這篇來自 CMU 和 HKUST 科研團隊的 ICML 論文,僅通過調整訓練演算法,在 ImageNet 資料集上取得了比之前的 SOTA BNN 網路 ReActNet 高1.1% 的分類精度。
二值化網路(BNN)是一種網路壓縮方法,把原本需要 32 bit 表示的神經網路參數值和啟用值都二值化到只需要用 1 bit 表示,即 -1/+1 表示。
這種極度的壓縮方法在帶來優越的壓縮效能的同時,會造成網路精度的下降。
在今年的 ICML 會議中,一篇來自 CMU 和 HKUST 科研團隊的論文僅通過調整訓練演算法,在 ImageNet 資料集上取得了比之前的 SOTA BNN 網路 ReActNet 高 1.1% 的分類精度,最終的 top-1 accuracy 達到 70.5%,超過了所有同等量級的二值化網路,如下圖所示。
這篇論文從二值化網路訓練過程中的常見問題切入,一步步給出對應的解決方案,最後收斂到了一個實用化的訓練策略。接下來就跟著這篇論文一起看看二值化網路(BNN)應該如何優化。
可以看到,BNN 的優化曲面明顯不同於實數值網路,如下圖所示。實數值網路在局部最小值附近有更加平滑的曲面,因此實數值網路也更容易泛化到測試集。相比而言,BNN 的優化曲面更陡,因此泛化性差並且優化難度大。
這個明顯的優化區別也導致了直接沿用實數值網路的 optimizer 在 BNN 上表現效果並不好。目前實數值分類網路的通用優化器都是 SGD,該論文的對比實驗也發現,對於實數值網路而言,SGD 的效能總是優於自適應優化器 Adam。但對於 BNN 而言,SGD 的效能卻不如 Adam,如下圖所示。這就引發了一個問題:為什麼 SGD 在實數值分類網路中是預設的通用優化器,卻在 BNN 優化中輸給了 Adam 呢?
這就要從 BNN 的特性說起。因為 BNN 中的參數值(weight)和啟用值(activation)都是二值化的,這就需要用 sign 函數來把實數值的參數和啟用值變成二值化。
而這個 Sign 函數是不可導的,所以常規做法就是對於二值化的啟用值用 Clip 函數的導數擬合 Sign 函數的導數。
這樣做有一個問題就是,當實數值的啟用值超出了 [-1,1] 的範圍,稱為啟用值過飽和(activation saturation),對應的導數值就會變為 0。從而導致了臭名昭著的梯度消失(gradient vanishing)問題。從下圖的視覺化結果中可以看出,網路內部的啟用值超出[-1, 1] 範圍十分常見,所以二值化優化裡的一個重要問題就是由於啟用值過飽和導致的梯度消失,使得參數得不到充分的梯度估計來學習,從而容易困局部次優解裡。
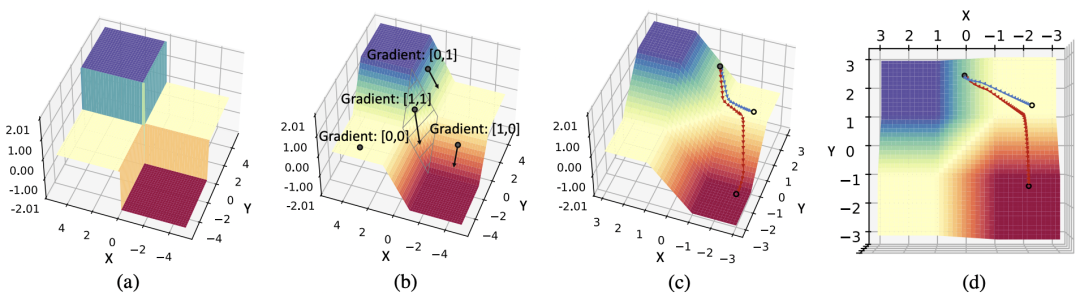
而比較 SGD 而言,Adam 優化的二值化網路中啟用值過飽和問題和梯度消失問題都有所緩解。這也是 Adam 在 BNN 上效果優於 SGD 的原因。那麼為什麼 Adam 就能緩解梯度消失的問題呢?這篇論文通過一個構造的超簡二維二值網路分析來分析 Adam 和 SGD 優化過程中的軌跡:
圖中展示了用兩個二元節點構建的網路的優化曲面。(a) 前向傳遞中,由於二值化函數 Sign 的存在,優化曲面是離散的,(b) 而反向傳播中,由於用了 Clip(1, x, 1)的導數近似 Sign(x)的導數,所以實際優化的空間是由 Clip(1, x, 1)函陣列成的, (c) 從實際的優化的軌跡可以看出,相比 SGD,Adam 優化器更能克服零梯度的局部最優解,(d) 實際優化軌跡的頂檢視。
在圖 (b) 所示中,反向梯度計算的時候,只有當 X 和 Y 方向都落在[-1, 1] 的範圍內的時候,才在兩個方向都有梯度,而在這個區域之外的區域,至少有一個方向梯度消失。
而從下式的 SGD 與 Adam 的優化方式比較中可以看出,SGD 的優化方式只計算 first moment,即梯度的平均值,遇到梯度消失問題,對相應的參數的更新值下降極快。而在 Adam 中,Adam 會累加 second moment,即梯度的二次方的平均值,從而在梯度消失的方向,對應放大學習率,增大梯度消失方向的參數更新值。這樣能幫助網路越過局部的零梯度區域達到更好的解空間。
進一步,這篇論文展示了一個很有趣的現象,在優化好的 BNN 中,網路內部儲存的用於幫助優化的實數值參數呈現一個有規律的分佈:
分佈分為三個峰,分別在 0 附近,-1 附近和 1 附近。而且 Adam 優化的 BNN 中實數值參數接近 - 1 和 1 的比較多。這個特殊的分佈現象就要從 BNN 中實數值參數的作用和物理意義講起。BNN 中,由於二值化參數無法直接被數量級為 10^-4 左右大小的導數更新,所以需要儲存實數值參數,來積累這些很小的導數值,然後在每次正向計算 loss 的時候取實數值參數的 Sign 作為二值化參數,這樣計算出來的 loss 和導數再更新實數值參數,如下圖所示。
所以,當這些實數值參數靠近零值時,它們很容易通過梯度更新就改變符號,導致對應的二值化參數容易跳變。而當實值參數的絕對值較高時,就需要累加更多往相反方向的梯度,才能使得對應的二值參數改變符號。所以正如 (Helwegen et al., 2019) 中提到的,實值參數的絕對值的物理意義可以視作其對應二值參數的置信度。實值參數的絕對值越大,對應二值參數置信度更高,更不容易改變符號。從這個角度來看,Adam 學習的網路比 SGD 實值網路更有置信度,也側面印證了 Adam 對於 BNN 而言是更優的 optimizer。
當然,實值參數的絕對值代表了其對應二值參數的置信度這個推論就引發了另一個思考:應不應該在 BNN 中對實值參數施加 weight decay?
在實數值網路中,對參數施加 weight decay 是為了控制參數的大小,防止過擬合。而在二值化網路中,參與網路計算的是實數值參數的符號,所以加在實數值參數上的 weight decay 並不會影響二值化參數的大小,這也就意味著,weight decay 在二值化網路中的作用也需要重新思考。
這篇論文發現,二值化網路中使用 weight decay 會帶來一個困境:高 weight decay 會降低實值參數的大小,進而導致二值參數易變符號且不穩定。而低 weight decay 或者不加 weight decay 會使得二值參數將趨向於保持當前狀態,而導致網路容易依賴初始值。
為了量化穩定性和初始值依賴性,該論文引入了兩個指標:用於衡量優化穩定性的參數翻轉比率(FF-ratio),以及用於衡量對初始化的依賴性的初始值相關度 (C2I-ratio)。兩者的公式如下,
FF-ratio 計算了在第 t 次迭代更新後多少參數改變了它們的符號,而 C2I -ratio 計算了多少參數與其初始值符號不同。
從下表的量化分析不同的 weight decay 對網路穩定性和初始值依賴性的結果中可以看出,隨著 weight decay 的增加,FF-ratio 與 C2I-ratio 的變化趨勢呈負相關,並且 FF-ratio 呈指數增加,而 C2I-ratio 呈線性下降。這表明一些參數值的來回跳變對最終參數沒有貢獻,而只會影響訓練穩定性。
那麼 weight decay 帶來的穩定性和初始值依賴性的兩難困境有沒有方法解離呢? 該論文發現最近在 ReActNet (Liu et al., 2020) 和 Real-to-Binary Network (Brais Martinez, 2020) 中提出的兩階段訓練法配合合適的 weight-decay 策略能很好地化解這個困境。這個策略是,第一階段訓練中,只對啟用值進行二值化,不二值化參數。由於實數值參數不必擔心二值化參數跳變的問題,可以新增 weight decay 來減小初始值依賴。隨後在第二階段訓練中,二值化啟用值和參數,同時用來自第一步訓練好的參數初始化二值網路中的實值參數,不施加 weight decay。這樣可以提高穩定性並利用預訓練的良好初始化減小初始值依賴帶來的弊端。通過觀察 FF-ratio 和 C2I-ratio,該論文得出結論,第一階段使用 5e-6 的 weight-decay,第二階段不施加 weight-decay 效果最優。
該論文綜合所有分析得出的訓練策略,在用相同的網路結構的情況下,取得了比 state-of-the-art ReActNet 超出 1.1% 的結果。實驗結果如下表所示。