作者 | Coder的技術之路來源 | Coder的技術之路為了更好的體驗和更優的效能,其實RPC悄悄的做了很多工作,本篇就帶大家來看下RPC的一些高階特性和其背後的原因。(還是以開源的du
2021-08-04 03:12:50

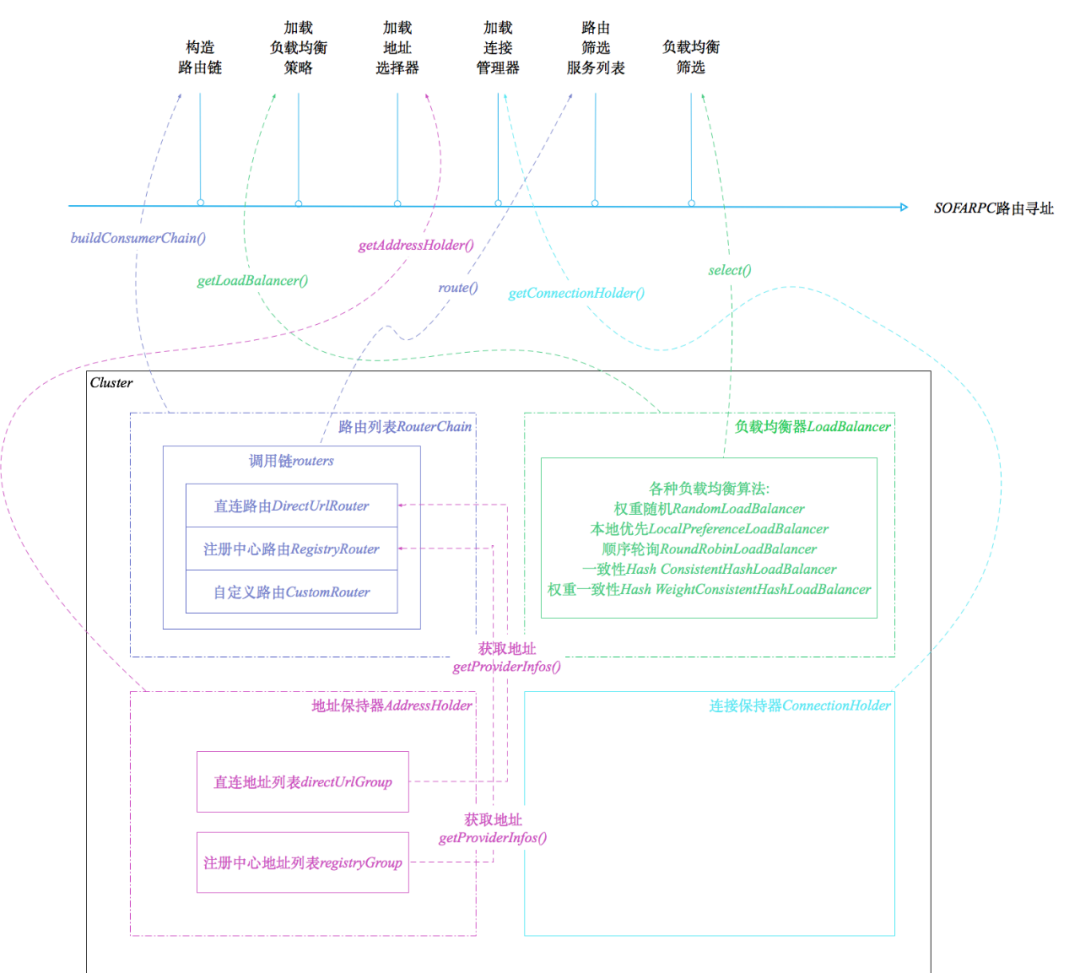
為了更好的體驗和更優的效能,其實RPC悄悄的做了很多工作,本篇就帶大家來看下RPC的一些高階特性和其背後的原因。(還是以開源的dubbo和sofa為例來說明) 路由定址,負載均衡是很好,可以保證流量均勻從而保護服務節點穩定。 但是,我們有的時候其實不希望我們的請求亂跑,最好能打到指定的機器上。比如聯調和測試的時候,直連功能就顯得很重要了。 只有經歷過多方合作聯調時請求到處亂跑的痛,才知道分組和直連的功能對開發是多麼的友好。 我們可以看到直連路由策略的order屬性,被賦予了一個極小的值,變成了優先順序最高的路由策略,所以只要配置的直連列表,則會優先走配置中的列表地址。 摘自:www.sofastack.tech Future非同步呼叫 非同步呼叫對服務效能和併發的支援起到很大的作用。 一般非同步呼叫有Futurn和callback等方式,這裡我們說下Future的原理: 呼叫下游之後,先返回一個Future,上游通過Future.get()方法對結果進行獲取,如果結果未返回則會讓出CPU資源進入等待,直到結果到達或超時後觸發回撥方法才被喚醒。由於篇幅問題,Future的核心邏輯的相關注釋就不放了,之前的訊息消費順序保障的文章中也有敘述,有興趣的同學可以看下~ 很多時候,我們會遇到消費端和服務端可能都是自己的情況。這個時候,在常規的路由定址之外,又提供給我們一種呼叫的可能性,就是直接呼叫當前伺服器上的程式,這樣做的好處比較明顯,省去了網路傳輸等時間損耗,效率更高。 當然,也需要看業務和內部服務路由的實際情況,比如在阿里的單元化部署下,需要根據使用者ID路由到對應的zone進行處理,如果還是優先本機,那就可能在操作資料庫的時候涉及到跨zone呼叫,比走遠端rpc更加耗時。因此這種情況下就需要禁用本機優先策略。 很多時候,我們的服務需要依賴一些其他內容才可以正常提供服務,比如快取預熱、執行緒池預熱等等,所以,在服務真正就緒之後再註冊到配置中心是很有必要的。 問:我們需要每次都進行路由定址和負載均衡來確定服務地址麼? 比如,有狀態的服務(很多帶資料功能的服務都是有狀態的,比如很久之前的帶登陸session的Tomcat服務、儲存叢集服務等),其實希望每次請求都連線到相同的伺服器。 這就用到了粘滯連線功能。 前面扯了那麼多,其實,這個才是我們今天想說的重點。 預熱轉發是針對服務節點的負載均衡來說的。因為在服務剛啟動的時候,如果請求過多可能會影響機器效能和正常業務,如果將處於預熱期的機器的請求轉發到叢集內其它機器,過了預熱期之後再恢復正常,則可以保證服務節點的效能和服務整體的可用性。 那麼這個功能是怎麼實現的呢?--帶權重的隨機負載均衡。 摘自sofastack:權重隨機的原理 配置示例: 如上,預熱權重20%,預熱持續時長60s。這樣,按照上述計算方式,權重小的服務節點被選到的機率就相對小,以此達到權重隨機的效果。 那麼,為什麼剛釋出的服務需要預熱呢?預熱可以起到什麼作用呢? 都說C++快,Java慢,都是高階語言,是什麼導致了運行速度的差別呢? 這個涉及到了兩種執行方式:解釋執行 和 編譯執行。 相對於C++直接將程式碼編譯成機器碼運行的方式,Java為了實現跨平臺、高度抽象等特性,增加了虛擬機器層來實現Java程式碼到機器碼的轉換,Java程式先是被編譯成符合虛擬機器規範的.class位元組碼逐條將位元組碼翻譯成機器碼然後執行,所以,速度上就慢一些。 雖然,JVM的加入,給Java的運行速度增加了不少損耗,但是好處也很多,除了跨平臺,還為我們實現了諸如記憶體管理、垃圾回收等容器級通用功能,讓研發人員可以更加聚焦業務。 不過,Java也是要面子的,我允許自己慢,但我不允許自己慢那麼多! 怎麼辦呢?遵循二八原則,是不是可以找尋程式當中的貢獻了大部分呼叫量的核心程式碼,把這部分編譯成機器碼,提升其速度,不就把整體的速度提上去了麼,JVM也是這麼做的~ 所以,JVM相容瞭解釋執行和編譯執行兩種方式,也就是我們常說的即時編譯。 前面的問題到這裡其實就可以回答了。為什麼需要預熱轉發呢?是為了用小流量對程式進行預熱,目的是為了讓核心程式碼進行及時編譯,提高峰值運行速率,提升服務響應~ 下面讓我們詳細看下JIT。 為了權衡編譯時間和執行效率,JVM設定了多種即時編譯器: C1(Client 編譯器):基於位元組碼完成部分優化,如方法內聯、常量傳遞,相對於C2,速度快,但效能稍差。 C2(Server 編譯器):耗時較長的全局優化,如無用程式碼消除、重排序、迴圈展開、公共子表示式替代、常量傳播等等。 Graal(新的JIT編譯器):側重於效能和語言操作性。在一些負載上提供比傳統編譯器更好的峰值效能;用 Graal 執行的語言可以互相呼叫,可以使用來自其他語言的庫。 前面我們說過,JVM其實是希望找到承擔更多呼叫請求的程式碼塊進行優化,那,怎麼來確認哪些程式碼時優化目標呢?--熱點探測 基於取樣的熱點探測: 基於計數的熱點探測: 另外,可以通過如XX:CompileThreshold等參數來修改閾值,不過,沒有絕對把握,還是不要動為好。 為什麼我們在剛寫程式碼的時候,總是被建議不要寫很大的方法體?方法內聯的JIT優化策略就是其中一個重要的原因。(還有GC友好等原因) JVM內的每一次方法呼叫,都是棧幀在記憶體中出棧入棧的過程,方法多了效能損耗自然大,所以要進行方法內聯,即把方法執行邏輯直接複製到呼叫方內部,避免方法呼叫。 但是,方法內聯是有方法大小限制的,超過了一定大小的方法,沒法做內聯優化。所以,平常應該注意,儘量避免寫很大很冗長的方法。 讓我們來舉個栗子實際感受一下~ 兩種書寫風格的大數相加 如上圖所示,兩個字元串型整數相加,都能實現功能,前一種寫法,把中間過程全都拆開,羅列在的方法內,整個方法雖然理解起來稍微方便些,但整體顯得冗長;第二種方法,把各個條件都囊括在了for迴圈條件內,三行程式碼完成整體操作。 如果要去評價,我覺得大部分人都會說第二種寫的好,但是,第二種的好難道真的侷限於優雅麼? 執行15000次寫法1 (圖中編譯層次這一列中,3代表C1編譯,4代表C2編譯) 我們看到,隨著程式碼的執行次數的增加,一些方法,進行了C1編譯,如我們的主方法stringAdd,而少數方法,從C1編譯提升到了C2編譯,如AbstractStringBuilder::append方法。 執行15000次寫法2 我們看到了什麼,stringAdd2 居然在進行到運行後期執行了C2編譯,而且很明顯,方法二的C2編譯的方法,比方法一要多不少。所以,平常寫程式碼該注意些什麼,是不是顯而易見了。。。 方法內聯雖然只是一種簡單優化,但是,是後續其他優化的基石。 而JVM的分層優化涉及的點非常多[1]: 局部優化:關注局部資料流分析,陣列越界檢查消除;寄存器優化,優化跳轉、迴圈、異常處理等;程式碼簡化,如公共表示式提取等等等。 控制流優化:專注於程式碼重排序、迴圈縮減、迴圈展開、異常定位優化等等等。 全局優化:主要關注冗餘消除,如方法呼叫、鎖;逃逸分析;GC和記憶體分配優化等等等。 本篇從RPC的預熱轉發功能,引出了其背後的理論依據--JIT優化。闡述了JIT的基本概念,並用一個例項說明了程式碼編寫風格對JIT優化的實際影響。 JIT相關的優化實現起來非常難,不過其原理和作用對我們普通研發也不是特別難理解,學習JIT優化的目的,在於瞭解JVM底層的運行邏輯和實現,讓我們可以更加信任託管,聚焦業務邏輯,同時在編寫程式碼時,儘量用JVM友好的方式進行,從而達到更好看、更高效的目的。
RPC為了效能做了哪些努力
Provider分組和直連
//以sofa為例(value = "directUrl", order = -20000)(consumerSide = true)public class DirectUrlRouter extends Router { //...}
非同步呼叫

本地優先、遠端優先
List<ProviderInfo> localProviderInfo = new ArrayList<ProviderInfo>();// 解析IP,看是否和本地一致for (ProviderInfo providerInfo : providerInfos) { if (localhost.equals(providerInfo.getHost())) { localProviderInfo.add(providerInfo); }}// 命中本機的服務端if (CommonUtils.isNotEmpty(localProviderInfo)) { return super.doSelect(invocation, localProviderInfo);} else { // 沒有命中本機上的服務端 return super.doSelect(invocation, providerInfos);}延遲暴露
//服務註冊之前,先延遲public void export() { // 根據配置延遲載入 if (providerConfig.getDelay() > 0) { Thread thread = factory.newThread(new Runnable() { public void run() { try { Thread.sleep(providerConfig.getDelay()); } catch (Throwable ignore) { } //真正的服務註冊邏輯 doExport(); } }); thread.start(); } else { doExport(); }}粘滯連線
答:大部分情況是有利的,不過有些特殊的場景,更希望多次請求連線到同一臺伺服器。protected ProviderInfo select(...)throws SofaRpcException { // 判斷isSticky 粘滯連線配置 if (consumerConfig.isSticky()) { //如果最後一次使用的provider不為空,則使用 if (lastProviderInfo != null) { ProviderInfo providerInfo = lastProviderInfo; //獲取對應連線 ClientTransport lastTransport = connectionHolder.getAvailableClientTransport(providerInfo); if (lastTransport != null && lastTransport.isAvailable()) { checkAlias(providerInfo, message); return providerInfo; } } } ...}預熱轉發

//累加總權重totalWeight,程式碼忽略。。。 //在總權重內隨機得到一個值 int offset = random.nextInt(totalWeight); //確定隨機值落在哪個片斷上 for (int i = 0; i < size; i++) { offset -= getWeight(providerInfos.get(i)); if (offset < 0) { providerInfo = providerInfos.get(i); break; }}core_proxy_url=weightStarting:0.2,during:60,weightStarted:0.2,address:x.x.x.x,uniqueId:core_unique
什麼是JIT優化
即時編譯器
JIT優化觸發條件
週期取樣,檢測各執行緒棧頂方法,經常出現的方法即為熱點方法。好處是簡單高效,缺點是不精確,容易受執行緒運行狀態的影響。
(包括方法呼叫計數器和回邊計數器)每個方法建立計數器,用來統計呼叫次數。如果該方法執行次數超過閾值,則該方法被認定為熱點方法。好處是足夠精確。缺點是空間損耗大,且實現較難。
JIT指導程式碼優化
方法內聯

//新增JVM啟動參數,用於列印程式碼執行過程中的編譯詳情//-XX:+PrintCompilationString num1 = "12345";String num2 = "23456";//迴圈15000次,因為1.8分層編譯下,各層閾值不一樣,我們取最大閾值for (int i=0;i<15001;i++) { rejectionLB1.stringAdd(num1, num2); //rejectionLB1.stringAdd2(num1, num2); }

其他優化

總結



相關文章
作者 | Coder的技術之路來源 | Coder的技術之路為了更好的體驗和更優的效能,其實RPC悄悄的做了很多工作,本篇就帶大家來看下RPC的一些高階特性和其背後的原因。(還是以開源的du
2021-08-04 03:12:50

數字孿生技術如今在工業環境中很受歡迎,因此瞭解數字孿生概念是如何定義以及如何部署至關重要。物聯網裝置和數字孿生的概念物聯網裝置是一種通過網際網路將資料從一個地方傳
2021-08-04 03:12:39

在2021年,花4000元以上的價格,買一臺4G手機,真的值得嗎?關於這個問題,我相信大多數人給出的答案,是拒絕的。有一個很經典的理論:銷售的本質是滿足消費者的預期。5G雖然感知不強,但是
2021-08-04 03:12:31

#iPhone13新功能曝光#什麼是Wi-Fi 6E?Wi-Fi 聯盟可能很少有人聽說過,它是 Wi-Fi 難題的關鍵部分,由連線空間中的「誰是誰」組成。 Wi-Fi 是一項存在於消費者購買的大多數技術產
2021-08-04 03:12:25

一晃眼的功夫,紛紛擾擾的ChinaJoy 2021就已經圓滿落幕了,回頭望去彷彿這幾天確實經歷了許多許多,形勢的突然驟變對於整個活動的影響是有的,但是得益於廠商、活動舉辦商以及眾多
2021-08-04 03:12:08

最近有人問i7-4790K有必要換成i7-11700K嗎?那麼今天就簡單說說這個問題吧,按照慣例先上關鍵參數。i7-4790K,採用22nm工藝,4核心8執行緒,基礎頻率4GHz,睿頻4.4GHz,TDP 88W,最大支援32
2021-08-04 03:11:58