當我們還對玫瑰、月季和薔薇傻傻分不清楚的時候,計算機視覺已經可以在一萬種極其相似的自然界物種裡精確地分門別類了。影象分類是計算機視覺領域一個由來已久,經過了深入挖掘
2021-06-23 12:55:11
當我們還對玫瑰、月季和薔薇傻傻分不清楚的時候,計算機視覺已經可以在一萬種極其相似的自然界物種裡精確地分門別類了。
影象分類是計算機視覺領域一個由來已久,經過了深入挖掘的問題。但在訓練資料有限且類別高度相似的領域中,現有技術的表現並不盡如人意。特別是細粒度分類(Fine-Grained Visual Categorization),如視覺上相似的植物或動物物種、視網膜疾病、建築風格等的精確區分,仍然極具挑戰性。當前,細粒度影象分類也被認為是計算機視覺領域正在解決的最有趣和最有用的開放問題之一。
FGVC是全球頂級計算機視覺盛會CVPR主辦的workshop競賽。在剛剛落幕的CVPR2021中,位元組跳動以出色的表現 ,榮獲了iNat Challenge 2021大規模細粒度分類和Semi-Supervised iNat 2021:半監督細粒度分類兩項競賽的冠軍。
一起看看技術大神們是怎麼做到的吧。
背景介紹
據估計,自然界包含數百萬種極其相似的植物和動物。在細粒度分類上,如果沒有專業知識,許多物種極難分類。而且,資料收集和標註也面臨較大的困難,常常伴隨著類別大,資料量少,無標註樣本多的問題。
本屆FGVC在細粒度分類的方向上舉辦了兩個不同設定的比賽。
1)iNat Challenge 2021:大規模的細粒度分類,任務要求在10000類資料上對自然界中的物種進行分類;2)Semi-Supervised iNat 2021:半監督的細粒度分類,任務旨在揭示現實環境中遇到的一些挑戰,從部分標註的資料中學習。
比賽難點
兩項賽事在側重點和設定上各有不同,從不同角度指向了細粒度分類中常遇到的難點:
1)細粒度分類類別多;2)大量標籤的類間差異小;3)影象資料中背景干擾較大,實際區分區域佔比差異大;4)資料標註難度大導致有標註資料量少;5)無標註資料中同時包含類內和類外未標記資料,且類外資料佔比不明,比例較大;6)類間資料不平衡,標註/無標註資料均有明顯的長尾現象等等。
演算法技術方案
全監督賽道
 全監督賽道的物種數量分佈
全監督賽道的物種數量分佈全監督賽道面對的主要問題是物種類別數目多,分類的粒度細,不同物種之間數量差異比較大,因此,BrownBlueGreendd團隊從針對該任務在以下幾個方面進行了改進。
網路結構設計
不同於普通的影象分類任務,在細粒度任務中使用簡單的Softmax 加交叉熵的損失函數往往訓練起來收斂較慢且效果欠佳。在細粒度場景下,團隊選擇度量學習中常用的ArcFace[1]作為損失函數,Arcface通過增加邊界懲罰,增強了類內的緊湊度以及類間的差異,有效的提升了模型的分類準確率。

Arcface計算公式
在Backbone網路的選擇中,團隊選擇了基於Transformer結構的Swin-Transformer[2]以及基於CNN結構的EfficientNet[3]作為基礎網路,這兩個Backbone的優點是模型的Imagenet 準確率較高且效能較好。
多模態資訊融合
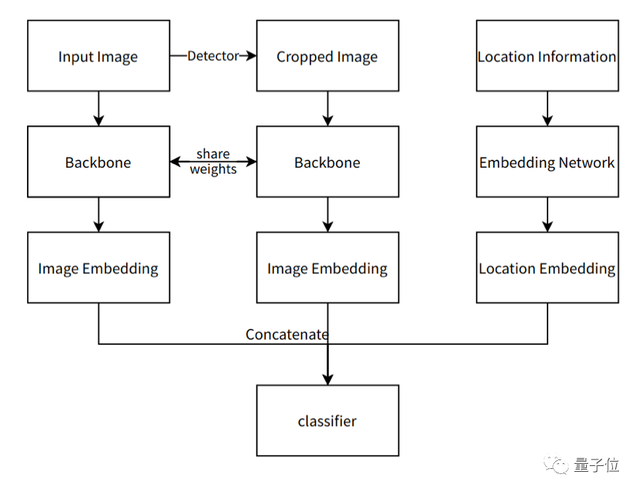
與往年的比賽設定不同,今年的比賽中主辦方提供了影象的經緯度以及日期等資訊,這對自然界生物的細粒度識別有很大的幫助,比如南美洲和亞洲的某種植物,在採集的影象上可能差異並不大,但通過影象的經緯度等資訊,就可以很容易的對兩個物種進行區分。團隊設計瞭如圖所示的多模態資訊融合網路,其中,影象資訊通過Backbone網路得到相應的影象特徵。對於地理資訊,首先對地理資訊進行編碼,然後通過Embedding網路對映成為特徵向量,與影象特徵進行疊加後,送入最後的分類器中。實驗結果顯示加入地理特徵後,在不同的網路結構中均有3-4個點的提升。

多模態資訊融合網路
此外,賽後團隊還探索了基於檢測的方案。首先基於歷年具有檢測框的資料訓練一個目標檢測器。對於輸入的原始影象,首先用檢測器提取影象的關鍵區域,隨後將原始影象與提取的關鍵區域影象分別經過特徵提取網路,並進行特徵融合。實驗表明,在模型參數量幾乎不變的情況下,採用基於檢測的方案會給同樣的基礎模型準確率帶來明顯的提升。

基於檢測的方案
資料增強
在訓練階段,團隊採用隨機翻轉,隨機旋轉,以及亮度、對比度、飽和度上的變化進行資料增強。同時團隊還採用了隨機擦除的增強方式,即在輸入圖中隨機選擇一塊區域以概率P擦除該區域,並使用影象的均值進行填充,有效的緩解了過擬合現象。
在測試階段,團隊使用FiveCrop、水平翻轉與多尺度測試來提高模型的表現。此外,對於多個基礎模型的預測結果,拋棄了現有的模型融合策略,創新性地採用了進化演算法實現多模型預測的融合,對每個基礎模型的投票權重進行迭代優化,避免了手動調節超參數的同時,進一步提升了預測準確率。最後,團隊得到了95.56%(Public)/95.58%(Private)的Top1 準確率。
半監督賽道
半監督學習旨在使用更有效的方式利用無標註資料去提升模型的效果。其中一部分方法是通過在無標註資料上進行無監督學習(對比學習)等,得到預訓練模型後在有標註資料上進行fine-tuning,如MoCo[4] 系列,SimCLR[5] 系列,SwAV[6] 等。另外一些方法是在共同使用這些有標註及無標註資料進行訓練,如FixMatch[7],MixMatch[8]等。
無監督訓練方案
無標註資料的使用可以在few-shot場景下帶來較大的收益,如何利用這部分資料顯得非常重要。該場景的設定困難且較為貼近實際場景,即同時包含類內及類外的資料,類外資料佔比可能在70%-90%。同時由於細粒度的特性,資料的類間差異較小。這些特點使得無監督對比學習及半監督學習在該設定下的收益較小。
團隊設計並優化了聚類方案將無監督轉化為大規模小量資料的有監督學習,通過特徵和類別資訊將無標註影象劃分成cluster,通過cluster分佈和數量等資訊選取相應的有效類別,將cluster資訊當作弱監督的標註進行有監督訓練。
 △無監督訓練流程
△無監督訓練流程隨後通過使用有監督資料進行引導和pseudo-label的方式篩選與目標標籤更緊密更相關的資料,進行二輪Fine-Grained Recluster。並將前一階段的模型在該精細資料上進行微調,得到新的預訓練模型。
同時,訓練期間可以採用Prototypical的方式,減少長尾及資料量少帶來的影響。
有監督訓練方案
有標註的資料在數量較少,在進行微調的過程中,很容易出現過擬合的情況,而且由於過擬合的情況,導致資料平衡策略都不是很奏效。同時由於模型參數量的不同,微調對於過擬合/擬合的程度也不同,在參數量大的模型,如ResNeSt269e及NFNet,單一學習率及雙階段微調會產生嚴重的過擬合。
於是團隊針對解決過擬合問題採用了兩種不同的微調方法。
1) 針對參數量較大的模型,使用分層學習率微調,凍住BN/LN層,對於淺層網路開小學習率,採用資料平衡策略進行訓練。
2)針對參數量較小的模型,使用雙階段微調,第一階段凍住BN/LN層,端到端微調整個網路,第二階段凍住骨幹網路,採用資料平衡策略微調最後的refactor及fc線性層。
雙階段相較單階段有更大的收益,分層學習率對於大參數量模型在單階段也有更好的效果。
 微調流程
微調流程迭代訓練
該訓練流程是可以迭代起來以增強網路的最終效果,通過更好的模型可以獲得更好的cluster及pseudo-label,可以產出更強的預訓練模型,以及準確的預測結果。
測試階段
測試階段採用多尺度測試及Five Crop等增強方式。同時使用不同結構不同訓練方式的網路進行ensemble,最終在官方驗證集上達到了82.1%的Top-1準確率。
結果與總結
採用上述的技術方案,團隊在全監督和半監督賽道均取得了冠軍的成績。

全監督賽道

半監督賽道
成果落地應用
細粒度識別在多種場景下都有著應用,比如識別身邊的植物,動物,商品等。半監督的技術貼合細粒度問題的實際運用場景,使得團隊在構建深度學習模型時,降低標註成本,使用更少的資料,以更低的成本來完成模型的訓練。目前,上述技術正在位元組跳動的部分產品裡開發落地。
位元組跳動智慧創作團隊
智慧創作團隊是位元組跳動的多媒體創新科技研究所和綜合型服務商。覆蓋音視訊、計算機視覺、語音、圖形影象、工程軟體開發等多技術方向,在部門內部實現了內容創作和消費的閉環。旨在以多種形式向公司內部各類業務線和外部 toB 合作伙伴提供業界最前沿的多媒體和智慧創作能力與行業解決方案。
目前,智慧創作團隊已通過位元組跳動旗下的智慧科技品牌火山引擎向企業開放技術能力和服務。
相關文章
當我們還對玫瑰、月季和薔薇傻傻分不清楚的時候,計算機視覺已經可以在一萬種極其相似的自然界物種裡精確地分門別類了。影象分類是計算機視覺領域一個由來已久,經過了深入挖掘
2021-06-23 12:55:11
基於開源RISC-V架構的晶片設計公司SiFive宣佈推出新的SiFive Performance系列處理器核心,包括P270和PP550兩款,後者是SiFive迄今為止效能最高的處理器。近期有訊息指,英特爾有
2021-06-23 12:54:35

IT之家 6 月 23 日訊息 OPPO 社群今日釋出公告,OPPO Find X 開啟 ColorOS 11 升級內測招募,時間截止明日(6 月 24 日)。IT之家瞭解到,本次內測招募 PRE 使用者 500 人,PRE 升級內
2021-06-23 12:32:33

一、前言:H45 + RTX 30獨顯組成的絕佳遊戲本配置5月中旬,Intel正式釋出了眾所期待的11代酷睿高效能移動版處理器(代號Tiger Lake-H45),熱設計功耗45W,整合全新CPU、GPU架構和AI
2021-06-23 12:32:06

微軟在去年推出了兩款全新的次世代主機,包括面向發燒級玩家的Xbox Series X以及面向輕量級玩家的Xbox Series S,相比較效能怪獸XSX,XSS擁有更加便攜的外觀,此外基於AMD Zen 2 CP
2021-06-23 12:13:02

今日三星Galaxy A52的系統更新,給Galaxy A52帶來一個Bug。三星 Galaxy A52 HDR 視訊播放亮度問題Galaxy A52配備6.5英寸FHD+ Super AMOLED顯示屏,重新整理率為90Hz,峰值亮度為8
2021-06-23 12:12:01