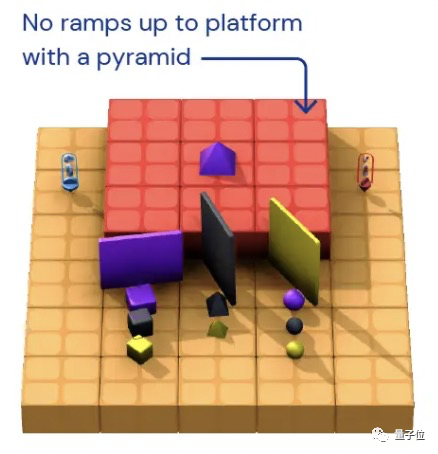
有這樣一批智慧體,在完全沒有見過的遊戲任務裡,也學會了遊刃有餘地解決目標。譬如面對下面這樣一個高地,它們要取到上面的紫色金字塔。圖片沒有跳躍功能的它們,看似開始「焦躁」
2021-08-05 15:07:20
有這樣一批智慧體,在完全沒有見過的遊戲任務裡,也學會了遊刃有餘地解決目標。
譬如面對下面這樣一個高地,它們要取到上面的紫色金字塔。
 圖片
圖片沒有跳躍功能的它們,看似開始「焦躁」地亂扔起東西來,實則其中一塊板子正好被「扔」成了樓梯,這不就巧了,目標完成!
 圖片
圖片你可能會說這只是「瞎貓撞死耗子」罷了,但多次實驗發現,該智慧體可以復現該方法的!
 圖片
圖片而且它還會不止一種方法,「我不上去,你下來」——直接藉助板子把目標扒拉下來了!
 圖片
圖片這也行?
 圖片
圖片而這些成精了的智慧體來自DeepMind。
現在,為了讓AI更加多才多藝、舉一反三,他們專門給智慧體打造了一個包含了數十億遊戲任務的「元宇宙」XLand:讓智慧體在不斷擴展、升級的開放世界中通過上億次的訓練練就了不俗的泛化能力。
 圖片
圖片最終效果就像前面看到的,無需在新遊戲中從頭訓練,它們就能自主解決任務!
DeepMind也因此發表了一篇論文,就叫做:《從開放學習走出來的通用智慧體》。
 圖片
圖片如何做到的呢?
「元宇宙」XLand
最功不可沒之一的就是這個龐大的「元宇宙」模擬空間。
這是一個「遊戲星系」,裡面有無數個「遊戲星球」,每個星球上的遊戲按競爭性、平衡性、可選項、探索難度四個維度進行區分。
 圖片
圖片比如圖左上介紹的「搶方塊」遊戲:藍色智慧體需要把黃色的立方體放到白色區域,紅色智慧體需要把同一個立方體放在藍色區域。
 圖片
圖片啊想想就頭大,所以這個遊戲的競爭性值都拉滿了,而由於雙方的條件/目標都一樣,所以平衡性值也很高,因為需要定位目標區域,所以探索難度並不小。
再比如圖右上的「將球體和立方體配對」:藍色/紅色智慧體要將幾何體按顏色歸類到一起,完成任意一組配對就行。這個遊戲的可選性值就拉滿了,但競爭性就沒那麼強。
 圖片
圖片ps.藍色遊戲代表是完全競爭性的,粉色為完全合作性的。
不管是哪種遊戲任務,這批智慧體都從最簡單的開始(比如僅「靠近紫色立方體」這種),一步步解鎖複雜度升級的遊戲(比如和另一個智慧體「捉迷藏」),其中每一項遊戲都有獎勵,智慧體們的目標就是將拿到的獎勵最大化。
而智慧體「玩家」們是通過閱讀收到的目標的文字描述、觀察RGB影象來感知周圍環境來完成任務。
生成的新任務要基於舊任務,且難度要剛剛好
除了上面這個開放式的學習環境,訓練方法也很重要。
研究人員使用的神經網路訓練架構提供了一種針對智慧體內部迴圈狀態的注意力機制——通過估計所玩遊戲的子目標,來持續引導智慧體的注意力。
 圖片
圖片這種策略讓智慧體學習到更具普遍能力的策略。
還有一個問題:如此廣闊的遊戲環境,什麼樣的遊戲任務分佈能產出最善於泛化的智慧體呢?
研究人員通過持續調整每個智慧體的遊戲分佈發現,每個新任務都要基於通關的舊任務生成,不能太難,也不能太容易。
這個也基本符合一般認知。
它們先經歷了四次迭代:
每個任務由多個智慧體參與競爭,在舊任務上適應得好的智慧體,會帶著權重、瞬時任務分佈、超參數等參與到新一輪任務中繼續學習。此時也會加入新的智慧體讓競爭「活」起來。
 圖片
圖片智慧體表現出明顯的零樣本學習能力
最後生成的第五代智慧體,在XLand 4000多個「星球」裡玩了大約70萬個遊戲,每一個智慧體都經歷了2000億次訓練,完成了340萬個獨特任務。
到了這個時候,這些智慧體已經能夠順利完成每一項評估任務(除了少數即使是人類也不可能完成的)。
整個實驗也最終表明,通過開發像XLand這樣的環境和這樣開放式地訓練方法,一些基於RL的智慧體已表現出明顯的零樣本學習能力(0-shot)。
比如使用工具、打攔(ridge-fencing)、「捉迷藏」、找立方體、數數、合作或競爭等。
 圖片
圖片研究人員也觀察到智慧體們面對新任務時不知道「什麼是最好的解決辦法」,但它們會不斷地試驗直到達到目標。
這個過程中出現的有趣的」緊急啟發式行為」,除了開頭提到的搭梯子,還有這個臨時更換更簡易目標的例子——
在一個遊戲中該智慧體需要從3個目標中任選一個完成:
1、將黑色金字塔放到黃色球體旁邊;2、將紫色球體放到黃色金字塔旁邊;3、將黑色金字塔放到橙色區域。
它一開始找到了一個黑色金字塔,想去完成目標3,但在搬運過程中看到了黃色球體,於是它就在1秒內改變了主意,選擇直接將金字塔放在黃色球體旁邊完成目標1。
(整個過程一共耗時6秒)
 圖片
圖片最後,看完了DeepMind的研究,再拋給大家一個問題:我們離真正的通用人工智慧還有多遠?
 圖片
圖片(ps.你發現了嗎,文章最開頭高臺取金字塔任務中的小紅智障體就不行,一直打轉,面對小藍搭好的梯子甚至直接毀掉
 圖片
圖片)
相關文章
有這樣一批智慧體,在完全沒有見過的遊戲任務裡,也學會了遊刃有餘地解決目標。譬如面對下面這樣一個高地,它們要取到上面的紫色金字塔。圖片沒有跳躍功能的它們,看似開始「焦躁」
2021-08-05 15:07:20

特粉之家專注於分享特斯拉相關資訊,敬請關注!8月4日,據特斯拉中國官網顯示,特斯拉Model S(參數丨圖片)長續航版價格上調了3萬元,調整後售價為859990元,此前售價為829990元。同時,Mode
2021-08-05 15:06:48

最新的全國口腔健康調查顯示,35歲以上成年組牙石的檢出率高達90%以上,牙齦出血檢出率在82%以上。整個被調查人群中,牙周健康者不足一成。早晚兩次刷牙能夠幫助人們完成牙齒表面
2021-08-05 15:06:07

努比亞Z30Pro黑金傳奇限量版是在努比亞Z30Pro基礎上專門推出的一個限量版本,後蓋採用經典的黑金撞色設計,並在機身中框和鏡頭採用奢華的金色線條設計,配合手機上下邊框採用「環
2021-08-05 14:47:42

對於大部分的人來說,都會面臨著對家居環境進行清潔打掃的問題。目前大部分人使用的還是傳統的掃帚或者老式的吸塵器。這些工具雖然也可以進行清掃,但是存在一系列的缺點。例如
2021-08-05 14:46:54

辦公電腦能做到多小?這個問題在我選購辦公電腦的時候就經常會想到。即便是Mini-ITX小主機,也跟我想象中「幾乎不佔用桌面空間」的幻想存在差距。直到筆者親眼見到像華碩PN51這
2021-08-05 14:46:01