引言在服務端的業務開發中,我們經常會使用到各種各樣的快取,不管是localCahce還是memcache,其目的都是為了記錄上一次的計算結果,用於優化效能的。服務端很多時候做的工作,其實就
2021-08-04 03:03:00
引言
在服務端的業務開發中,我們經常會使用到各種各樣的快取,不管是localCahce還是memcache,其目的都是為了記錄上一次的計算結果,用於優化效能的。服務端很多時候做的工作,其實就是花式的crud,而其中的花式,主要就提現在快取的設計上,快取設計的好,可以有效的提示叢集的吞吐量,設計的不好,會極大的拉低系統的效能。
本文只是針對一些很簡單的點進行的總結,方法和原理都很簡單,但是落實到工作中,可能並不總能做得恰到好處。
高效使用的原則
先在這裡拋出我個人在工作中總結的結論,快取在程式碼中設計要遵守的原則
* 越少的快取使用,越有價值
* 離最終的計算結果越近,越有價值
* 對於需要消耗I/O資源的快取,要儘可能的減少呼叫的次數。

快取減輕了後端的壓力,提升了效能,但同時也會帶來一些問題,處理不好,可能帶來負面影響。這些問題不僅僅是 redis 才會碰到,只要是使用了快取這種策略都會面臨這些問題,比如 oracle 自身提供的快取機制,linux 對於讀寫檔案的 page cache。
使用快取意味著就有對應的後端儲存,資料同時會在快取和後端儲存存在,那麼就存在一致性的問題。快取與後端儲存一般是兩個獨立的元件,所以總結起來也就是分散式一致性的問題。
當然,對於一致性的需求,還是看業務需求,某些應用可以容忍不一致,則不用考慮一致性的問題;可以容忍一段時間的不一致,則採用最終一致性;不能容易不一致,則採用強一致。
對於快取的一致性,做得比較完善的或者商業的元件,比如 oracle 的 Coherence 會提供完善的一致性機制,典型的有 read through、fresh ahead、write through、write behind;如果沒有提供原生的一致性機制,則需要應用來處理了,也形成了固定的模式:cache aside。
read through 及其他 3 種模式,一般都有專門的快取管理服務,專門處理快取相關的功能,使快取對於應用透明。
該模式解決讀的問題,這裡的 through 是讀操作透過了快取達到後端儲存的意思。
總體思路:
1、嘗試從快取中查詢 key
2、如果快取沒有 key,則從後端儲存查詢、反饋給應用並載入到快取
3、如果快取有 key,直接返回
該種模式比較簡單,但查詢時,如果沒有命中快取,都會有去後端儲存查詢,效能就與損失。
該模式是解決 read through 快取沒有命中帶來的效能問題。
快取 key 都是有過期時間的,在這種模式下快取 key 將要過期時,則自動的非同步的從後端儲存查詢最新資料並載入到快取,這樣請求時就不必查詢後端儲存,從而提升效能。
該模式解決寫的問題,即所謂的雙寫,同時寫入到快取和後端儲存,兩個寫成功才算成功。這個模式和 read through 一樣,存在效能上的損失。
該模式是解決 write through 的效能損失。應用將資料寫到快取後算成功,稍後在非同步寫入到後端儲存,效能雖然有提升,但是一致性保障降低了,變成了最終一致。
如果要求比較完善的一致性機制,可以按照上述的 4 種模式實現,但在一般的牽扯到 redis 一類快取元件的業務場景中,沒有必要這麼完善,沒有必要有專門的快取管理服務,由應用自身來管理快取即可。
對於讀請求,可以完全按照 read through 模式實現,只不過具體過程由應用來完成。
對於寫請求,可以有不同的幾種策略,主要的區別還是在併發情況下的一致性保障程度。
每個執行緒都要執行更新後端儲存和更新快取兩步操作,但對於後端儲存和快取這兩步操作是獨立的,所以,不同執行緒之間的這些操作時序可能因為網路等原因錯亂,導致不一致。
1、先更新後端儲存,在更新快取
執行緒 A 更新後端儲存
執行緒 B 更新後端儲存
執行緒 B 更新快取
執行緒 A 更新快取
此時後端儲存是 B 的資料,快取是 A 的資料。這種方式一般不考慮。
2、先刪除快取,再更新資料庫
執行緒 A 執行寫操作,刪除快取,暫未將新資料寫入後端儲存
執行緒 B 執行讀操作,沒有快取,查詢到後端儲存舊資料
執行緒 A 將新資料寫入後端儲存
執行緒 B 將舊資料寫入快取
這種問題可以通過延時雙刪解決,執行緒 A 寫入後端儲存之後,等待一定延時,再次刪除快取。這種方案是不大靠譜的,關鍵是時延的選擇不確定。像上述的情況,時延太短,執行緒 B 還是會將舊資料寫入快取;時延太長,執行緒 A 接受不了,而且時延期間其他執行緒拿到的資料仍然是舊的。
3、更新資料庫,再刪除快取
這種模式,大部分情況是沒有問題的,但也有特殊情況會存在問題:
執行緒 A 執行讀操作,沒有快取,查詢到後端儲存舊資料
執行緒 B 執行寫操作並刪除快取
執行緒 A 將舊資料寫入快取
這種問題出現需要有比較苛刻的觸發條件:
1)讀操作快取沒有命中
2)執行緒 B 先於執行緒 A 執行(寫操作一般比讀慢,發生的概率比較低)
應用自行管理快取,儘量設定過期時間,這是一致性底線的保證,避免資料長期不一致。另外,如果對於一致性有更高的要求,可以結合訊息佇列等方式來及時的通知快取更新,但也會引入訊息佇列讓系統更加複雜。
穿透指查詢一個根本不存在的資料,則必然會穿透快取達到後端儲存,通常處於容錯的考慮,不會將空結果寫到快取,所以每次請求都會穿透,併發高時可能直接讓後端儲存宕掉。
穿透形成,可能是惡意攻擊、程式 bug 或者正常業務形成(比如使用者查一項不存在的資源)。
解決穿透問題,主要有兩個途徑:
1、快取空結果
如果是惡意攻擊或者程式 bug 導致的大量穿透,則快取會儲存大量的 key,佔用大量的儲存空間。從穿透形成的場景來看,快取資料都不大可能在較長時間後再次使用,此時可以設定較短的過期時間來改善儲存空間的問題。
2、布隆過濾器攔截
佔用空間比較少,但引入布隆過濾器後的程式碼維護以及資料載入本身存在一定的複雜度。
快取不能提供服務時,請求全部打到後端儲存,造成後端壓力劇增,導致宕掉。
解決方案主要是快取元件本身的高可用以及降級設計了。
如果一個 key 是熱點 key(併發訪問非常高),而且重建該 key 的快取比較耗時,當該 key 失效時,那意味著很多併發執行緒瞬間都來執行重建工作,會對後端儲存帶來很大壓力。
解決方案:互斥鎖,讓只有一個執行緒來執行重建操作,其他執行緒都等著。比如可以使用 redis 的 setnx 命令來實現,能設定成功的執行緒就重建,不能就 sleep,再次請求,此時資料可能就已經重建成功了.
相關文章

引言在服務端的業務開發中,我們經常會使用到各種各樣的快取,不管是localCahce還是memcache,其目的都是為了記錄上一次的計算結果,用於優化效能的。服務端很多時候做的工作,其實就
2021-08-04 03:03:00

Apple Watch 7 正式註冊按照供應鏈的說法,蘋果今年會在九月份準時舉辦秋季釋出會,正式推出 iPhone13 和 Apple Watch7 等產品。而在今天,蘋果按照慣例向歐亞資料庫註冊了一批新
2021-08-04 03:02:52

華為P50系列釋出了,令人遺憾的是沒有5G版本,全系均是4G版本,而且價格還比較昂貴,搭載驍龍888的華為P50,也需要4488元起步;華為P50 Pro就更貴了,售價達到5988元起步,這些4G手機實在太
2021-08-04 03:02:42
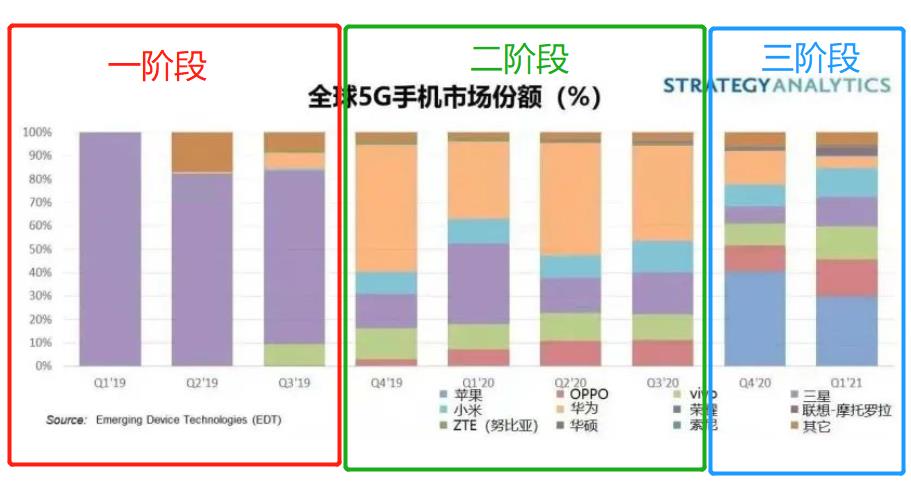
【8月3日訊】相信大家都知道,2019年被譽為「5G元年」,在全球範圍內掀起了一股5G網路建設狂潮,全球有超過幾十個國家的運營商正式宣佈邁入5G網路商用時代,而在2020年則掀起了一股
2021-08-04 03:02:38

在當前講究效率的時代,數碼行業自然也不落後。就好比現在的手機充電速度可謂是一浪更比一浪高,就差小米那個 200W 有線快充趕緊實現量產衝第一了。快充還是那個快充,但不知道小
2021-08-04 03:02:31

AMD在零售市場的APU其實很久沒有更新過了,雖然說去年的銳龍4000G系列是有桌面版,但它們僅面向商用與OEM市場,一直都沒出現在零售市場上,此前最新的桌面APU其實是更早期的Zen+架
2021-08-04 03:02:05