豐色 發自 凹非寺量子位 報道 | 公眾號 QbitAI此前,清華大學與曠視科技曾通過結構重參數化將7年老架構VGG「升級」為效能直達SOTA的RepVGG模型。如今,這個結構重參數化系列研
2021-06-29 14:45:25
豐色 發自 凹非寺量子位 報道 | 公眾號 QbitAI
此前,清華大學與曠視科技曾通過結構重參數化將7年老架構VGG「升級」為效能直達SOTA的RepVGG模型。
如今,這個結構重參數化系列研究又添「新成員」:
他們提出一個基於多層感知器式的RepMLP模型,將卷積融合進全連線層(FC)進行影象識別。
 圖片
圖片該模型同時組合了全連線層的全局建模、位置感知特性與卷積層的局部結構提取能力。
結果在ImageNet資料集、人臉識別任務及語義分割三方面都實現了識別精度的提升,且在大幅增加參數的同時不會造成推理速度的顯著降低(增加47%參數,速度只下降2.2%)。
用卷積強化全連線,使之具有局部性又不失全局性
為什麼要用卷積來強化全連線?
因為卷積網路具有局部先驗特性,識別效果很不錯。
在一張圖片中,一個畫素點跟它周圍的畫素點的關係往往比遠在天邊的另一個畫素點更密切,這稱為局部性。人類在識別圖片的時候潛意識地利用這一點,稱為局部先驗。
而比起卷積層,全連線層的影象識別由於參數增多往往導致推理速度較慢和過擬合,但它具有更好的全局建模、位置感知能力。
所以研究人員將兩者結合,在訓練階段,研究人員在RepMLP內部構建卷積層,而在推理階段,將這些卷積層合併到全連線層內。
整個流程分為3步:
1、訓練時,既有全連線層又有卷積,把兩者的輸出相加;2、訓練完成後,先把BN的參數「吸」到卷積核或全連線層中去,然後把每一個卷積轉換成全連線層,把所有全連線層加到一起,等效去掉卷積。3、儲存並部署轉換後的模型。
詳細過程如下:
 圖片
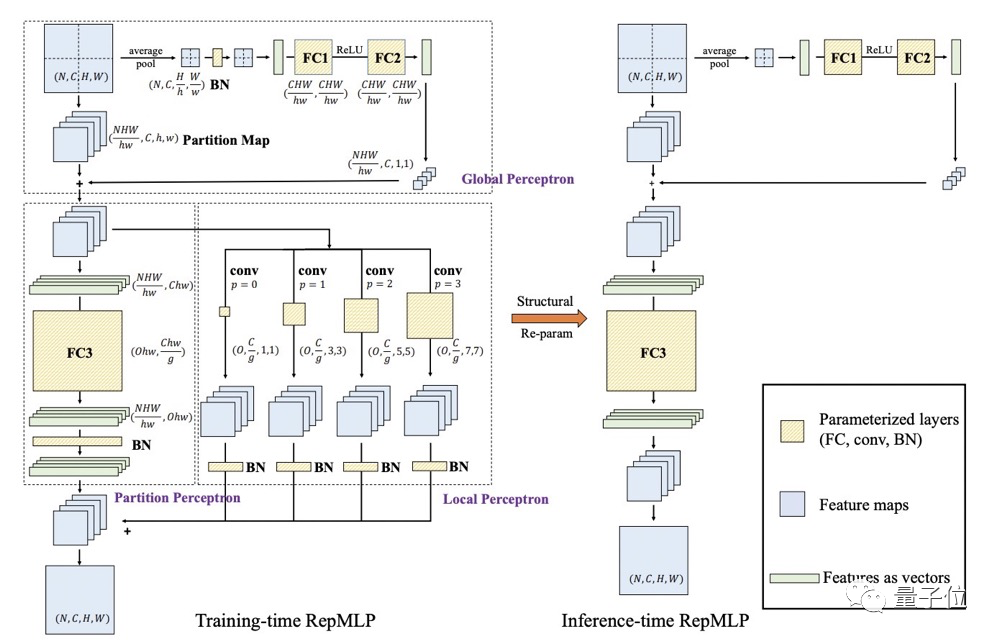
圖片其中N、C、H、W分別代表batch size、輸入通道數、高度和寬度;h 、 w 、 g 、p 、 O分別代表每一塊分塊(partition)的高度、寬度、組數、填充畫素和輸出通道。
首先將輸入特徵進行分塊,分塊會打破相同通道不同分塊之間的相關性,因此全局感知(Global Perceptron)對每個分塊新增相關性。
接著,分塊感知(Partition Perceptron) 以分塊特徵作為輸入,包含全連線層與BN層,進一步減少參數和計算量。
局部感知(Local Perceptron )將分塊特徵經由卷積核大小分別為1、3、5,、7的卷積層進行處理 ,將所有卷積分支的輸出與分塊感知的輸出相加作為最終的輸出 。
那如何將訓練階段的卷積轉換為推理階段的全連線層呢?
 圖片
圖片思路和RepVGG一樣,利用了結構重參數化(通過參數的等價轉換實現結構的等價轉換),將局部感知和分塊感知的輸出合併到全連線層進行推理,並去除卷積。
具體來說,
由於矩陣乘法的可加性(AX + BX = (A+B)X),一個稀疏且共享參數的全連線層(Toeplitz矩陣)加一個不稀疏不共享參數的FC(全自由度的矩陣),可以等價轉換為一個全連線層(其參數是這兩個矩陣之和),就可以在推理階段將這些卷積等效地去掉。
另外,研究人員表示,之所以卷積和全連線層之間能建立聯絡,是因為卷積可以看成一個稀疏且存在重複參數的全連線層。
並「戲謔」道:
RepMLP這樣做看起來像是讓全連線層的「內部」含有卷積,所以也可以稱為「內卷」。
實驗結果
消融研究結果如下表,可以發現:
 圖片
圖片A為轉換前的模型,計算量非常大,說明了結構重參數的重要性;
B為沒有Local Perceptron的變體,精度下降8.5%,說明了局部先驗的重要性;
C為沒有Gloabl Perceptron的變體,精度下降1.5%,說明了全局建模的重要性;
D替換FC3為卷積,儘管其感受野更大,但仍造成精度下降3.5.%,說明全連線層比conv更強大,因為conv是降級的全連線層。
所以,用RepMLP替換Res50中的部分結構,將ResNets在ImageNet上的準確率提高了1.8%。
 圖片
圖片將ImageNet 預訓練模型遷移到人臉識別和語義分割上,也都有效能提升,分別提升2.9%的準確率和2.3%的mIoU。
 圖片
圖片另外,在速度方面,RepMLP可以大幅增加參數的同時而對速度影響不大(參數增加47%,ImageNet精度提升0.31%,速度僅降低2.2%)。
 圖片
圖片相關文章
豐色 發自 凹非寺量子位 報道 | 公眾號 QbitAI此前,清華大學與曠視科技曾通過結構重參數化將7年老架構VGG「升級」為效能直達SOTA的RepVGG模型。如今,這個結構重參數化系列研
2021-06-29 14:45:25

果粉之家,專業蘋果手機技術研究十年!您身邊的蘋果專家~來自供應鏈的最新訊息稱,iPhone 13的部分配件已經開始到貨,即將開始組裝新iPhone所需的零部件。據悉,這次先到貨的是iPhone
2021-06-29 14:44:59

尼康公司宣佈釋出一款APS-C格式(尼康DX格式)微單數碼相機尼康Z fc(產品詳情)和2款鏡頭,標準變焦鏡頭尼克爾 Z DX 16–50mm f/3.5–6.3 VR(產品詳情)的銀色版本,以及採用與尼康Z fc相
2021-06-29 14:44:02

今天,尼康終於釋出了傳聞已久的Z fc,復古風微單相機,雖然是半幅相機,但這款產品打造的還是很有特色的,可以說是古色古香,且不乏現代科技技術。Z fc採用了2088萬畫素CMOS,檔案格式12
2021-06-29 14:24:52

嗨嘍,各位同學又到了公佈CDA資料分析師認證考試LEVEL II的模擬試題時間了,今天給大家帶來的是模擬試題(二)中的81-85題。不過,在出題前,要公佈上一期LEVEL II中76-79題的答案,大家
2021-06-29 14:23:58
聯想宣佈在海外市場推出Yoga Tab 13,這是一款Android平板電腦,而且配備了一個Micro-HDMI視訊輸入介面,可以作為副屏/顯示器使用。Yoga Tab 13與此前聯想在國內發售的Yoga Pad P
2021-06-29 14:23:24