一、簡介影象分類是我們想要預測哪個類別屬於影象的任務。由於影象表示,這項任務很困難。如果我們將影象鋪平,它會創建一個長長的一維向量。此外,該表示將丟失相鄰資訊。因此,我
2021-07-24 03:13:36
影象分類是我們想要預測哪個類別屬於影象的任務。由於影象表示,這項任務很困難。如果我們將影象鋪平,它會創建一個長長的一維向量。此外,該表示將丟失相鄰資訊。因此,我們需要深度學習來提取特徵並預測結果。

有時,構建深度學習模型會成為一項艱鉅的任務。雖然我們為影象分類創建了一個基礎模型,但需要花大量時間來創建程式碼。我們必須準備好用於準備資料、訓練模型並測試模型的程式碼,並將模型部署到伺服器上。這時Flash就有了用武之地!
Flash是一種高階深度學習框架,用於快速構建、訓練和測試深度學習模型。Flash基於PyTorch框架。所以如果您瞭解PyTorch,就會很熟悉Flash。
與PyTorch和Lighting相比,Flash易於使用,但不如以前的庫靈活。如果您想構建更復雜的模型,可以使用Lightning或直接使用PyTorch。

藉助Flash,您可以用幾行程式碼構建深度學習模型!因此,如果您剛接觸深度學習,別害怕。Flash可以幫助您構建深度學習模型,不會因程式碼而感到困惑。
本文將介紹如何使用Flash構建影象分類器。
想安裝庫,您可以使用pip命令,如下所示:
pip install lightning-flash
如果該命令不起作用,可以使用其GitHub儲存庫安裝該庫。命令如下所示:
pip install git+https://github.com/PyTorchLightning/lightning-flash.git
在我們可以成功下載軟體包之後,現在可以載入庫。我們還將種子設為編號42。這是執行此操作的程式碼:
from pytorch_lightning import seed_everything import flash from flash.core.classification import Labels from flash.core.data.utils import download_data from flash.image import ImageClassificationData, ImageClassifier # set the random seeds. seed_everything(42) Global seed set to 42 42
安裝完庫後,現在不妨獲取資料。出於演示需要,我們將使用名為Cat和Dog資料集的資料集。
該資料集含有兩個類別:貓和狗的影象。想訪問資料集,您可以在Kaggle找到該資料集。可以在此處訪問資料集。

下載資料後,不妨將資料集載入到一個物件中。我們將使用from_folders方法將資料放入到ImageClassification物件中。這是執行此操作的程式碼:
datamodule = ImageClassificationData.from_folders( train_folder="cat_and_dog/training_set", val_folder="cat_and_dog/validation_set", )
我們載入資料後,下一步就是載入模型。由於我們不會從頭開始構建自己的架構,將使用基於現有卷積神經網路架構的預訓練模型。
我們將使用已經過預訓練的ResNet-50模型。此外,我們基於資料集設定類別的數量。這是執行此操作的程式碼:
model = ImageClassifier(backbone="resnet50", num_classes=datamodule.num_classes)
載入模型後,現在不妨訓練模型。我們需要先初始化Trainer物件。我們將用3個輪次(epoch)訓練模型。此外,我們啟用GPU以訓練模型。這是執行此操作的程式碼:
trainer = flash.Trainer(max_epochs=3, gpus=1) GPU available: True, used: True TPU available: False, using: 0 TPU cores
初始化物件後,不妨訓練模型。為訓練模型,我們可以使用一個名為finetune的函數。在函數裡面,我們設定模型和資料。此外,我們將訓練策略設定為freeze(凍結),這表明我們不想訓練特徵提取器。換句話說,我們只訓練分類器部分。
這是執行此操作的程式碼:
trainer.finetune(model, datamodule=datamodule, strategy="freeze") LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0] | Name | Type | Params ---------------------------------------- 0 | metrics | ModuleDict | 0 1 | backbone | Sequential | 23.5 M 2 | head | Sequential | 4.1 K ---------------------------------------- 57.2 K Trainable params 23.5 M Non-trainable params 23.5 M Total params 94.049 Total estimated model params size (MB) Validation sanity check: 0it [00:00, ?it/s] Global seed set to 42 Training: 0it [00:00, ?it/s] Validating: 0it [00:00, ?it/s] Validating: 0it [00:00, ?it/s] Validating: 0it [00:00, ?it/s]
這是評估結果:

從結果中可以看出,我們的模型其準確率達到了約97%。不賴!現在不妨拿幾個新資料測試模型。
我們將使用針對該模型沒有訓練過的樣本資料。以下是我們將測試模型的樣本:
import matplotlib.pyplot as plt from PIL import Image fig, ax = plt.subplots(1, 5, figsize=(40,8)) for i in range(5): ax[i].imshow(Image.open(f'cat_and_dog/testing/{i+1}.jpg')) plt.show()為了測試模型,我們可以使用flash庫中的predict方法。這是執行此操作的程式碼:
model.serializer = Labels() predictions = model.predict(["cat_and_dog/testing/1.jpg", "cat_and_dog/testing/2.jpg", "cat_and_dog/testing/3.jpg", "cat_and_dog/testing/4.jpg", "cat_and_dog/testing/5.jpg"]) print(predictions) ['dogs', 'dogs', 'cats', 'cats', 'dogs']
從上面的結果可以看出,模型預測了帶有正確標籤的樣本。很好!不妨儲存模型以備後用。
我們已訓練並測試了模型。不妨使用save_checkpoint方法儲存模型。這是執行此操作的程式碼:
trainer.save_checkpoint("cat_dog_classifier.pt")如果您想針對其他程式碼載入模型,可以使用load_from_checkpoint方法。這是執行此操作的程式碼:
model = ImageClassifier.load_from_checkpoint("cat_dog_classifier.pt")做得好!您已學習瞭如何使用Flash構建影象分類器。正如文章開頭所說,它只需要幾行程式碼!是不是很酷?
但願本文可以幫助您根據自己的情況構建自己的深度學習模型。如果您想實施一個更復雜的模型,但願能開始學習 PyTorch。
相關文章

一、簡介影象分類是我們想要預測哪個類別屬於影象的任務。由於影象表示,這項任務很困難。如果我們將影象鋪平,它會創建一個長長的一維向量。此外,該表示將丟失相鄰資訊。因此,我
2021-07-24 03:13:36

隨著釋出時間的臨近,iPhone 13的輪廓變得愈發清晰。目前已經確定的是,iPhone 13主要升級了劉海屏,相機進一步增強,電池容量小幅度增加,然後還有兩個新顏色。因為A15依然擠牙膏,iPh
2021-07-24 03:13:28

氮化鎵充電器有哪些優點,相信大家都很清楚了,大致就是發熱量低、功率更大,更適合高功率手機和膝上型電腦的供電用途。現在叫得上名字的配件品牌,都有屬於自己的氮化鎵產品了。因
2021-07-24 03:13:07

白色的RGB主機一直是很多玩家所向往的,今天我們就來裝一臺,供大家參考。主題當然是以白色為主,硬體的RGB燈效要支援神光同步。至於效能,可以在2K、4K高特效下暢玩最新的3A遊戲大
2021-07-24 03:12:34

#一加手機#OnePlus Nord 2 5G釋出,採用天璣 1200-AI處理器及 IMX766感光元件OnePlus Nord 2 5G在 7月 22日如期於印度釋出,為這款暢銷的中端定位手機系列帶來續作,搭載天璣 120
2021-07-24 03:12:28
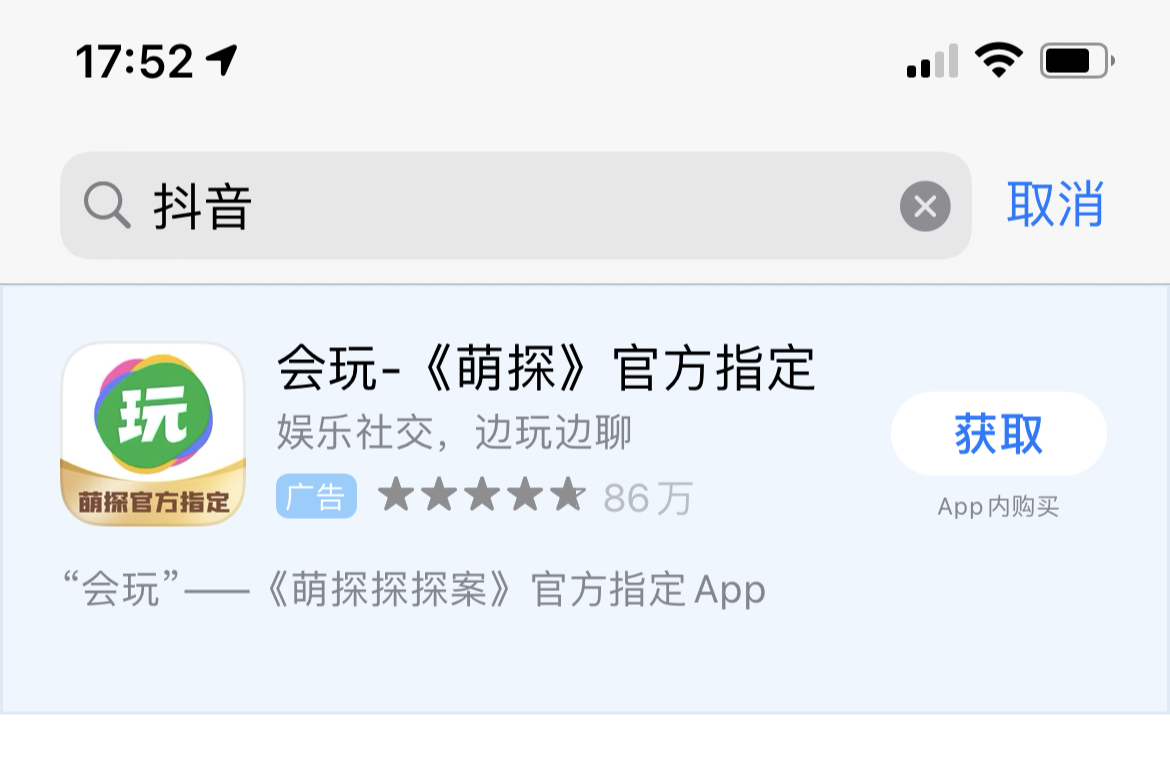
不少小夥伴發現,蘋果旗下的App Store中加入了廣告,具體表現在搜尋軟體的時候,第一個出現的並不是消費者想要的軟體,而是一個廣告;在這之前,消費者搜尋軟體的時候,第一個會出現最貼
2021-07-24 03:12:20