
2021-05-12 14:32:11
Linux系統之文字格式化工具awk
2020-06-16 17:46:16
一、文字處理工具
grep、sed和awk都是文字處理工具,雖然都是文字處理工具但卻都有各自的優缺點,一種文字處理命令是不能被另一個完全替換的,否則也不會出現三個文字處理命令了。只不過,相比較而言,sed和awk功能更強大而已,且已獨立成一種語言來介紹。
grep:文字過濾器,如果僅僅是過濾文字,可使用grep,其效率要比其他的高很多;
sed:Stream EDitor,流編輯器,預設只處理模式空間,不處理原資料,如果你處理的資料是針對行進行處理的,可以使用sed;

awk:報告生成器,格式化以後顯示。如果對處理的資料需要生成報告之類的資訊,或者你處理的資料是按列進行處理的,最好使用awk。
二、awk可以完成的一些功能
-
將文字檔案看做由記錄和欄位組成的文字資料庫
-
使用變數運算元據庫
-
使用算術和字串操作符
-
使用普通的程式設計結構,例如迴圈和條件
-
生幫格式化報告
-
定義函數
-
從指令碼中執行unix命令
-
處理unix命令的結果
-
更加巧妙的處理命令列的引數
-
更容易地處理多個輸入流
三、語法格式
|
1
2
|
# awk [options] 'script' file1 file2, ... # awk [options] 'PATTERN { action }' file1 file2, .. |
1、選項
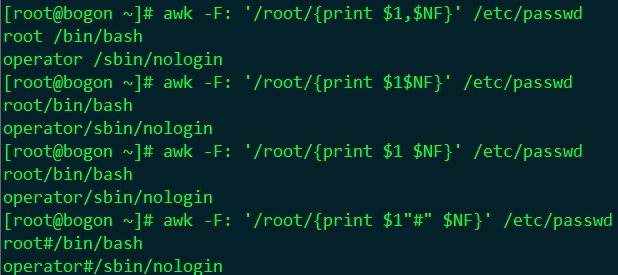
-F fs or --field-separator fs:
指定輸入檔案折分隔符,fs是一個字串或者是一個正規表示式,如-F:
|
1
2
3
4
|
#awk -F: '/root/{print $1,$NF}' /etc/passwd #awk -F: '/root/{print $1$NF}' /etc/passwd #awk -F: '/root/{print $1 $NF}' /etc/passwd #awk -F: '/root/{print $1"#"$NF}' /etc/passwd |
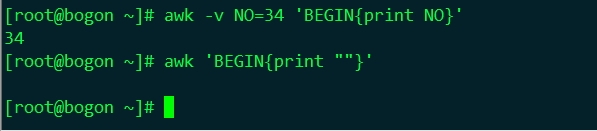
-v 選項定義的變數在指令碼執行之前即存在,可以在指令碼的 BEGIN 流程中被呼叫;

2、awk的輸出:print和printf
⑴、print的使用格式:
print item1, item2, ...
要點:
①、各專案之間使用逗號隔開,而輸出時則以空白字元分隔;
②、輸出的item可以為字串或數值、當前記錄的欄位(如$1)、變數或awk的表示式;數值會先轉換為字串,而後再輸出;
③、print命令後面的item可以省略,此時其功能相當於print $0, 因此,如果想輸出空白行,則需要使用print "";
注意,在AWK中,$表示欄位,使用者變數不需要加$,這是AWK與shell或者Perl不同之處!在shell中,變數定義時不加$,再次參照時則需要用$,而在Perl中,無論定義和參照時都需要加$ (Perl中$表示標量,另有@和%符號表示陣列和Hash變數)。
範例
⑵、printf的使用格式
printf format, item1, item2, ...
format格式的指示符都以%開頭,後跟一個字元,
%c
轉換數位成ASCII,如printf "%c", 67結果為C。

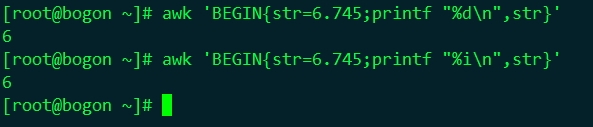
%d, %i
列印十進位制整數,如printf "%dn", 6.745結果為6。
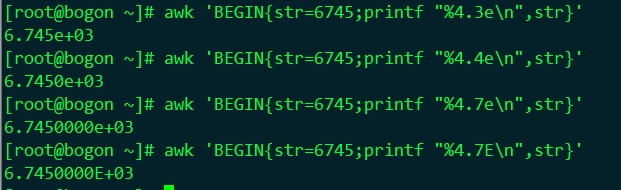
%e, %E
轉換數位為科學(指數)符號,如printf "%4.3en", 6745結果為6.745e+03。
%f
以浮點表示法列印數位,如 printf "%4.3fn", 6745結果為6745.0000000

%s
列印字串,如printf "%10sn", 6745結果為十個空格加6745。

可更改的格式:
N$
位置指示符,可調整字串的輸出位置。printf "%s %s %sn", "I", "lOVE","YOU"輸出為:I LOVE YOU,我們調整一下位置,printf "%3$s %2$s %1$sn", "YOU", "LOVE","I",輸出結果為:I LOVE YOU

修飾符
N: 顯示寬度;
-: 左對齊;
+:右對齊(也可以顯示數值符號正負之用);
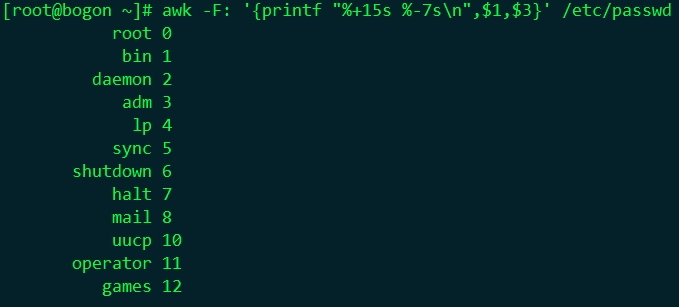
3、模式和操作
⑴、模式可以是以下任意一個:
-
/正規表示式/:使用萬用字元的擴充套件集。
-
關係表示式:可以用下面運算子表中的關係運算子進行操作,可以是字串或數位的比較,如$2>%1選擇第二個欄位比第一個欄位長的行。
-
模式匹配表示式:用運算子~(匹配)和~!(不匹配)。
-
模式,模式:指定一個行的範圍。該語法不能包括BEGIN和END模式。
-
BEGIN:讓使用者指定在第一條輸入記錄被處理之前所發生的動作,通常可在這裡設定全域性變數。
-
END:讓使用者在最後一條輸入記錄被讀取之後發生的動作。
⑵、操作由一人或多個命令、函數、表示式組成,之間由換行符或分號隔開,並位於大括號內。主要有四部份:
-
變數或陣列賦值
-
輸出命令
-
內建函數
-
控制流命令
4、變數
⑴、awk內建變數之記錄變數
| FS: field separator | 讀取檔案本時,所使用欄位分隔符 |
| RS: Record separator | 輸入文字資訊所使用的換行符 |
| OFS: Output Filed Separator | 輸出欄位分隔符(預設值是一個空格) |
| ORS:Output Row Separator | 輸出記錄分隔符(預設值是一個換行符) |
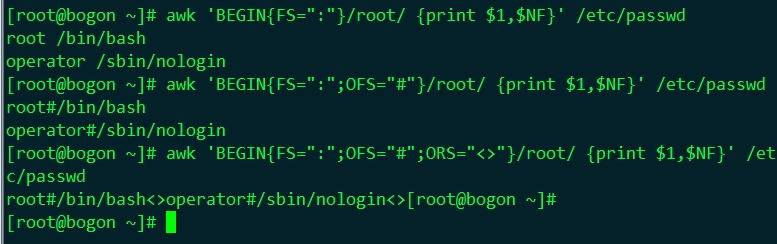
註:
從$1,$2一直到$NF,整行用$0標,如果$0被賦予新值,所有的$1,$2...和NF都將被重新計算。同樣,若$i被改變,$0將用OFS重新計算。
⑵、awk內建變數之資料變數
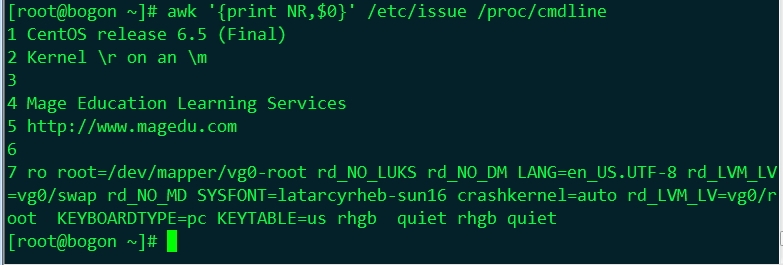
| NR: The number of input records | awk命令所處理的記錄數;如果有多個檔案,這個數目會把處理的多個檔案中行統一計數 |
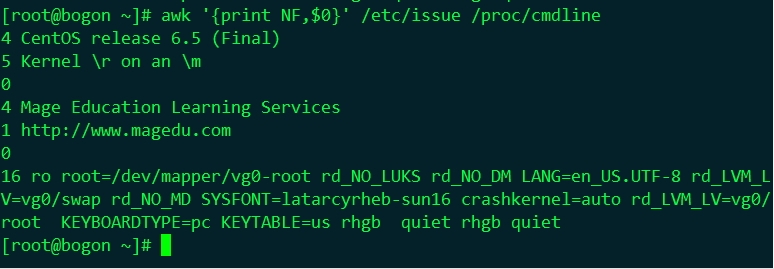
| NF:Number of Field | 當前記錄的field個數 |
| FNR | 當前檔案的相對記錄數 |
| ARGV | 陣列,儲存命令列本身這個字串,如awk '{print $0}' a.txt b.txt這個命令中,ARGV[0]儲存awk,ARGV[1]儲存a.txt |
| ARGC | awk命令的引數的個數 |
| FILENAME | awk命令所處理的檔案的名稱 |
| ENVIRON | 當前shell環境變數及其值的關聯陣列 |
NR用法
NF用法(預設以空格分隔)
FNR用法
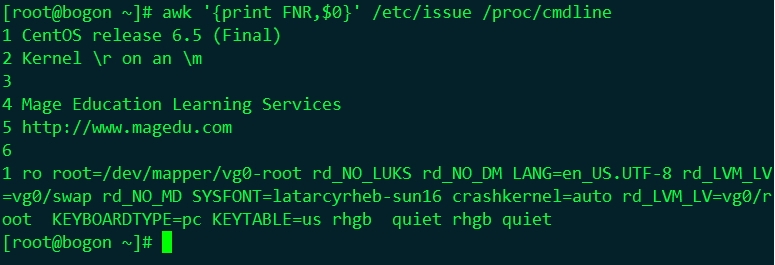
ARGV用法
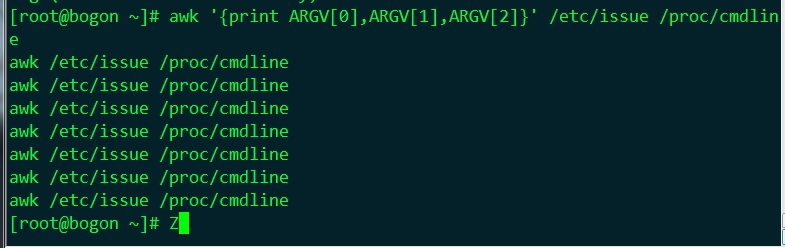
之二
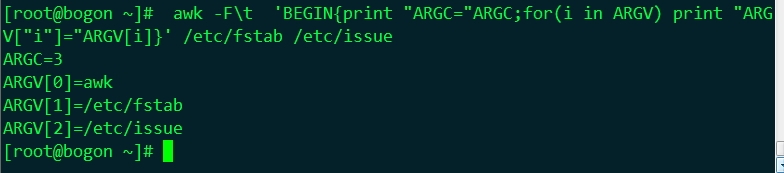
FILENAME用法
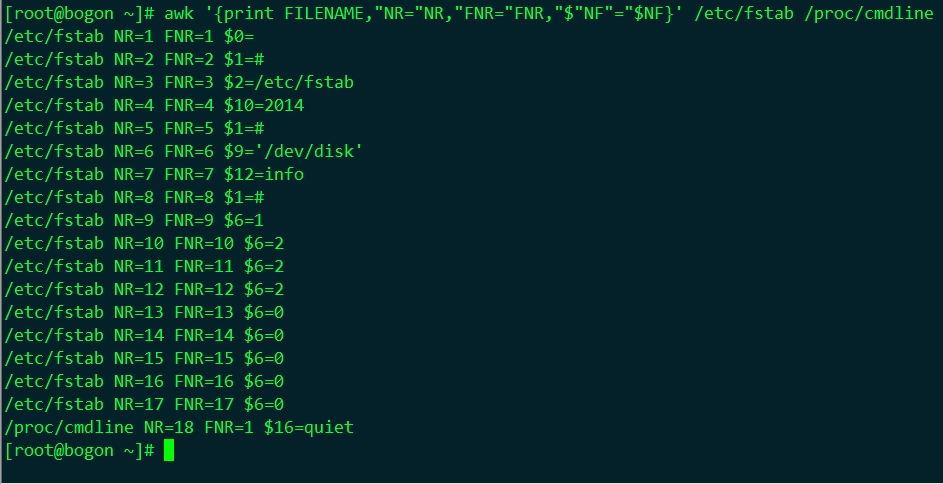
ENVIRON用法

註:
ARGV陣列由ARGV[0]....ARGV[ARGC-1]組成,第一個元素是0而不是1,這與AWK中的般陣列不同
ENVIROND陣列在shell與AWK的互動中非常有用,使用ENVIRON["PARA_NAME"]來獲取環境變數$PARA_NAME的值,其中引號“”不可少!
5、標準輸出與重定向
⑴、輸出重定向
print items > output-file
print items >> output-file
print items | command
⑵、特殊檔案描述符:
/dev/stdin:標準輸入
/dev/sdtout: 標準輸出
/dev/stderr: 錯誤輸出
/dev/fd/N: 某特定檔案描述符,如/dev/stdin就相當於/dev/fd/0;
範例:
|
1
2
|
# awk -F" " '{printf "%-15s %in",$1,$3 > "/dev/stderr" }' /etc/issue # awk -F" " '{printf "%-15s %in",$1,$3 > "/dev/null" }' /etc/issue |
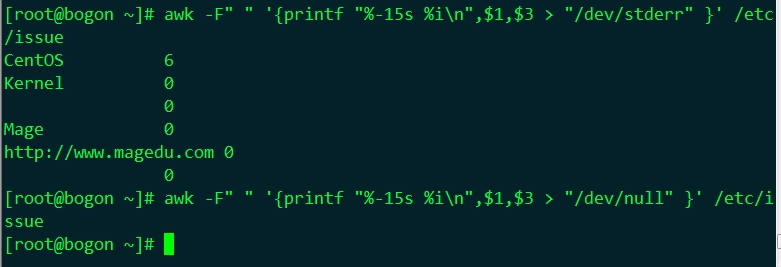
6、awk的操作符:
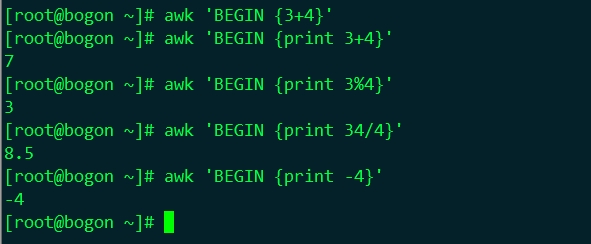
⑴、算術操作符:
-x: 負值
+x: 轉換為數值;
x^y:
x**y: 次方
x*y: 乘法
x/y:除法
x+y:
x-y:
x%y:
範例
⑵、字串操作符:
只有一個,而且不用寫出來,用於實現字串連線;
⑶、 賦值操作符:
=
+=
-=
*=
/=
%=
^=
**=
++
--
需要注意的是,如果某模式為=號,此時使用/=/可能會有語法錯誤,應以/[=]/替代;
⑷、布林值
awk中,任何非0值或非空字串都為真,反之就為假;
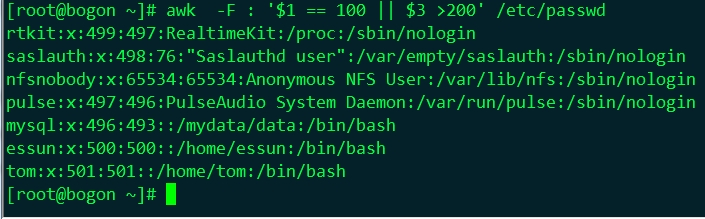
⑸、 比較操作符:
x < y True if x is less than y.
x <= y True if x is less than or equal to y.
x > y True if x is greater than y.
x >= y True if x is greater than or equal to y.
x == y True if x is equal to y.
x != y True if x is not equal to y.
x ~ y True if the string x matches the regexp denoted by y.
x !~ y True if the string x does not match the regexp denoted by y.
subscript in array True if the array array has an element with the subscript subscript.
⑺、表示式間的邏輯關係符:
&&
||
範例:
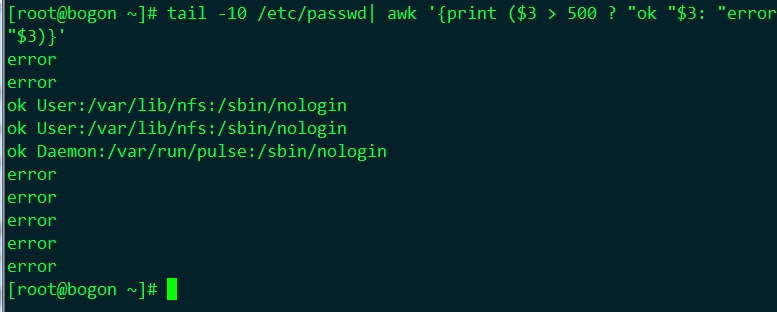
⑻、條件表示式:
selector?if-true-exp:if-false-exp
if selector; then
if-true-exp
else
if-false-exp
fi
範例
⑼、函數呼叫:
function_name(para1,para2)
7、控制語句
⑴、 if-else
語法:
if (condition) {then-body} else {[ else-body ]}
範例:
|
1
2
3
4
|
#awk '{if ($3==0) {print $1, "Adminitrator";} else { print $1,"Common User"}}' /etc/passwd #awk -F: '{if ($1=="root") print $1, "Admin"; else print $1, "Common User"}' /etc/passwd #awk -F: '{if ($1=="root") printf "%-15s: %sn", $1,"Admin"; else printf "%-15s: %sn", $1, "Common User"}' /etc/passwd #awk -F: -v sum=0 '{if ($3>=500) sum++}END{print sum}' /etc/passwd |
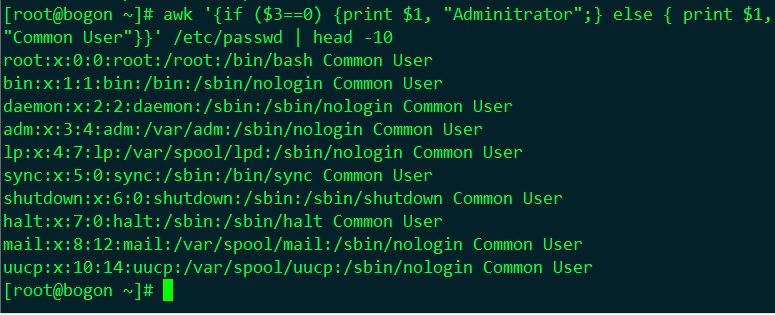
⑵、 while
語法:
while (condition){statement1; statment2; ...}
範例:
|
1
2
3
4
|
#awk -F: '{i=1;while (i<=3) {print $i;i++}}' /etc/passwd #awk -F: '{i=1;while (i<=NF) { if (length($i)>=4) {print $i}; i++ }}' /etc/passwd #awk '{i=1;while (i<=NF) {if ($i>=20000) print $i; i++}}' random.txt #random.txt檔案的內容為一堆亂數。 |
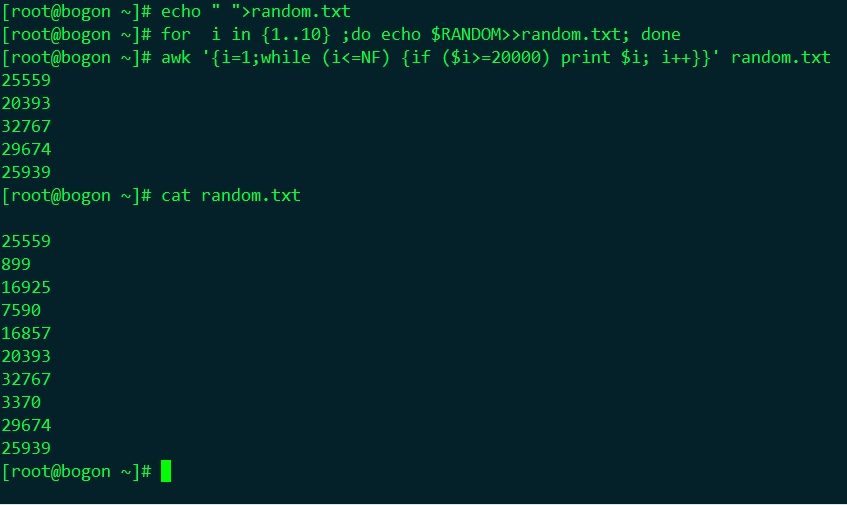
⑶、do-while 至少執行一次迴圈體,不管條件滿足與否
語法:
do {statement1, statement2, ...} while (condition)
範例:
|
1
2
3
4
5
6
7
8
|
#awk 'BEGIN{ sum=0; i=0; do{ sum+=i; i++; }while(i<=100) print sum;}' |

⑷、for
語法:for ( variable assignment; condition; iteration process) { statement1, statement2, ...}
範例:
|
1
|
#awk -F: '{for(i=1;i<=3;i++) { if (length($i)>=8) {print $i}}}' /etc/passwd |
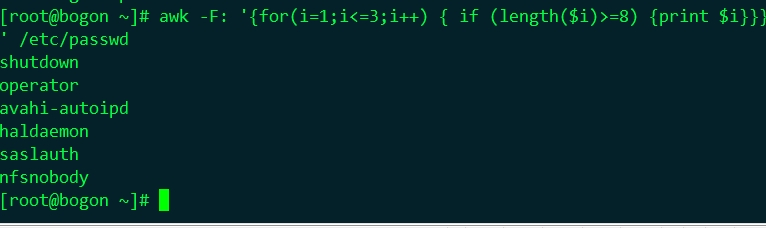
for迴圈還可以用來遍歷陣列元素:
語法:
for (i in array) {statement1, statement2, ...}
範例:
|
1
|
#awk -F: '$NF!~/^$/{BASH[$NF]++}END{for(A in BASH){printf "%-15s:%in",A,BASH[A]}}' /etc/passwd |
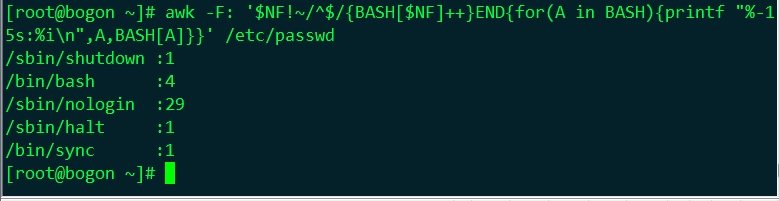
⑸、 case
語法:switch (expression) { case VALUE or /REGEXP/: statement1, statement2,... default: statement1, ...}
⑹、 break 和 continue
常用於迴圈或case語句中
⑺、 next
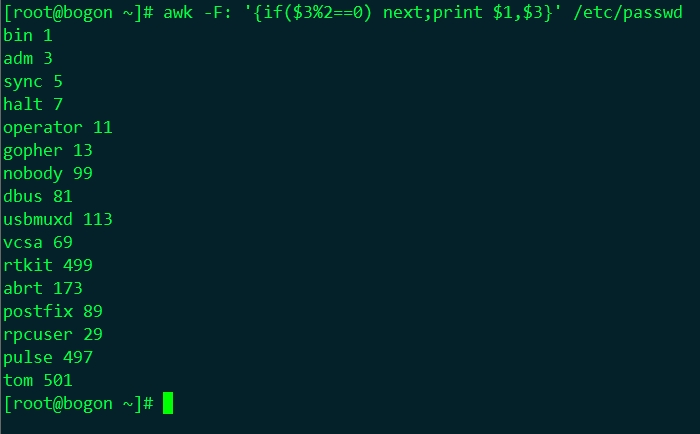
提前結束對本行文字的處理,並接著處理下一行;例如,下面的命令將顯示其ID號為奇數的使用者:
範例:
|
1
|
# awk -F: '{if($3%2==0) next;print $1,$3}' /etc/passwd |
9、awk中使用陣列
⑴、 陣列
array[index-expression]
index-expression可以使用任意字串;需要注意的是,如果某資料組元素事先不存在,那麼在參照其時,awk會自動建立此元素並初始化為空串;因此,要判斷某資料組中是否存在某元素,需要使用index in array的方式。
要遍歷陣列中的每一個元素,需要使用如下的特殊結構:
語法
for (var in array) { statement1, ... }
其中,var用於參照陣列下標,而不是元素值;
範例:
|
1
|
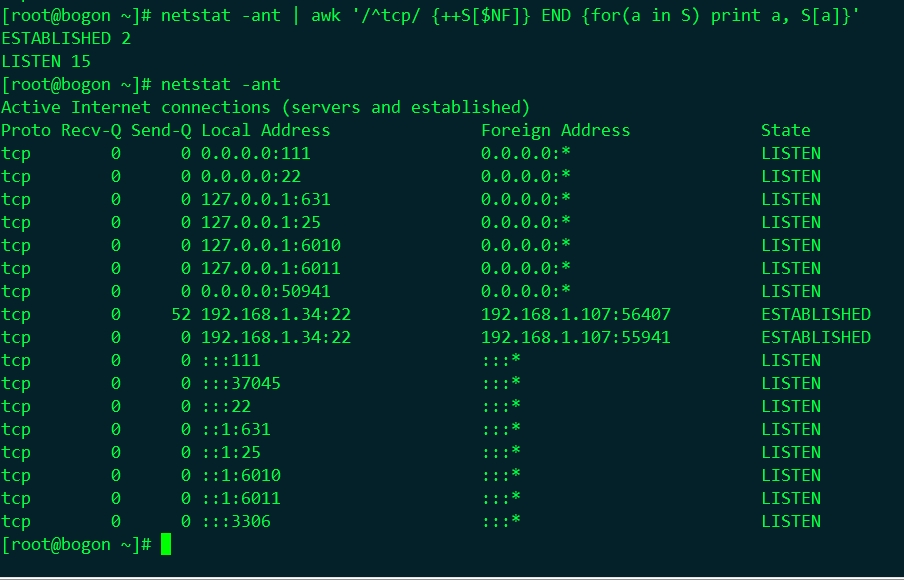
#netstat -ant | awk '/^tcp/ {++S[$NF]} END {for(a in S) print a, S[a]}' |
⑵、 刪除陣列變數
從關係陣列中刪除陣列索引需要使用delete命令。使用格式為:
delete array[index]
10、awk的內建函數
split(string, array [, fieldsep [, seps ] ])
功能:將string表示的字串以fieldsep為分隔符進行分隔,並將分隔後的結果儲存至array為名的陣列中;陣列下標為從1開始的序列;
範例:
|
1
2
3
|
# netstat -ant | awk '/:80>/{split($5,clients,":");IP[clients[1]]++}END{for(i in IP){print IP[i],i}}' | sort -rn | head -50 # netstat -tan | awk '/:80>/{split($5,clients,":");ip[clients[4]]++}END{for(a in ip) print ip[a],a}' | sort -rn | head -50 # df -lh | awk '!/^File/{split($5,percent,"%");if(percent[1]>=20){print $1}}' |

length([string])
功能:返回string字串中字元的個數;
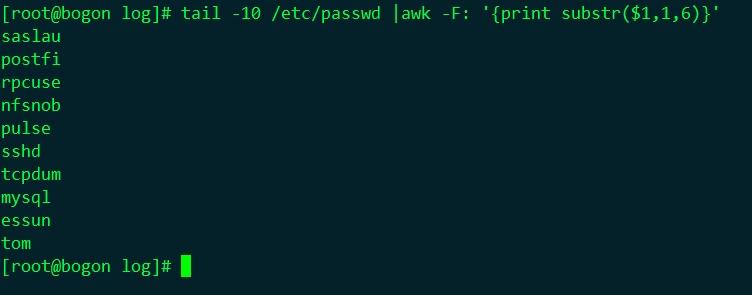
substr(string, start [, length])
功能:取string字串中的子串,從start開始,取length個;start從1開始計數;
|
1
|
# tail -10 /etc/passwd |awk -F: '{print substr($1,1,6)}' |
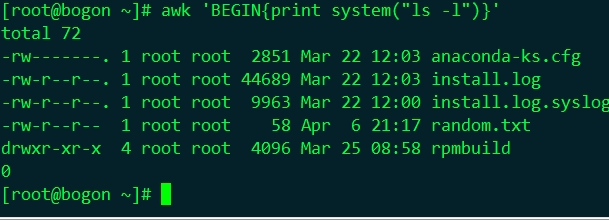
system(command)
功能:執行系統command並將結果返回至awk命令
|
1
|
# awk 'BEGIN{print system("ls -l")}' |
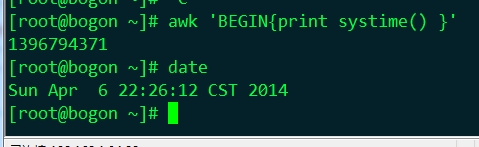
systime()
功能:systime函數返回從1970年1月1日開始到當前時間(不計閏年)的整秒數
tolower(s)
功能:將s中的所有字母轉為小寫
toupper(s)
功能:將s中的所有字母轉為大寫
|
1
|
# awk 'BEGIN{s="acl";print toupper(s)}' |

================================完===================================================
PS:
awk簡單應用到此結束!
AWK簡介及使用範例 http://www.linuxidc.com/Linux/2013-12/93519.htm
AWK 簡介和例子 http://www.linuxidc.com/Linux/2012-12/75441.htm
Shell指令碼之AWK文字編輯器語法 http://www.linuxidc.com/Linux/2013-11/92787.htm
正規表示式中AWK的學習和使用 http://www.linuxidc.com/Linux/2013-10/91892.htm
文字資料處理之AWK 圖解 http://www.linuxidc.com/Linux/2013-09/89589.htm
如何在Linux中使用awk命令 http://www.linuxidc.com/Linux/2014-10/107542.htm
文字分析工具-awk http://www.linuxidc.com/Linux/2014-12/110939.htm
本文永久更新連結地址:http://www.linuxidc.com/Linux/2016-02/128150.htm

相關文章