
2021-05-12 14:32:11
Linux文字處理工具grep和正規表示式及egrep與grep區別
2020-06-16 17:35:49
文字處理工具grep,正規表示式在Linux學習過程中很容易出現困惑與障礙的地方,這裡分享下學習這方面內容的一些感受。
grep Global search REgular expression and Print out the line
作用:文字搜尋工具,根據使用者指定的‘模式(過濾條件)’對目標文字逐行進行匹配檢查;列印匹配到的行;
‘模式’:由正規表示式的元字元及文字字元所編寫出的過濾條件。
grep [OPTIONS] PATTERN [FILE...]
grep [OPTIONS] [-e PATTERN | -f FILE] [FILE...]
常用選項:
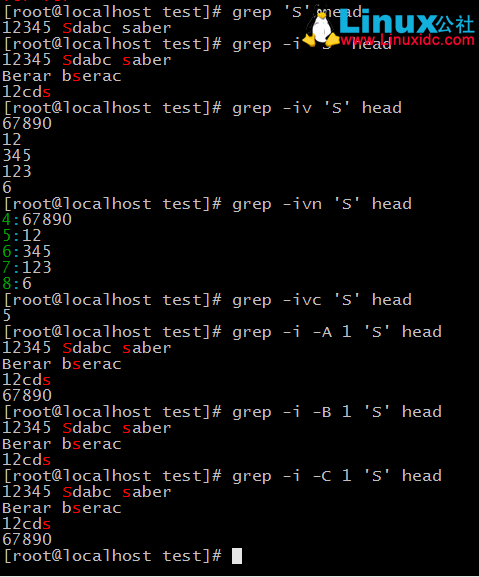
-i:忽略字元大小寫
-o:僅顯示匹配到的字串本身
-v:顯示不能被模式匹配到的行
-E:支援擴充套件正規表示式元字元
-q:靜默模式,匹配不顯示
-A#:after,顯示匹配條件所在行的後#行
-B#:before,顯示匹配條件所在行的前#行
-C#:context,顯示匹配條件所在行的前後#行
-n:顯示匹配的行號(用的較少)
-c: 統計匹配的行數(用的較少)
下面以幾個小實驗對grep的用法及選項做下具體的演示
實驗目錄/test 文字/test/head
|
1
2
3
4
5
6
7
8
9
|
[root@localhost test]# cat head 12345 Sdabc saber Berar bserac 12cds 67890 12 345 123 6 |
正規表示式:Regual Expression,REGEXP
它由一類特殊字元及文字字元所編寫的模式,其中有些字元不表示其字面意義,而是用於表示控制或通配的功能。
它分兩類:基本正規表示式BRE、擴充套件正規表示式ERE
基本正規表示式元字元:
包括:字元匹配、匹配次數、位置錨定、分組
字元匹配:
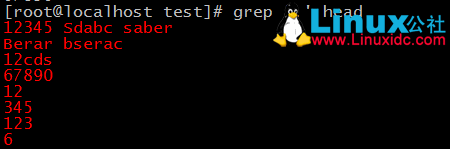
. :匹配任意單個字元; [] :匹配指定範圍內的任意單個字元
[^] :匹配指定範圍外的任意單個字元
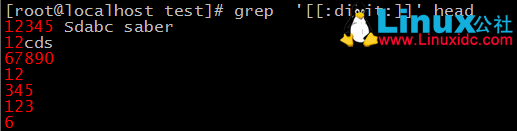
常用集合:[:digit:]、[:lower:]、[:upper:]、[:alpha:]、[:alnum:]、[:punct:]、[:space:]

匹配次數:用在要指定次數的字元後面,用於指定前面的字元要出現的次數
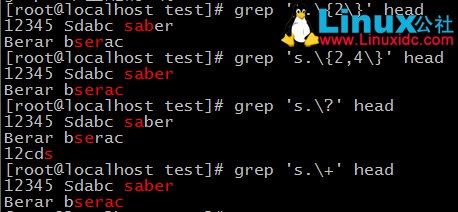
*:匹配前面的字元任意次,包括0次;貪婪模式:盡可能長的匹配
.*:任意長度的任意字元
?:匹配其前面的字元0或1次
+:匹配其前面的字元至少1次
{m}:匹配前面的字元m次
{m,n}:匹配前面的字元至少m次,至多n次
{,n}:匹配前面的字元至多n次
{m,}:匹配前面的字元至少m次
位置錨定:定位出現的位置
^:行首錨定,用於模式的最左側
$:行尾錨定,用於模式的最右側
^PATTERN$: 用於模式匹配整行
^$: 空行
^[[:space:]]*$ :空白行
單詞:非特殊字元組成的連續字元在Linux看來都稱單詞
< 或b:詞首錨定,用於單詞模式的左側
> 或b:詞尾錨定;用於單詞模式的右側
<PATTERN>:匹配完整的單詞
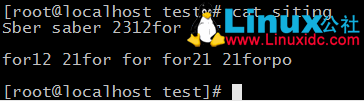
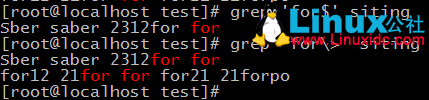
1、查詢以for開頭的行

2、檢索只含有for的字串;檢索含有for的內容
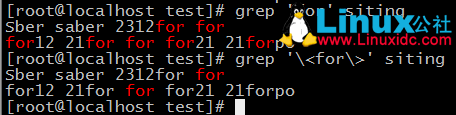
3、檢索以for結尾的行;檢索以for結尾的字串
分組:():將一個或多個字元捆綁在一起,當作一個整體進行處理,如:(root)+
分組括號中的模式匹配到的內容會被正規表示式引擎記錄於內部的變數中,這些變數的命名方式為: 1, 2, 3, ...
1: 從左側起,第一個左括號以及與之匹配右括號之間的模式所匹配到的字元;
範例:(string1+(string2)*)
1: string1+(string2)*
2: string2
後向參照:參照前面的分組括號中的模式所匹配字元(而非模式本身)

上述命令意思是檢索包含有for字串後跟任意字元且出現一次,連續出現上述情況兩次擷取結果。後面的1是重複第一個括號內的檢索物件。
egrep= grep -E
egrep[OPTIONS] PATTERN [FILE...]
擴充套件正規表示式的元字元:
字元匹配:同基本正規表示式
次數匹配:
*:匹配前面字元任意次
?: 0或1次
+:1次或多次
{m}:匹配m次
{m,n}:至少m,至多n次
位置錨定:同基本正規表示式
分組:
()
後向參照:1, 2, ...
或者:
a|b
C|cat: C或cat
(C|c)at:Cat或cat
最後我們通過9個例子來感受grep與正規表示式結合所能實現的功能
1、顯示/proc/meminfo檔案中以大小s開頭的行
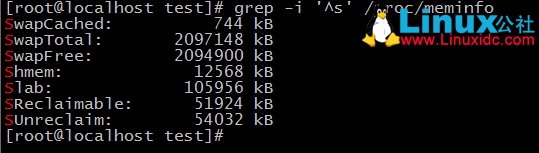
這個只需要知道grep的選項i就能輕鬆解決。
2、顯示/etc/passwd檔案中不以/bin/bash結尾的行
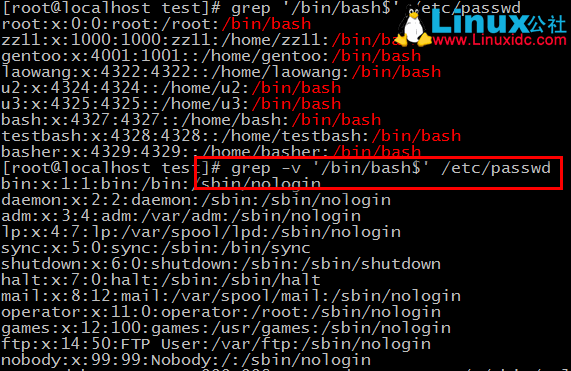
先使用grep檢索出包含有以“/bin/bash”結尾的行,再使用grep的-v取不以上面結果的行。類似數學中的補集效果。
3、找出ifconfig命令結果中本機的所有IPv4地址
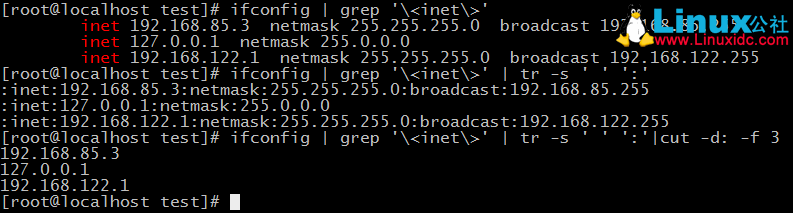
這個分為三步:
1)通過grep鎖定包含有IPV4的行,這個通過分析ifconfig列出的資訊可以看出規律,只要包含有IPv4的開頭都有inet這個字母,所以我們只需要檢索它就行了
2)接下來使用tr將所有空替換為“:”並壓縮
3)使用cut實現結果。
4、查出分割區空間使用率的最大百分比值
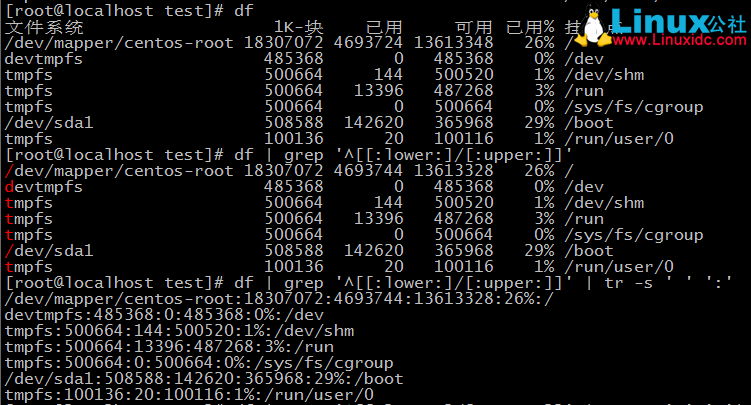
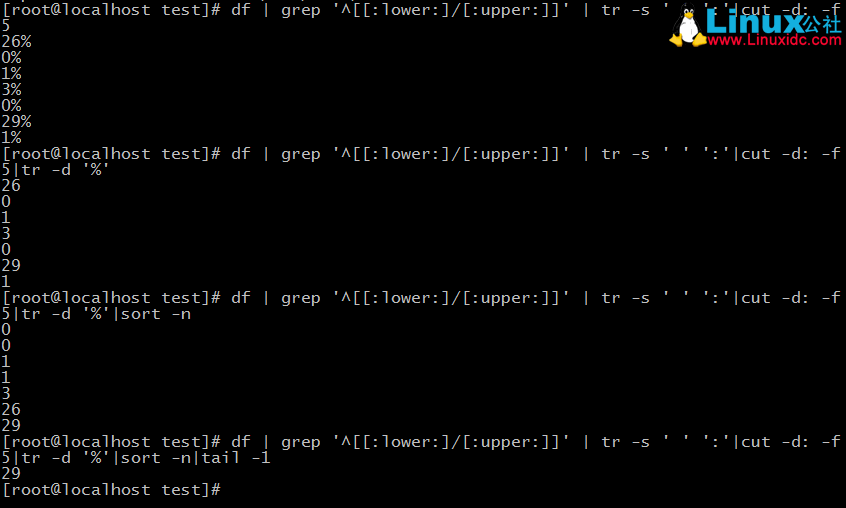
這個大致分6步:
1)過濾漢字
2)使用tr替換所有空為":"並壓縮
3)使用cut剪下出含有使用率百分比的數值
4)再次使用tr剔除%
5)使用sort按數值大小寫排序
6)使用tail取出最大值
5、顯示使用者rpc預設的shell程式

上面的檢索條件是以rpc為行首且以它為字元結尾的行
6、找出/etc/passwd中的兩位或三位數
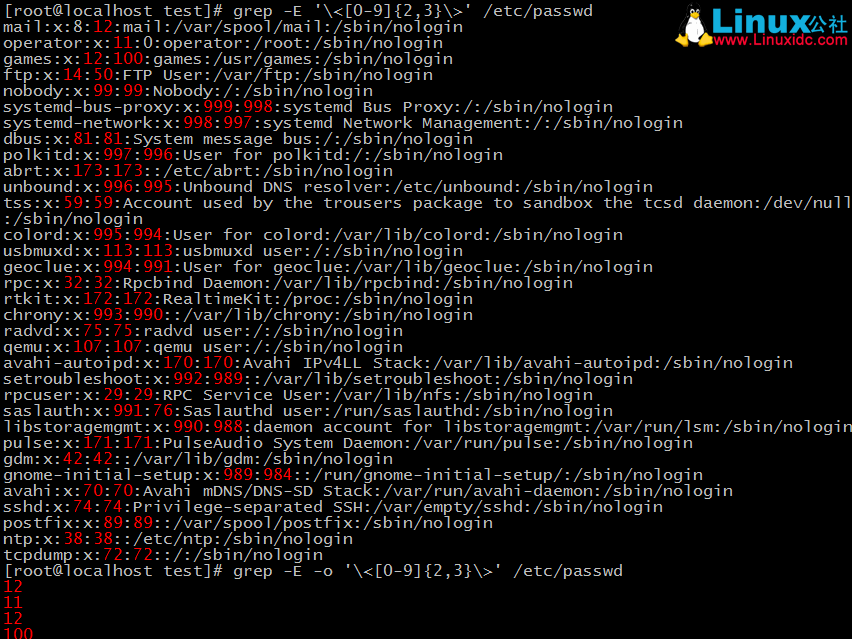
這裡使用的是擴充套件正規表示式因為可以是表示式更簡潔
這裡需要注意的是要以兩位或三位數為字串,這需要對其進行開頭與結尾的字元錨定
7、找出/etc/rc.d/init.d/functions檔案中行首為某單詞(包括下劃線)後面跟一個小括號的行
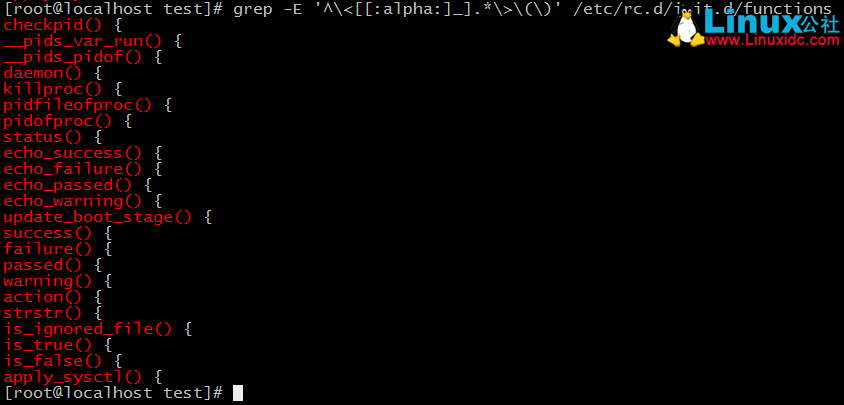
當我們想好要過濾的條件後,要對其進行行首及字元的錨定,否則會導致條件範圍不嚴謹
這裡要注意的是.*>(),如果這裡改寫為.*()>則會失敗,具體可以自己想想。其實.*已經包括了"()",所以後面的是重複的,這樣就容易出錯。
8、使用egrep取出/etc/rc.d/init.d/functions中其基名


上面是兩種方法,一種利用grep直接檢索出來,另一種的思想是分割。各有特點
9、利用擴充套件正規表示式分別表示0-9、10-99、100-199、200-249、250-255
<[0-9]>:0-9
<[1-9][0-9]|>:10-99
<1[0-9][0-9]> | <1[0-9]{2}>:100-199
<2[0-4][0-9]> :200-249
<25[0-5]>:250-255
上面只是對grep及正規表示式的簡要總結,不過只要掌握好這基本的內容自己也就可以進行更深入的學習了。
grep使用簡明及正規表示式 http://www.linuxidc.com/Linux/2013-08/88534.htm
Linux下Shell程式設計——grep命令的基本運用 http://www.linuxidc.com/Linux/2013-06/85525.htm
grep 命令詳解及相關事例 http://www.linuxidc.com/Linux/2014-07/104041.htm
Linux基礎命令之grep詳解 http://www.linuxidc.com/Linux/2013-07/87919.htm
設定grep高亮顯示匹配項 http://www.linuxidc.com/Linux/2014-09/106871.htm
Linux grep命令學習與總結 http://www.linuxidc.com/Linux/2014-10/108112.htm
14 個 grep 命令的例子 http://www.linuxidc.com/Linux/2015-05/117626.htm
本文永久更新連結地址:http://www.linuxidc.com/Linux/2016-08/134046.htm

相關文章