導讀:我們在實現檢測一個字元串是否包含另一個字元串時,簡單的用一個字元串匹配演算法就可以實現,如果要實現檢測一個字元串是否包含 N 個字元串時,這個 N 有可能上千萬,再利用簡
2021-07-22 03:04:22
導讀:我們在實現檢測一個字元串是否包含另一個字元串時,簡單的用一個字元串匹配演算法就可以實現,如果要實現檢測一個字元串是否包含 N 個字元串時,這個 N 有可能上千萬,再利用簡單的字元串匹配演算法就沒法滿足我們的需求了,上千萬的詞需要可以靈活的維護,業務方匹配時能夠拿到自己的詞進行匹配,千萬詞的匹配需要保證匹配速度,要在秒級之內出結果。所以,我們需要一套解決此類問題的方案——詞表服務 。
全文5370字,預計閱讀時間 12分鐘。
內容稽核平臺需要檢測作者發的文章中是否含有特殊的敏感詞。對於不同的業務線對這些詞的要求也不同,有的嚴格有的寬鬆;有的需要單詞,有的需要多詞;有的需要檢測出隱含詞、變體詞;有的在標題生效,有的在正文生效;有的檢測出送人審,有的檢測出直接拒絕;有的需要幾千詞,有的需要上萬、百萬、甚至千萬詞。對於這些詞各業務線可以自己維護,方便增加、刪除、修改,各業務可以根據自己的需求配置詞的生效規則;在檢測的時候業務方可以拿到自己維護的詞對文章進行檢測,而且需要保證檢測的時效,能夠實時拿到檢測結果。

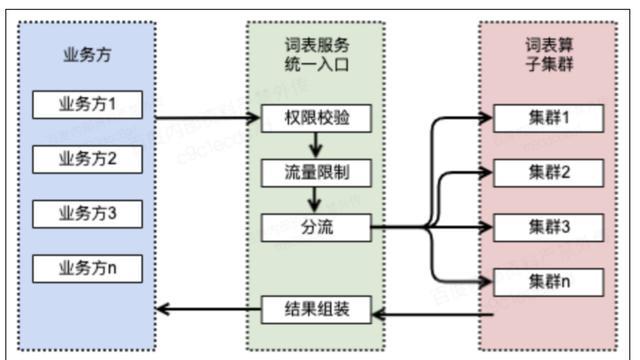
上圖是詞表服務的整體架構:
(1)詞表管理:各業務線在詞表管理平臺維護自己的詞表,每個業務線可以新增多個詞表組,每個詞表組中可以維護敏感詞以及可以動態新增敏感詞的屬性;詞表管理平臺用ES實現了對詞表及上千萬詞高效的分詞檢索能力;詞表管理會定時生成各業務線的詞表BOS檔案,上傳到BOS服務。
(2)服務層:業務方呼叫詞表服務統一對外的匹配介面,服務層將匹配任務送到策略運算元層,完成詞表的匹配功能。詞表對外的統一服務相當於一個簡單的閘道器,提供了鑑權功能,驗證請求是否合法;提供了流量限制的功能,可以為每個請求方設定流量限制值;提供了結果處理的功能,策略運算元返回的敏感詞屬性只是一部分,根據業務方的需求,可以完善策略運算元返回的敏感詞屬性;提供了流量轉發的功能,可以根據配置將各業務線的請求打到不同的叢集,實現各業務策略運算元分叢集部署。
(3)策略運算元層:策略運算元實現對文字中敏感詞的匹配,匹配的模式有包含匹配、強過濾匹配、多模匹配,命中的敏感詞會返回給詞表服務層。各業務線的詞表會被策略的每個運算元用全量重新整理的方式或者實時同步增量資料的方式載入到記憶體,支援運算元的匹配功能。全量重新整理的方式:詞表管理平臺會定時將詞表分業務線生成BOS檔案,上傳到 BOS 服務,策略運算元定時從BOS檔案中同步敏感詞到記憶體;實時同步的方式:策略運算元會實時掃描刺詞表資料庫,將增量的詞表載入到記憶體。
(4)基礎服務:GDP框架實現了詞表服務開發,Pandora平臺實現了詞表服務的部署,mysql 實現了詞表資料的儲存,ES實現了詞表的分詞檢索,bdrp實現了限流及快取功能,BOS服務實現了詞表檔案的的傳輸。
詞表管理平臺,實現了各業務線維護自己的詞表,每個業務線下可以創建多個詞表組,方便業務方分類管理自己的敏感詞,每個詞表組的含義由業務方賦予,具體體現在當命中的敏感詞屬於這個詞表組的時候,業務方是否根據詞表組做不同的處置;每個詞表組下可以維護敏感詞,敏感詞的屬性由業務方自己選擇,例如,稽核類型這個屬性,業務方可以根據命中具體某個敏感詞後要送審,就選擇送審詞這個屬性值,如果要拒絕就選擇拒絕詞這個屬性值。
各業務線可以新增、修改的詞表,可以對詞表進行檢索。
(1)新增詞表,選擇屬於的業務線,新增名字和備註,可以一次將詞表創建到多個業務線下,如果其他業務線有詞表可以複用,也可直接將其他業務線的詞表拷貝到自己新建的詞表下,方便快捷,方便管理人員對詞表的管理。如圖1:

(1)修改詞表,可以修改詞表的名字、備註,可以將詞表重新指定業務線,如果其他業務線有詞表可以複用,也可直接將其他業務線的詞表拷貝到自己的詞表下,方便快捷,方便管理人員對詞表的管理。如圖2:

(2)詞表檢索,支援通過詞表ID、詞表名稱、業務線以及創建的時間檢索詞表;詞表名稱的檢索,利用了 ES 的特性可以實現對詞表名稱進行分詞檢索;在檢索到的列表中,可以看到詞表的id、詞表名稱、業務線、詞表的創建時間、更新時間、每個詞表下的詞條數量、詞表備註、詞表的生效狀態操作人等詞表屬性;可以在列表中狀態中點選,將詞表改成生效或失效狀態;在操作欄可以點選修改,修改詞表,點選追加給詞表新增詞,點選檢視檢視詞表的詳情資訊。如圖3:

在詞表中可以高效快捷的維護敏感詞。重要的敏感詞的屬性包含:
(1) 詞條類型:標識敏感詞是送審詞還是過濾詞;
(2) 敏感類型:標識詞條的敏感分類;
(3) 匹配模式:包含匹配-檢測本文中是否包含敏感詞,強過濾匹配-檢測文字中漢字、字母、數字、特殊字元相互組合後是否包含敏感詞,多模匹配-檢測文字中是否命中2個或3個詞,且多個詞間距在有效範圍內。
(4) 生效位置:敏感詞在文章中的生效位置,如,標題、正文、圖片中給的文字等。
(5) 豁免詞:包含匹配中敏感詞的屬性,如果敏感詞是A,豁免詞是B,文字中有AB詞,則敏感詞A不會命中。
(6) 延展策略:多模位置置換-如果有多模詞AB,文字中有詞BA,則可以命中AB敏感詞;字母大小寫轉換-忽略大小寫,如果敏感詞是cd,文字中有cD、Cd、CD詞,則都可命中cd詞。
(7) 失效時間:提供了長期有效和具體失效時間兩種選擇。
敏感詞維護提供了單條新增、批量新增、單條修改、批量修改、詞表檢索、詞條檢索等功能:
(1)單條追加,追加的詞表名稱已經確定,業務方可以根據自己的業務選擇詞的屬性,追加中的操作,如果詞的匹配模式屬性選擇了包含詞,可以新增這個詞的豁免詞。如圖4:

(2)批量新增,支援同步最大一次新增3000條,可以同時新增到不同業務線的不同的詞表中,方便快捷,方便了管理員對敏感詞的維護工作,要新增的所有的敏感詞屬性必須一致才可以使用此功能,二期不支援給包含詞新增豁免詞屬性,可以在敏感詞輸入框中換行輸入多條。如圖5:

(3)批量創建,業務方可以根據自己的業務將敏感詞及屬性維護到EXCEL表中,每個檔案最大支援3萬詞,提交後,可以生成一個創建任務,後臺運行,同時可以創建多個任務,執行的時候是順序執行,如圖6:

(3)單條修改,可以修改詞條的任意屬性,如果敏感詞是同步批量新增的包含詞,想要新增敏感詞的豁免詞可以在這裡修改。如圖7:

(3)批量修改,業務方可以根據自己的業務將敏感詞及要修改的屬性維護到EXCEL表中,每個檔案最大支援3萬詞,提交後,可以生成一個更新任務,後臺運行,同時可以創建多個更新任務,執行的時候是順序執行。如圖8::

(4)敏感詞檢索,可以根據敏感詞的稽核類型、匹配模式、生效位置、敏感類型、操作人、所屬業務線、所屬詞表、敏感詞的創建時間等屬性檢索,敏感詞的檢索使用了ES分詞檢索的特性,可以支援分詞檢索,也可以實現精確檢索;檢索的列表中展示了敏感詞的名稱、所屬業務線、所屬詞表、操作人、操作時間、備註等欄位,可以檢視總體數量,可以匯出,批量解除,操作欄中,可以點選修改,進入修改頁面,可以點選解除,解除此條敏感詞。如圖9:

詞表服務統一入口,提供了標準的 API 介面,業務方呼叫詞表服務統一對外的匹配介面,服務層將匹配任務送到策略運算元層,完成詞表的匹配功能。詞表對外的統一服務相當於一個簡單的閘道器,提供了鑑權功能,驗證請求是否合法;提供了流量限制的功能,可以為每個請求方設定流量限制值;提供了結果處理的功能,策略運算元返回的敏感詞屬性只是一部分,根據業務方的需求,可以完善策略運算元返回的敏感詞屬性;提供了流量轉發的功能,可以根據配置將各業務線的請求打到不同的叢集,實現各業務策略運算元分叢集部署。具體的流程,如圖10。

策略載入詞表經過多方案的迭代,方案最終逐漸成熟穩定。
第一版詞表在策略的生效方案:詞表管理平臺將所有的業務線的詞表生成一個詞表檔案,上傳到BOS,詞表策略30min定時掃描載入一次。所有業務線集中到一個詞表檔案中,一次載入,導致了策略載入詞表速度慢。
第二版的方案,30分鐘生效時間後來不能滿足業務方的需求,詞表管理平臺按照業務線生成多個詞表檔案,推送到BOS系統,詞表策略定時,分業務線開啟多執行緒載入詞表,詞表生效時間由 30min 減少到5分鐘。
單三版方案,5min鍾時間對於特殊場景還是不滿足,我們增加了詞表實時同步方案,由詞表策略10s定時去資料庫掃描增量的資料載入到記憶體,但是這種方案不適合上萬的增量資料載入,只適合萬級以內詞的載入。
現在詞表策略載入詞表,第二版和第三版同時存在,優勢互補,整個演變過程如圖11:

BOS檔案格式,多列用製表符分割,多模詞用 & 符號連線,包含詞新增字首+號識別,主要的資訊有敏感詞id、敏感詞名稱、敏感詞所屬詞表id、多模詞詞間距、失效時間、稽核類型、匹配類型、所屬業務線、生效位置、敏感類型、延展策略、豁免詞。如圖12:

全量載入和增量實時同步載入流程,全量載入會在啟動的時候載入一次,載入的頻率半個小時以上,可以根據業務線配置;增量實時同步10s中去資料庫檢測一次是否有增量資料,然後分頁載入到記憶體。如圖13:

策略快取詞表到記憶體的載入結構,如下:
(1)業務線、生效位置,敏感詞,敏感詞id 字典對映。匹配到敏感詞,可以根據業務線,生效位置,快速的找到敏感詞的id,通過敏感詞的 id 再獲取敏感詞的屬性規則,用於計算匹配到的敏感詞是否有效。如圖14:

(2)敏感詞id及敏感詞屬性規則字典對映,BOS檔案每行敏感詞處理儲存。通過敏感詞ID能夠快速查到敏感詞的屬性規則,用於計算匹配到的敏感詞是否有效。如圖15:

(3)敏感詞掛在到字典樹(Trie樹),每個業務線、生效位置生成一個字典樹,字典樹是詞表策略的核心,上千萬的敏感詞匹配能在10ms以內返回配置結果。如圖16:

策略配置匹配流程,如圖17:

(1)輸入匹配參數,request_id請求的唯一標識,用於上下游定位,req_from請求來源,用於識別請求業務方,token用於許可權校驗,service_line業務線標識,用於識別匹配用的詞表,conent要匹配的文字,以及文字的配置,用於識別需要哪個生效位置的敏感詞。如圖18:

(2)將文字中的中文、字母、數字、特殊符號抽取組合生成不同組合的文字片段,用於強過濾匹配。如圖19:

(3)根據業務線以及文字的位置將文字送到對應的字典樹匹配出單個敏感詞,資訊包含敏感詞、敏感詞在文字中的位置、敏感詞的長度,位置和長度用於多模詞,詞間距是否有效的計算。匹配出的結果,如圖20:

(4)通過業務線,生效位置、敏感詞,從 match_data(圖13)快取中獲取到敏感詞所屬的敏感詞ID,再通過敏感詞ID從line_cahe快取中獲取到敏感詞的屬性規則;如果匹配到的敏感詞是包含詞或者過濾詞,直接命中輸出;如果是多模詞,則再查詢多模詞中的其他詞是否命中,如果命中切兩個詞的順序和詞間距滿足多模詞的屬性規則,則命中輸出。結果返回,如圖21:

PGC圖文經常有幾十萬字的大文字文章過詞表,由於字數太多,召回的詞量能達到幾萬,這些詞在做匹配規則計算時耗時太長,導致匹配超時。
優化方案如圖21:
(1)優化前,一個大文字文章,標題字數100,正文19.9w,詞表匹配時先匹配標題,耗時10ms,再匹配正文,由於正文字數多,耗時19s,最終匹配的耗時兩者累加達到20s。
(2)優化後,大文字文章過詞表,先將字數超過5000的正文,拆成多個小於等於5000的正文,詞表匹配時,多個文字片段並行匹配,最終耗時結果是多個平行計算中耗時最大的一個,我舉的例子50ms。

字典樹匹配演算法使用了廠內的開源C++庫 dictmatch,dictmatch實現了最簡單的Trie樹的演算法,沒有進行穿線改進,因此是需要回朔的。但是其使用2個表來表示Trie樹,並對其佔用空間大的問題進行了很大的優化,特點是在建樹的時候比較慢,但在查詢的時候非常快。
字典樹結構,如圖23:

詞表特殊字元支援:現在的詞表詞的儲存以及字典樹的匹配演算法對於表情及其他特殊字元不支援,詞表服務下一步的優化迭代會主要放在特殊字元的支援上,能夠滿足更多業務的需求。
詞表分業務線部署:現在詞表服務 60+ 的業務方,各業務線都是混部,所有業務線的詞表都在例項中載入一份,耗費記憶體特大,而且詞表服務出問題會影響所有的業務方;如果每個業務線都分叢集部署,會增加維護成本,所以我們在探索一種自動分業務線部署的方式。
作者:百度Geek說
連結:https://juejin.cn/post/6986882343998849060
來源:掘金
相關文章
導讀:我們在實現檢測一個字元串是否包含另一個字元串時,簡單的用一個字元串匹配演算法就可以實現,如果要實現檢測一個字元串是否包含 N 個字元串時,這個 N 有可能上千萬,再利用簡
2021-07-22 03:04:22

全球缺芯,對各行各業的影響還在繼續,最直接的表現之一就是相關行業消費品價格的持續走高,而全球缺芯歸根結底是疫情造成的。那麼問題來了,國內各行各業生產力早就火力全開,為何還
2021-07-22 03:04:15

近日,iOS版微信迎來了8.0.8/9正式版更新,加入了多個實用新功能,引發不少網友關注,並上了熱搜。不過,新版微信首發只有iOS版,安卓使用者無緣體驗,引發大量安卓使用者不滿。隨後,微信
2021-07-22 03:04:04

去年,中興亮出全球首款屏下鏡頭手機——中興Axon20,該機上市後,成功引起不少人的關注。由於中興Axon20是全球首款使用屏下鏡頭技術的手機,噱頭十足,因此手機上市後在很長一段時間
2021-07-22 03:03:55

因為眾所周知的原因,過去的這一年多以來,全球各地都在努力的發展晶片製造產業。比如美國拋出520億美元計劃,計劃未來5年在半導體領域至少投入520億美元,以確保美國保持晶片生產
2021-07-22 03:03:48

2021年7月21日—中國 · 北京—全球成長最快的智慧手機品牌realme 真我於今日在北京舉辦真我GT大師系列旗艦新品釋出會。作為realme兩週年夢想之作,真我GT 大師系列的外觀設
2021-07-22 03:03:39