8月14日至18日,國際資料探勘與知識發現大會 KDD 2021在線上正式舉行。此前本屆KDD入選論文已經揭曉,百度被收錄的多篇論文,其突出的特點是學術研究與技術應用緊密結合,再次展現
2021-08-17 03:03:46
8月14日至18日,國際資料探勘與知識發現大會 KDD 2021在線上正式舉行。此前本屆KDD入選論文已經揭曉,百度被收錄的多篇論文,其突出的特點是學術研究與技術應用緊密結合,再次展現百度在AI領域的技術實力。
ACM SIGKDD(簡稱KDD)國際資料探勘與知識發現大會至今已連續舉辦了26屆,是世界資料探勘最高級別的學術會議之一,有資料探勘領域「世界盃」之稱,每年吸引了大量資料探勘、機器學習、大資料和人工智慧等領域的研究學者、從業人員參與。
百度在AI技術方向多年創新積累,資料探勘和知識發現也是重點關注和持續投入的相關領域,並擁有多項技術成果和應用落地案例。在多年為KDD輸送優質論文的基礎上,百度今年的被收錄論文再次體現了技術與應用緊密融合的趨勢。
生物計算與醫療:生命健康裡的AI新可能
在與人類息息相關的生命健康領域,百度也取得了長足進步:在AI+醫療多個方向上探索,構建醫療AI中臺、面向醫療場景提供各種AI解決方案;更進一步尋覓生物計算的密碼,推出生物計算平臺螺旋槳PaddleHelix。此次KDD 2021中,百度發表了論文聚焦生命健康領域,提出了相關的新型圖神經網路模型和醫學實體關係循證框架。
1. 三維結構感知的互動式圖神經網路 —— 用於蛋白質-配體親和力預測的新型圖神經網路模型
Structure-aware Interactive Graph Neural Networks for the Prediction of Protein-Ligand Binding Affinity
藥物設計的一個關鍵步驟是準確的預測蛋白質-配體的親和力(protein-ligand binding affinity)。最近的研究進展已經證明,使用圖神經網路 (GNNs) 來學習蛋白質-配體複合物(protein-ligand complexes)的表示,比傳統方法可以更準確地預測親和力。然而,現有的模型通常將蛋白質-配體複合物視為拓撲圖,並沒有充分利用分子的三維結構資訊。同時GNN模型也忽略了原子之間基本的遠距離相互作用。為此,我們提出了一種新型的三維結構感知的互動式圖神經網路 (SIGN),它由兩個部分組成:基於極座標的圖注意力層 (PGAL) 和成對互動式池化層 (PiPool)。具體來說,PGAL層首先迭代執行節點-邊聚合過程以更新節點和邊的表徵,在這個過程可以同時保留原子之間的距離和角度資訊。然後,SIGN可以通過PiPool層來對互動邊進行池化操作,隨後通過重建互動矩陣的學習任務來反映蛋白質-配體的全局互動資訊。在兩個基準資料集上的實驗結果驗證了SIGN預測效果的優越性。

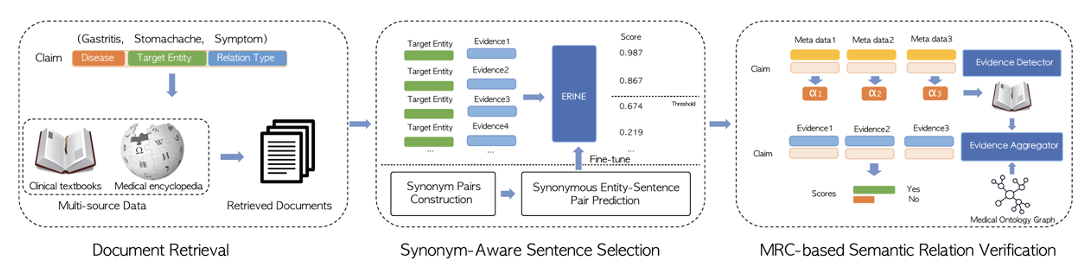
2. 基於大規模機器閱讀理解的醫學實體關係循證
Medical Entity Relation Verification with Large-scale Machine Reading Comprehension
醫學實體關係驗證是構建企業級醫學知識圖譜的關鍵步驟。現有的資訊抽取的方法專注於實體關係的挖掘,但並不能對挖掘的關係提供有效的循證支撐,這在真實醫學應用場景下是不可接受的。因此,設計一種以循證為基礎的醫學實體關係驗證框架是十分必要的。
針對上述場景,我們提出了一種基於大規模機器閱讀理解技術的醫學實體關係循證框架。該框架中我們設計了多種創新性的方法和模組來提高醫學實體關係循證的效率和準確率。比如,為了解決醫學實體的多樣性和變體問題,我們提出了一種近義詞感知(synonym-aware)的召回模型;為了更好的利用醫學的領域知識,我們創造性的設計了基於關係感知(relation-aware)的證據探測模組和基於醫學本體增強(medical ontology-enhanced)的聚合模組,來共同提高整體循證模型的效果。此外,為了解決證據標籤缺乏的問題,我們提出了一種新穎的基於互動協調訓練的新方法(interactive-collaborative training)來提升標註效率,提升證據準確率。通過實驗驗證,我們提出的循證框架超越多個現有的基於事實驗證的最好基線方法(state-of-the-art baselines)。該框架已經應用在了百度臨床輔助系統(CDSS)上,多方位支撐CDSS產品矩陣的可解釋循證,幫助了上萬名醫生。

POI檢索、推薦等為使用者提供更好、更便捷的智慧化位置服務
作為國內智慧化位置服務的代表產品之一,百度地圖日均位置服務請求已突破了1200億次。
怎樣讓使用者在使用百度地圖時能夠獲得更好、更快、更方便的服務?KDD 2021中選論文中,百度延續以往在百度地圖方面的技術研究、進行了升級和創新,覆蓋POI即時檢索、多語言POI檢索、POI推薦和基於自監督元學習的路線耗時預估辦法等。
3. MST-PAC:基於元學習的時空個性化POI即時檢索
Meta-Learned Spatial-Temporal POI Auto-Completion for the Search Engine at Baidu Maps
POI即時檢索(POI Auto-Completion)是百度地圖POI搜尋引擎的特色功能之一。POI即時檢索旨在幫助使用者以最少的輸入(理想情況下只需要使用者輸入一個字元),在搜尋結果列表頁的首位即時給出使用者想找的POI,因此能夠大幅降低輸入成本並顯著提升搜尋效率。POI即時檢索效果不僅與使用者輸入的字元以及輸入習慣有關,也與使用者發起檢索的時間與空間相關。統計資料顯示17.9%的地圖使用者在不同的時間或地點使用過相同的字首尋找過不同的POI。考慮到時空資料分佈的不均衡性,我們提出了一種基於元學習的時空個性化POI即時檢索方法,並使用高效MapReduce演算法對其進行訓練(縮寫為MST-PAC)。MST-PAC能夠顯著克服時空資料分佈不均的問題,並能以較少的訓練樣本快速適應冷啟動的時空場景。MST-PAC已在百度地圖成功部署,每天處理數十億檢索請求,這表明MST-PAC是一種具有實用價值且能夠大規模落地的POI即時檢索工業解決方案。

4. 基於異構圖與注意力匹配網路的多語言POI檢索
HGAMN: Heterogeneous Graph Attention Matching Network for Multilingual POI Retrieval at Baidu Maps
多語言POI檢索旨在幫助使用者使用自己熟悉的語言查詢到由其他語言所描述的POI。該功能在出境旅遊時尤為重要,因為本地POI往往缺乏多語言翻譯,要用完全陌生的語言進行查詢對大部分使用者來說不太現實。資料稀疏是多語言檢索任務面臨的挑戰之一。為此,我們提出了一種基於異構圖的注意力匹配網路(HGAMN)。首先,在異構圖的幫助下,我們能夠有效建立起低頻POI與高頻POI之間,以及POI與其不同語言的查詢表達之間的關聯。其次,我們使用基於注意力的網路對該圖的節點表示進行學習後,能夠顯著緩解資料稀疏問題。HGAMN已在百度地圖成功部署,每天響應數億搜尋請求,這表明HGAMN是一種實用且魯棒的多語言POI檢索工業解決方案。

5. SSML: 基於自監督元學習的在途路線耗時預估方法
SSML: Self-Supervised Meta-Learner for En Route Travel Time Estimation at Baidu Maps
路線耗時預估旨在根據路線和出發時間預測使用者的到達時間,是地圖產品必不可少的基礎功能之一。在途路線耗時預估是路線耗時預估在使用者駕駛過程中的細分場景任務,旨在估算出從使用者當前位置到目的地的剩餘時間。然而,現有方法未考慮從起點到當前位置的使用者駕駛行為,從而很難快速適應使用者的駕駛習慣,並據此及時調整剩餘的預估耗時。為此,本文提出利用已行駛路線所觀察到的少量使用者駕駛行為,來提升在途路線耗時預估的準確率。我們將該任務建模為一個小樣本學習問題,把已行駛路線中觀察到的使用者行為作為訓練樣本,同時把剩餘路線中未發生的行為作為測試樣本。我們提出了一種基於自監督元學習的在途路線耗時預估方法(SSML),並使用自監督學習進行資料增強,從而得以快速適應使用者的駕駛行為、提升模型的預測效果。基於百度地圖大規模真實資料集的實驗表明,SSML是一種具有實用價值與穩健性的在途路線耗時預估工業解決方案。

6. CHAML:基於課程式元學習框架的POI推薦技術
Curriculum Meta-Learning for Next POI Recommendation
POI推薦,作為廣受使用者歡迎的POI發現方式,是百度地圖的特色功能之一。該功能旨在結合當前的時空場景和使用者使用習慣,快速發現其潛在感興趣的POI。但是,由於『使用者-POI』互動的天然長尾效應,現有技術很難為資料稀疏的冷啟動城市提供令人滿意的POI推薦。本文提出了一種將隱藏在豐富資料中的知識從熱門城市遷移到冷啟動城市的構想。為了達成這一構想,我們設計了一種新的課程式元學習(CHAML)框架。CHAML框架能夠分別從城市和使用者兩個層面,考慮樣本的訓練難度,並以此來增強元學習訓練過程。同時,我們設計了一種由易到難的課程式學習方案,用於樣本抽樣,以幫助元學習模型收斂到更好的狀態。目前,CHAML已經用於百度地圖的POI推薦業務,並且取得顯著的應用效果。

新技術助力百度搜索引擎效能與效果提升
如何進一步優化提升百度搜索引擎的體驗和效率,是百度技術人員一直關注的問題。此次KDD 2021百度中選論文中,有數篇圍繞百度搜索引擎效能效果提升探討了最新技術研究成果,包含使用百度先進的中文預訓練語言模型文心(ERNIE),快速近鄰檢索(ANN)和快速最大內積檢索(MIPS),高效智慧線上推理系統JiZhi(極智)等。
7. 基於預訓練語言模型的百度搜索排序
Pre-trained Language Model based Ranking in Baidu Search
排序作為搜尋的核心,在滿足使用者的資訊需求方面起著至關重要的作用。近來,基於預訓練語言模型 (PLM) 的微調方法取得了當前最好的效果。然而,在大規模搜尋引擎中應用基於PLM的排序模型卻並不容易:1. PLM的計算成本過高,尤其是對於排序中的長文字,限制了他們在低延時系統中的部署;2. 現有的預訓練目標與相關性無關,直接應用相關性無關的PLM模型,是限制基於PLM的排序模型的另一個主要障礙;3. 現有的排序模型需要和其他排序模型共同應用,因此模型與其他模型的相容性對於一個排序系統來說也至關重要。
在本工作中,我們提出了一系列如何成功部署最先進的中文預訓練語言模型(ERNIE)的技術。首先,我們闡明瞭如何高效地抽取文件的摘要,並提出了能強大的Pyramid-ERNIE 架構將查詢、標題和摘要三者建模。然後,我們提出了一個正規化來精細地利用大規模的有噪聲和偏見的點選後行為資料進行面向相關性的預訓練。其次,我們還提出了一種為線上排名系統量身定製的人工錨定微調策略,旨在保證基於PLM的排序模型和其他模組的相容性。最後,大量的離線和線上實驗結果表明,所提出的方法可以顯著提高了搜尋引擎的效能。

8. 預訓練語言模型在百度大規模網頁召回中的應用
Pre-trained Language Model for Web-scale Retrieval in Baidu Search
召回是網頁搜尋中的重要階段,其功能在於從海量網頁庫中找到一個相對較小的相關候選集。其中,基於語義相關的召回有助於展現更多高質量的搜尋結果給使用者。但是,搭建和部署一個高效的語義召回模型,在搜尋引擎業務中一直面臨著諸多挑戰。本文介紹了目前百度搜索中所使用的基於預訓練語言模型的召回系統。此係統採用了百度自研的中文預訓練語言ERNIE,通過應用基於多層Transformer的模型結構,以及多階段的訓練流程,賦予了召回系統強大的語義匹配能力。同時,本文還介紹了基於預訓練的召回模型在整個召回系統中的工作流程。通過嚴謹的離線和線上實驗驗證,基於預訓練語言模型的召回系統已全量部署在百度搜索業務中,提升了百度搜索的整體效果。

9. 基於模調節近鄰圖的最大內積檢索
Norm Adjusted Proximity Graph for Fast Inner Product Retrieval
快速近鄰檢索(ANN)和快速最大內積檢索(MIPS)是工業界超大規模排序系統的核心,在搜尋引擎公司的各項主要業務中發揮了巨大作用。有關ANN和MIPS的各項前沿研究在百度已經有了很長的歷史。從2019年開始,通過學術論文百度逐步而系統地對外公開了自主開發的各項ANN和MIPS核心技術。這篇KDD 2021論文就是其中之一。
最大內積檢索(MIPS)旨在快速查詢與檢索向量(Query)內積最大的候選向量,原本是學術界和工業界的一個重大難題。最大內積檢索之所以具有挑戰是因為內積不符合三角關係,即內積不是度量標準(Metric Measure)。傳統的快速向量檢索技術多為Metric Measure所設計,如歐式距離和餘弦距離。這些傳統方法並不適用於最大內積檢索。比如針對Metric Measure效果非常好的圖索引方法就不能直接應用到最大內積檢索中。在本文中我們提出模調節圖索引結構,將針對Metric Measure的圖索引結構擴展到最大內積檢索任務中。大量實驗表明,該方法相比於之前有代表性的內積檢索方法,有很大的效能優勢。我們提出的方法NAPG相比於之前有代表性的MIPS方法ip-NSW,Greedy-MIPS和Rang-LSH,在檢索效能上有巨大優勢。在同等召回率水平上,該方法可以處理的查詢數遠多於其他方法。

10. JIZHI:百度面向網路應用的實時高效模型預估系統
JIZHI: A Fast and Cost-Effective Model-As-A-Service System for Web-Scale Online Inference at Baidu
對於來自數億級使用者的巨量預估請求,如何能夠以超低成本支撐起超大規模離散稀疏深度模型進行高效的實時線上推理仍然具有極大挑戰性。在本文中,我們構建了一套高效智慧線上推理系統JiZhi(極智),將每個請求的推理過程轉換為一個階段式的事件驅動處理流(SEDP),創新性的以全局最優視角自適應精細化調整各個階段最合理的架構演算法和參數,動態排程模型預估算力的分配,更加智慧通用的適應各種預估應用場景。通過多層次自適應快取機制,大幅減少了由超大規模稀疏模型參數引起的計算成本和資料訪問延遲,進一步加速線上推理過程。此外,JiZhi還實現了智慧資源管理機制,從系統運行期歷史中學習最佳的資源分配計劃,調整負載控制策略,最大限度的提高JIZHI的系統吞吐。JIZHI已在百度20多個業務場景落地,從端到端的實現成本、服務延遲、系統吞吐量、資源消耗等角度展現出了JIZHI系統顯著的優勢,在保障模型效果的前提下節省了大量的實現、硬體和基礎設施的應用成本。

AI+房地產評估:從地理分佈、人口流動性分佈、居民人口學分佈等多個角度構建豐富的特徵集,以對房地產價值進行全面綜合的剖析。
11. MugRep: 一種面向房地產評估的多工層次圖表示學習框架
MugRep: A Multi-Task Hierarchical Graph Representation Learning Framework for Real Estate Appraisal
房地產評估是指對房地產的市場價值進行公正評價的過程,其對房地產市場的各種參與者(如房地產經紀人、估價師、貸款人和買家)的決策過程起著至關重要的作用。然而,要做到準確的對房地產進行評估並不容易,將主要面臨三個方面的挑戰:(1) 房地產價值複雜的影響因素;(2) 房地產交易間的非同步時空依賴;(3) 城市居民社群間的多元相關性。針對以上幾大挑戰,本文提出了一種多工層次圖表示學習框架 (MugRep),用來準確的評估房地產。具體來說,通過獲取和整合多源城市資料,本文首先從地理分佈、人口流動性分佈、居民人口學分佈等多個角度構建豐富的特徵集,以對房地產價值進行全面綜合的剖析。然後,我們提出了一種演化的房地產交易事件圖卷積模組,以融合房地產交易之間的非同步時空依賴。此外,為了進一步從居民社群的視角提取有價值的知識,我們設計了一種分層異構的社群圖卷積模組,以捕獲居民社群之間的多元相關性。最後,我們引入以城區作為劃分的多工學習模組,以生成不同分佈的房地產評估意見。我們在兩個真實資料集上進行了大量的實驗,結果證明了MugRep及其元件和特性的有效性。

AI+人才管理:聚焦新領域的創新突破
一直以來,百度在「AI+人才管理」方面也實現了深厚的技術研究積累,今年年初就有相關研究成果登上國際頂級刊物Nature子刊Nature Communications。在KDD 2021的被錄取論文中,百度相關研究團隊展現了在工作流動行為預測、人才需求預測等方面的最新研究成果。
12. 基於異構圖注意力表徵的工作流動行為預測
Attentive Heterogeneous Graph Embedding for Job Mobility Prediction
在當今人才經濟時代,跳槽頻繁現象已經成為新常態。因此,對工作流動預測的研究應運而生,它能使組織和個人在多個方面獲益。本文聚焦在工作流動預測任務,現有研究主要集中在對個體層面的職業軌跡建模,而很大程度上忽略在宏觀層面上職業流動的影響(例如,在公司與公司或崗位與崗位之間的人才流動)。實際上,這種宏觀層面上的職業流動資訊能夠反映出人才市場的趨勢,對個人的跳槽決定會產生一定影響。為此,本文提出一種建模宏觀層面職業流動行為影響來輔助預測個體層面的工作流動框架(Ahead)。首先,從觀測到的職業軌跡鏈中構造異質企業-崗位網路來保留宏觀層面的職業流動資訊。其次,本文構建了AHGN模組從異質圖中獲取崗位和企業豐富的語義表徵。其中提出了兩種聚合器,分別用來聚合內部和外部鄰居的資訊,以及一種新穎的類型注意機制被用來融合兩種聚合器的資訊以更新節點表示。最後在公開網際網路資料集上的實驗結果從多個角度證明了本文方法的有效性。

13. 基於注意力序列模型的人才需求預測
Talent Demand Forecasting with Attentive Neural Sequential Model
人才需求預測(Talent Demand Forecasting)技術是指根據公開網際網路資料對未來公司的人才招聘需求進行預測的技術。在當今瞬息萬變的商業環境中,根據公開資料及時預測各個企業在招聘市場中的人才需求趨勢,不僅可以幫助企業指定合適的人才斬落,保持自身人才競爭力,還可以幫助政府從宏觀角度對人力市場的供需關係進行分析。雖然已有很多在招聘市場分析方面的工作,但由於細粒度人才需求時間序列的稀疏性和招聘市場複雜的時序模式,仍然沒有有效的方法可以預測細粒度的人才需求動態。為此,在本文中,我們提出了一種資料驅動的注意力序列模型,即人才需求注意力網路(TDAN),用於預測公開市場中的細粒度人才需求。我們首提取多個粒度級別上人才需求的時間序列,並使用矩陣分解技術提取公司和職位的內在屬性。然後,我們設計了一種混合注意力模組來捕捉公司的趨勢和行業的趨勢,用以增強細粒度人才需求的資訊。接著設計了一個相關性注意力時序模組,用於對隨公司和職位變化的複雜的時間相關性進行建模。最後,在大規模公開網際網路資料集上進行了大量實驗,結果驗證了所提方法在細粒度人才需求預測方面的有效性,展示了其對招聘趨勢建模的可解釋性。

— 完 —
相關文章
8月14日至18日,國際資料探勘與知識發現大會 KDD 2021在線上正式舉行。此前本屆KDD入選論文已經揭曉,百度被收錄的多篇論文,其突出的特點是學術研究與技術應用緊密結合,再次展現
2021-08-17 03:03:46

在之前文章中已經寫過了,自學程式設計有兩個必要條件=邏輯思維+程式設計英語。有關沒有學歷的普通人是否可以通過自學程式設計月入過萬,這邊有幾點建議: 如果學歷不到專科,那麼
2021-08-17 03:03:27

我們在做短視訊的路上總是有很多問題,例如怎麼突破播放量,短視訊還有沒有機會等等。所以今天就收集了各大網站上以及大家平時比較多的問題給大家做一個合集。01 實操問題1. 怎
2021-08-17 03:03:21
自從 iOS 系統自帶了電池健康度檢視之後,有不少使用者都會有意無意的觀察一下自己的電池健康度,每當看到健康度掉了 1% 就會非常難受。而根據蘋果的說法,當裝置的健康度掉下 80
2021-08-17 03:03:17

華為手機近期釋出了華為P50系列高階機,售價不便宜,產品配置確實很重磅,只是全系均為4G版本,並沒有5G版本,這讓人有點遺憾了,畢竟華為是最先推出雙模5G手機的品牌,曾經走在行業的前
2021-08-17 03:03:09

電動自行車方便快捷,已經成為很多人常用的交通工具。據中國自行車協會統計,近年來我國電動自行車年銷量超過3000萬輛,社會保有量接近3億輛,千元以上自行車產量持續增長。說
2021-08-17 03:03:02