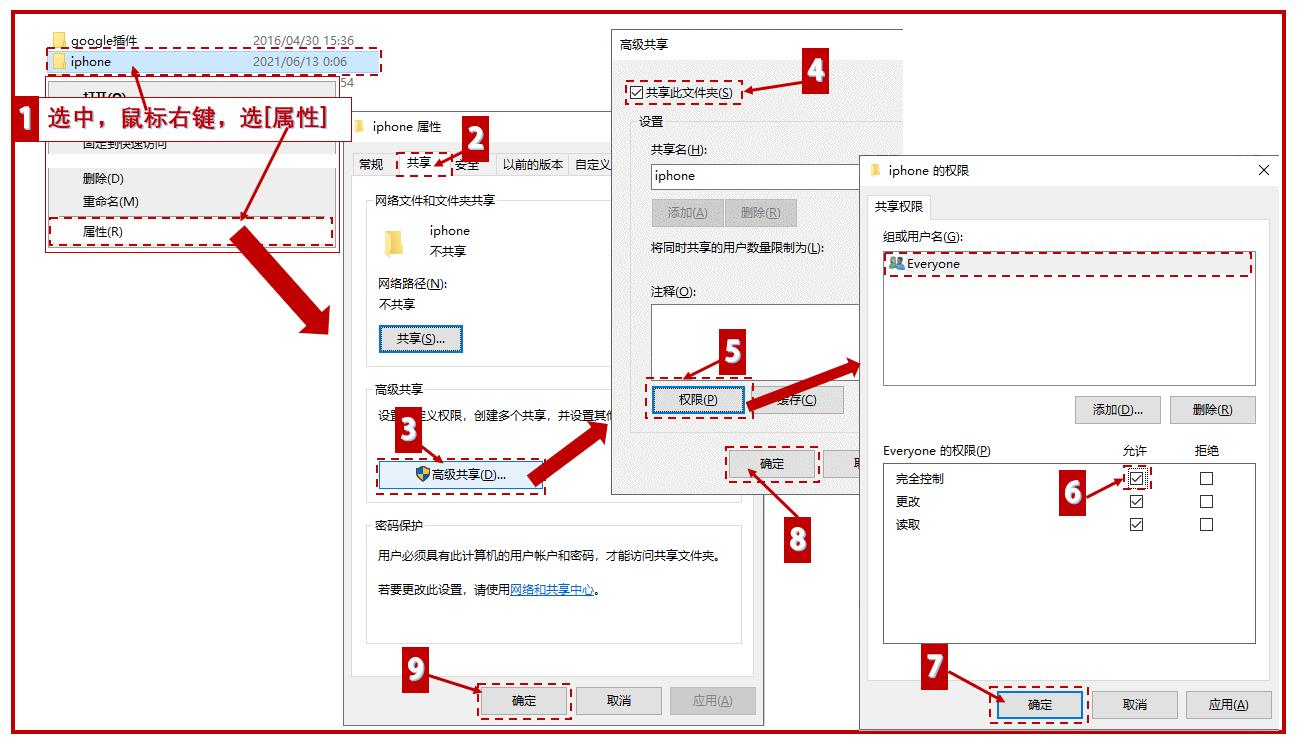
大家好,日漸氣溫升,遇事莫強掙,人生多浮沉,陪伴有廖晨。你是不是也覺得, iphone手機裡的照片和視訊匯入電腦時,特別麻煩?有一次將資料線和電腦連結好,卻無法正常匯出圖片和視訊,後來
2021-06-18 15:51:35

【TechWeb】6月18日訊息,近日全志科技在投資者關係活動上表示,由於產能供應緊張,代工成本會提升,公司已根據經營需要及時適當調節了價格。據悉全志科技主營業務為系統級超大規模
2021-06-18 15:50:58

又是一年畢業季,想必大家最近也經常在朋友圈見學弟學妹曬畢業照。每年的這個時候,筆者微信也總能收到一堆關於選購產品的私信:「有什麼推薦的筆記本?」「A和B筆記本哪個更值得選
2021-06-18 15:50:37

受禁令的影響,華為設計出來的晶片陷入了生產難題,麒麟9000很可能會成為絕唱。眼看庫存晶片越來越少,華為手機業務的處境也愈發危機。按照慣例,每年三四月份是華為P系列釋出時間,
2021-06-18 15:50:19

由於安卓與iPhone系統不同,導致iPhone就算是4GB記憶體也能夠流暢運行,暢玩大型遊戲,系統流暢體驗絲毫不卡頓,但如果換成是安卓手機,4GB顯然不夠用了,所以安卓使用者今年買手機選6G
2021-06-18 15:31:08