博雯 發自 凹非寺量子位 報道 | 公眾號 QbitAI現在,想象一個外國人面前擺了句「金石迸碎蕩塵埃,磐山紆水盡為開」。除了痛苦地死摳複雜單詞和長難句語法,他還能怎麼去理解這句
2021-06-22 19:09:30
博雯 發自 凹非寺量子位 報道 | 公眾號 QbitAI
現在,想象一個外國人面前擺了句「金石迸碎蕩塵埃,磐山紆水盡為開」。
除了痛苦地死摳複雜單詞和長難句語法,他還能怎麼去理解這句話呢?
——想象。
想象這句詩詞中的「金石」、「塵埃」、「山水」各個詞彙的意象,再將意象匯聚成一個具體的畫面或場景。

而這時就有研究者靈機一動:
人類不是能根據非母語文字腦補畫面,進而做到更深入的理解嗎?
那機器是不是也能根據輸入文字腦補影象,最終實現更好的翻譯呢?
於是,一個以視覺想象為引導的機器翻譯模型ImagiT就誕生了。
 △已被NAACL 2021收錄。
△已被NAACL 2021收錄。論文作者來自南洋理工大學和位元組跳動人工智慧實驗室。
缺少圖片也能利用視覺
提到「利用視覺」,我們首先會想到多模態機器翻譯。
比起純文字的機器翻譯,多模態機器翻譯能夠利用語音、影象這樣的模態資訊來提高翻譯質量。
△多模態機器翻譯的輸入:源語言+標註的圖片
但多模態機器翻譯的質量是和資料集的可用性直接掛鉤的。
換句話說就是標註圖片的數量和質量會非常影響模型翻譯的有效性。
但偏偏人工圖片標註的成本又不低……所以現階段的多模態機器翻譯大都應用在Multi30K,一個包含了3萬張圖片標註的資料集上。
而新提出的ImagiT翻譯模型呢?
它在推理階段不需要標註圖片作為輸入,而是通過想象的方式利用視覺訊號,在訓練階段將視覺語義蘊含到模型內部。
△多模態機器翻譯的輸入:源語言
做到了在缺少圖片標註的情況下也能利用視覺資訊。
基於想象的翻譯模型到底什麼樣
這是一個端到端的對抗學習架構。
架構左右端是我們熟悉的transformer的編碼器和解碼器,而中間則是這一框架獨特的生成想象網路。
這一生成想象網路主要由兩個轉化器和一個注意力層組成,具體做轉化時:
一、源文字通過F0輸入
F0包含一個全連線層和四個去卷積層。
基於GAN的思想,句子特徵與噪聲拼接後會通過F0轉化成視覺表徵。
二、將注意力放在詞層面
在注意力層關注源文字中的相關詞彙,並生成影象不同子區域的細粒度細節,讓影象特徵的子區域與詞對應。
最終得到更加語義一致的視覺表徵。
三、視覺表徵通過F1輸出
F1包含兩個全連線層和一個去卷積層,以及一個殘差層。
通過這一轉化器,捕捉多層次(詞級和句級)的語義,輸出生成的視覺特徵f1。
四、多模態聚合
把原本的文字模態和新合成的視覺特徵聚合在一起。
五、翻譯
模型的學習目標結合了文字到圖片的生成,以及逆任務的影象字幕和翻譯。
其中鑑別器源文字、生成影象和真實影象作為輸入,用來評估合成影象是否與真實圖片一致。
同時,也會使用條件對抗損失來評估合成的影象是否與源語言具有相同的語義。
「腦補」如何幫助翻譯?
研究者使用了一種退化策略,即用特殊字元替換源語言文字中的重要詞語,來觀察模型的翻譯表現會下降多少。
在這這種情況下,純文字的翻譯模型只能通過丟失詞語的上下文和偏置來推理句子的翻譯。
多模態機器翻譯則會利用標註的圖片進行翻譯。
而ImagiT在缺少圖片標註的情況下,還能根據退化的文字想象並恢復丟失的資訊。
通過這一特殊的探索實驗,可以看到ImagiT能在訓練階段學習特定詞語(色彩,可被具象化的實體詞等)與其他詞語之間相關性和共現。

△將源語言文字中所有的色彩詞全部替換為特殊字元。
而對比純文字翻譯,通過想象恢復被替換文字的ImagiT模型在翻譯質量上下降的幅度也最少。

效果如何?
由於ImagiT不需要圖片作為輸入,所以在測試時選用純文字的transformer模型作為baseline。
在Multi30K的英法、英德Test2016,Test2017上進行測試時,ImagiT得到了與SOTA多模態翻譯系統相當的表現:
而在Ambiguous COCO上也展現出了不錯的測試結果:
論文地址:https://arxiv.org/abs/2009.09654
相關文章

博雯 發自 凹非寺量子位 報道 | 公眾號 QbitAI現在,想象一個外國人面前擺了句「金石迸碎蕩塵埃,磐山紆水盡為開」。除了痛苦地死摳複雜單詞和長難句語法,他還能怎麼去理解這句
2021-06-22 19:09:30
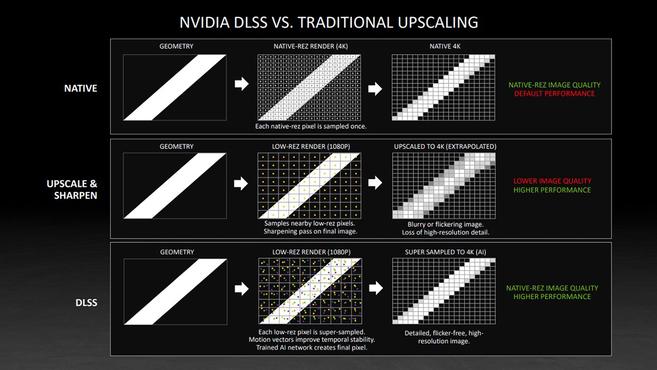
話說最近這陣子NVIDIA的DLSS應該可以說是無人不知的了。前不久來自Rockstar的神作《荒野大鏢客:救贖2》以及Bethesda的《毀滅戰士:永恆》都宣佈將會加入對光追以及DLSS的支援,
2021-06-22 19:08:58

【TechWeb】2021年6月22日,由腦陸科技聯合神經調控技術國家工程實驗室共同舉辦的首屆「腦科學開放日」在京舉行。活動以「覺醒」為主題,邀請了來自產學研用的專家、學者與諸多
2021-06-22 19:08:49

華為手機的人氣一直都不低,影響力也非常的高,每次發生新的動作都會引起非常高的關注度,這就是市場地位,同時也是發展這麼久蘊含的實力。如果換成其他手機廠商的話,大半年沒有什麼
2021-06-22 19:08:28

科技行業新鮮趣事一文速覽,在這裡你可以瞭解科技熱點、獲悉行業動態,話不多說讓我們一起來看看吧~iPhone 13系列將取消金色版本據悉,蘋果將在9月上旬舉行秋季新品釋出會,屆時將
2021-06-22 19:08:03
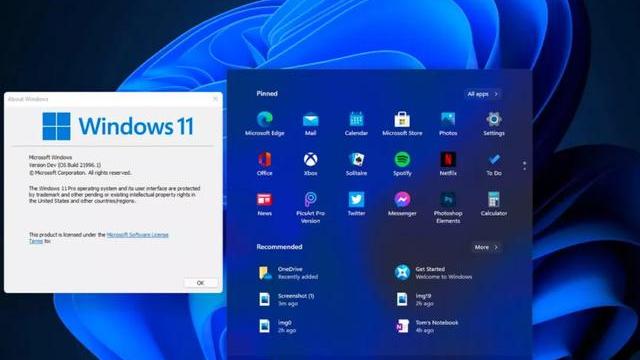
都在傳微軟很可能在6月24日的釋出會,正式釋出下一代系統:Windows 11。嘿嘿,那你們看看,現在機哥手中的是什麼?是的,機哥已經第一時間上手瞭如假包換、正宗酸爽的「Windows 11」!這
2021-06-22 18:50:46