來源:Python資料之道作者:Peter整理:陽哥大家好,我是陽哥。今天來跟大家分享用 BeautifulSoup 獲取資訊的一些知識點,文章內容由公眾號讀者 Peter 創作。歡迎各位童鞋向公眾號投
2021-06-22 11:28:02
來源:Python資料之道
作者:Peter
整理:陽哥
大家好,我是陽哥。
今天來跟大家分享用 BeautifulSoup 獲取資訊的一些知識點,文章內容由公眾號讀者 Peter 創作。
歡迎各位童鞋向公眾號投稿,點選下面圖片瞭解詳情!
爬蟲,是學習Python的一個有用的分支,網際網路時代,資訊浩瀚如海,如果能夠便捷的獲取有用的資訊,我們便有可能領先一步,而爬蟲正是這樣的一個工具。
Beautiful Soup 是一個可以從HTML或XML檔案中提取資料的Python庫。由於 BeautifulSoup 是基於 Python,所以相對來說速度會比另一個 Xpath 會慢點,但是其功能也是非常的強大,本文會介紹該庫的基本使用方法,幫助讀者快速入門。
網上有很多的學習資料,但是超詳細學習內容還是非官網莫屬,資料傳送門:
英文官網:https://www.crummy.com/software/BeautifulSoup/bs4/doc/
中文官網:https://www.crummy.com/software/BeautifulSoup/bs4/doc.zh/
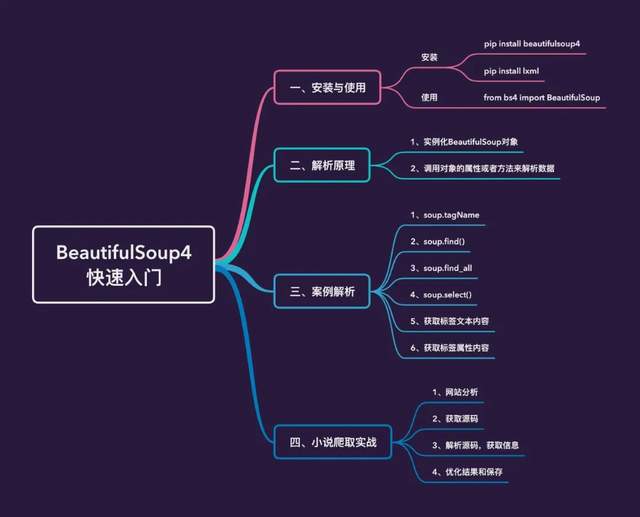
本文的主要內容如下:

安裝和使用
安裝
安裝過程非常簡單,直接使用pip即可:
pip install beautifulsoup4
上面安裝庫最後的4是不能省略的,因為還有另一個庫叫作 beautifulsoup,但是這個庫已經停止開發了。
因為BS4在解析資料的時候是需要依賴一定的解析器,所以還需要安裝解析器,我們安裝強大的lxml:
pip install lxml
在python互動式環境中匯入庫,沒有報錯的話,表示安裝成功。

使用
使用過程直接匯入庫:
from bs4 import BeautifulSoup
解析原理
解析原理
例項化一個BeautifulSoup物件,並且將本地或者頁面源碼資料載入到該物件中通過呼叫該物件中相關的屬性或者方法進行標籤定位和資料提取如何例項化BeautifulSoup物件
將本地的HTML文件中的資料載入到BS物件中將網頁上獲取的頁面源碼資料載入到BS物件中案例解析
原資料
假設我們現在本地有一個HTML檔案待解析,具體內容如下,資料中有各種HTML標籤:html、head、body、div、p、a、ul、li等

載入資料
from bs4 import BeautifulSoupfp = open('./test.html','r',encoding='utf-8') # 開啟本地檔案soup = BeautifulSoup(fp,'lxml')soup

所有的資料解析都是基於soup物件的,下面開始介紹各種解析資料方法:
soup.tagName
soup.TagName返回的是該標籤第一次出現的內容,以a標籤為例:

資料中多次出現a標籤,但是隻會返回第一次出現的內容

我們再看下div標籤:

出現了2次,但是隻會返回第一次的內容:

soup.find('tagName')
find()主要是有兩個方法:
返回某個標籤第一次出現的內容,等同於上面的soup.tagName屬性定位:用於查詢某個有特定性質的標籤1、返回標籤第一次出現的內容:
比如返回a標籤第一次出現的內容:

再比如返回div標籤第一次出現的內容:

2、屬性定位
比如我們想查詢a標籤中id為「谷歌」的資料資訊:

在BS4中規定,如果遇到要查詢class情況,需要使用class_來代替:

但是如果我們使用attrs參數,則是不需要使用下劃線的:

soup.find_all()
該方法返回的是指定標籤下面的所有內容,而且是列表的形式;傳入的方式是多種多樣的。
1、傳入單個指定的標籤

上面返回的是列表形式,我們可以獲取我們想要的內容:

2、傳入多個標籤(列表形式)
需要主要返回內容的表達形式,每個標籤的內容是單獨顯示的

3、傳入正則表示式
比如檢視以a開頭標籤的全部內容

檢視以li標籤開頭的全部內容:

選擇器soup.select()
主要是有3種選擇器,返回的內容都是列表形式
類選擇器:點id選擇器:#標籤選擇器:直接指定標籤名1、類選擇器

2、id選擇器


3、標籤選擇器
直接指定li標籤

4、選擇器和find_all()可以達到相同的效果:

soup.tagName和soup.find('tagName')的效果也是相同的:

層級選擇器使用
在soup.select()方法中是可以使用層級選擇器的,選擇器可以是類、id、標籤等,使用規則:
單層:>多層:空格1、單層使用

2、多層使用

獲取標籤文字內容
獲取某個標籤中對應文字內容主要是兩個屬性+一個方法:
textstringget_text()1、text

2、string

3、get_text()

3者之間的區別
# text和get_text():獲取標籤下面的全部文字內容# string:只能獲取到標籤下的直系文字內容

獲取標籤屬性值
1、通過選擇器來獲取

2、通過find_all方法來獲取

BeautifulSoup實戰
下面介紹的是通過BeautifulSoup解析方法來獲取某個小說網站上古龍小說名稱和對應的URL地址。
網站資料
我們需要爬取的資料全部在這個網址下:https://www.kanunu8.com/zj/10867.html,右鍵「檢查」,檢視對應的源碼,可以看到對應小說名和URL地址在源碼中位置
每行3篇小說在一個tr標籤下面,對應的屬性href和文字內容就是我們想提取的內容。

獲取網頁源碼
import requestsfrom bs4 import BeautifulSoupimport pandas as pdimport reurl = 'https://www.kanunu8.com/zj/10867.html'headers = {'user-agent': '個人請求頭'}response = requests.get(url = url,headers = headers)result = response.content.decode('gbk') # 該網頁需要通過gbk編碼來解析資料# result
例項化BeautifulSoup物件
soup1 = BeautifulSoup(result,'lxml')# print(soup1.prettify()) 美化輸出源碼內容
獲取名稱和URL地址
1、先獲取整體內容
兩個資訊全部指定a標籤中,我們只需要獲取到a標籤,通過兩個屬性href和target即可鎖定:
# 兩個屬性href和target,不同的方法來鎖定information_list = soup1.find_all('a',href=re.compile('^/book'),target='_blank')information_list

2、再單獨獲取兩個資訊
通過屬性來獲取URL地址,通過文字來獲取名稱
url_list = []name_list = []for i in information_list: url_list.append(i['href']) # 獲取屬性 name_list.append(i.text) # 獲取文字


3、生成資料幀
gulong = pd.DataFrame({ "name":name_list, "url":url_list})gulong

我們發現每部小說的具體地址其實是有一個公共字首的:
https://www.kanunu8.com/book,現在給加上:
gulong['url'] = 'https://www.kanunu8.com/book' + gulong['url'] # 加上公共字首gulong.head()

另外,我們想把書名的《》給去掉,使用replace替代函數:
gulong["name"] = gulong["name"].apply(lambda x:x.replace("《","")) # 左邊gulong["name"] = gulong["name"].apply(lambda x:x.replace("》","")) # 右邊# 儲存gulong.to_csv("gulong.csv",index=False) # 儲存到本地的csv檔案
最後顯示的前5行資料:

總結
本文從BeautifulSoup4庫的安裝、原理以及案例解析,到最後結合一個實際的爬蟲實現介紹了一個數據解析庫的使用,文中介紹的內容只是該庫的部分內容,方便使用者快速入門,希望對讀者有所幫助。
相關文章
來源:Python資料之道作者:Peter整理:陽哥大家好,我是陽哥。今天來跟大家分享用 BeautifulSoup 獲取資訊的一些知識點,文章內容由公眾號讀者 Peter 創作。歡迎各位童鞋向公眾號投
2021-06-22 11:28:02
出品|開源中國文|局長.NET MAUI Preview 5 已釋出。在此版本中,開發團隊啟用了動畫和檢視轉換 (view transformation) 功能、完成了多個 UI 元件的移植,並對單個項目模板進行
2021-06-22 11:27:47
我們在看教程的時候,需要自己獨立的按照實現功能去分析實現思路。如果完全不知道怎麼去實現,那就先看老師怎麼實現的。其實最重要的第一不是思路和解決辦法,然後再說怎麼寫。
2021-06-22 11:27:38

說起對攝影老法師的印象,我們腦海中都會閃過那些在湖邊揹著碩大的揹包、拿起長長的「大狙」、雙手穩穩地託著沉重機器的畫面,而這種為了大光圈、全焦段的「一支長槍走天下
2021-06-22 11:27:01

隨著5G市場的加速普及,5G這個耗電大戶讓手機的續航情況相比4G時代縮水不少,為5G手機的使用體驗拖了不少後腿,因此各廠商都選擇通過更高的快充來彌補續航上不足,甚至做出了百瓦快
2021-06-22 11:26:26

信通院公佈的報道顯示:2021 年 5 月份,國內市場手機出貨量為 2296.8 萬部,同比下降 32%。其中包括 5G 手機1673.9 萬部,出貨量實現了7.0%的增長。為什麼會出現手機出貨量的下滑呢?
2021-06-22 11:08:09