<em>Mac</em>Book项目 2009年学校开始实施<em>Mac</em>Book项目,所有师生配备一本<em>Mac</em>Book,并同步更新了校园无线网络。学校每周进行电脑技术更新,每月发送技术支持资料,极大改变了教学及学习方式。因此2011
2021-06-01 09:32:01
SQL Server的排名函數是對查詢的結果進行排名和分組,TSQL共有4個排名函數,分別是:ROW_NUMBER、RANK、DENSE_RANK和NTILE。
他們和OVER()函數搭配使用,按照特定的順序排名。
排名開窗函數可以單獨使用ORDER BY 語句,也可以和PARTITION BY同時使用。
為每一組的行按順序生成一個唯一的序號。
序列從1開始,按照順序依次 +1 遞增。分組內序列的最大值就是該分組內的行的數目。
ROW_NUMBER ( ) OVER ( [ PARTITION_BY_clause ] order_by_clause )
也為每一組的行生成一個序號,但如果按照ORDER BY的排序,如果有相同的值會生成相同的序號,並且接下來的序號是不連續的。
例如,班級中,A,B分數都是100分,C的分數是90分,那麼A和B的排名是1,C的排名是3。
和RANK(排名)類似,不同的是如果有相同的序號,那麼接下來的序號不會間斷。
例如,班級中,A,B分數都是100分,C的分數是90分,那麼A和B的排名是1,C的排名是2。
按照指定的數目將資料進行分組,併為每一組生成一個序號。
特別地,NTILE(4) 把一個分組分成4份,叫做Quartile。例如,以下指令碼顯示各個排名函數的執行結果:
select Department
,LastName
,Rate
,row_number() over(order by Rate) as [row number]
,rank() over(order by rate) as rate_rank
,dense_rank() over(order by rate) as rate_dense_rank
,ntile(4) over(order by rate) as quartile_by_rate
from #data
分析函數基於分組,計算分組內資料的聚合值,經常會和視窗函數OVER()一起使用,使用分析函數可以很方便地計算同比和環比,獲得中位數,獲得分組的最大值和最小值。
分析函數和聚合函數不同,不需要GROUP BY子句,對SELECT子句的結果集,通過OVER()子句分組。
注意:distinct子句的執行順序是在分析函數之後。
使用以下指令碼插入範例資料:
;with cte_data as ( select 'Document Control' as Department,'Arifin' as LastName,17.78 as Rate union all select 'Document Control','Norred',16.82 union all select 'Document Control','Kharatishvili',16.82 union all select 'Document Control','Chai',10.25 union all select 'Document Control','Berge',10.25 union all select 'Information Services','Trenary',50.48 union all select 'Information Services','Conroy',39.66 union all select 'Information Services','Ajenstat',38.46 union all select 'Information Services','Wilson',38.46 union all select 'Information Services','Sharma',32.45 union all select 'Information Services','Connelly',32.45 union all select 'Information Services','Berg',27.40 union all select 'Information Services','Meyyappan',27.40 union all select 'Information Services','Bacon',27.40 union all select 'Information Services','Bueno ',27.40 ) select Department,LastName,Rate into #data from cte_data go
SQL Server中共有4類分析函數。
在一次查詢中,對資料表進行排序,把已排序的資料從上向下看作是一個序列,對當前行而言,在序列上方的為後,在序列下方的為前。
在同一分組內,對於當前行:
LAG (scalar_expression [,offset] [,default]) OVER ( [ partition_by_clause ] order_by_clause ) LEAD ( scalar_expression [ ,offset ] , [ default ] ) OVER ( [ partition_by_clause ] order_by_clause )
引數註釋:
結果日期,這兩個函數特別適合用於計算同比和環比。
select DepartMent ,LastName,Rate
,lag(Rate,1,0) over(partition by Department order by LastName) as LastRate
,lead(Rate,1,0) over(partition by Department order by LastName) as NextRate
from #data order by Department ,LastName按照DepartMent進行分組,對Document Control這一小組進行分析:

以下程式程式碼用來示範如何透過 LAG 函數來計算每一列與前一列的 c2 欄位相差幾天:
declare @t table
(
c1 int identity
,c2 date
)
insert into @t (c2)
select '20120101'
union all
select '20120201'
union all
select '20120110'
union all
select '20120221'
union all
select '20120121'
union all
select '20120203'
select c1,c2
,LAG(c2) OVER (ORDER BY c2) as previous_c2
,DateDiff(day,LAG(c2) OVER (ORDER BY c2),c2) as diff
from @t
order by c2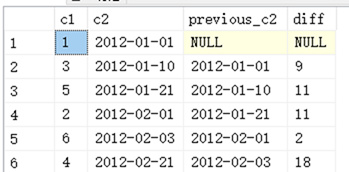
SQL SERVER 2012引入的函數。
獲取分組內排在最末尾的行和排在第一位的行:
LAST_VALUE ( [scalar_expression ) OVER ( [ partition_by_clause ] order_by_clause rows_range_clause ) FIRST_VALUE ( [scalar_expression ] ) OVER ( [ partition_by_clause ] order_by_clause [ rows_range_clause ] )
例如:
select Department, LastName, Rate,
row_number() over (partition by Department order by LastName) as FIRSTVALUE,
first_value(Rate) over (partition by Department order by LastName rows between unbounded preceding and unbounded following) as FIRSTVALUE,
last_value(Rate) over (partition by Department order by LastName rows between unbounded preceding and unbounded following) as LASTVALUE
from #data
order by Department, LastName;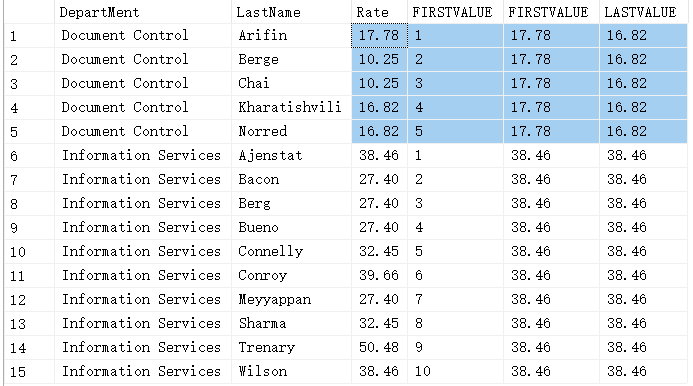
以下程式碼,用於計算累積分佈和排名百分比:
select Department,LastName ,Rate
,cume_dist() over(partition by Department order by Rate) as CumeDist
,percent_rank() over(partition by Department order by Rate) as PtcRank
,rank() over(partition by Department order by Rate asc) as rank_number
,count(0) over(partition by Department) as count_in_group
from #data
order by DepartMent
,Rate desc
解釋:
首先,NULL都會被當作最小值。
1、cume_dist的計算方法:小於等於當前行值的行數/總行數。
比如,第3行值為16.82,有4行的值小於等於16.82,本組總行數5行,因此CUME_DIST為4/5=0.8 。
再比如,第4行值為10.25,行值小於等於10.25的共2行,本組總行數5行,因此CUME_DIST為2/5=0.4 。
2、PERCENT_RANK的計算方法:當前RANK值-1/總行數-1 。
比如,第4行的RANK值為1,本組總行數5行,因此PERCENT_RANK為1-1/5-1= 0。
再比如,第7行的RANK值為9,本組總行數10行,因此PERCENT_RANK為9-1/10-1=0.8888888888888889。
PERCENTILE_CONT和PERCENTILE_DISC都是為了計算百分位的數值,比如計算在某個百分位時某個欄位的數值是多少。
以下指令碼用於獲得分位數:
select Department ,LastName ,Rate
,PERCENTILE_CONT(0.5) WITHIN GROUP (ORDER BY Rate) OVER (PARTITION BY Department) AS MedianCont
,PERCENTILE_DISC(0.5) WITHIN GROUP (ORDER BY Rate) OVER (PARTITION BY Department) AS MedianDisc
,row_number() over(partition by Department order by Rate) as rn
from #data order by DepartMent ,Rate asc
到此這篇關於SQL Server排名函數與分析函數的文章就介紹到這了。希望對大家的學習有所幫助,也希望大家多多支援it145.com。
相關文章

<em>Mac</em>Book项目 2009年学校开始实施<em>Mac</em>Book项目,所有师生配备一本<em>Mac</em>Book,并同步更新了校园无线网络。学校每周进行电脑技术更新,每月发送技术支持资料,极大改变了教学及学习方式。因此2011
2021-06-01 09:32:01
综合看Anker超能充系列的性价比很高,并且与不仅和iPhone12/苹果<em>Mac</em>Book很配,而且适合多设备充电需求的日常使用或差旅场景,不管是安卓还是Switch同样也能用得上它,希望这次分享能给准备购入充电器的小伙伴们有所
2021-06-01 09:31:42
除了L4WUDU与吴亦凡已经多次共事,成为了明面上的厂牌成员,吴亦凡还曾带领20XXCLUB全队参加2020年的一场音乐节,这也是20XXCLUB首次全员合照,王嗣尧Turbo、陈彦希Regi、<em>Mac</em> Ova Seas、林渝植等人全部出场。然而让
2021-06-01 09:31:34
目前应用IPFS的机构:1 谷歌<em>浏览器</em>支持IPFS分布式协议 2 万维网 (历史档案博物馆)数据库 3 火狐<em>浏览器</em>支持 IPFS分布式协议 4 EOS 等数字货币数据存储 5 美国国会图书馆,历史资料永久保存在 IPFS 6 加
2021-06-01 09:31:24
开拓者的车机是兼容苹果和<em>安卓</em>,虽然我不怎么用,但确实兼顾了我家人的很多需求:副驾的门板还配有解锁开关,有的时候老婆开车,下车的时候偶尔会忘记解锁,我在副驾驶可以自己开门:第二排设计很好,不仅配置了一个很大的
2021-06-01 09:30:48
不仅是<em>安卓</em>手机,苹果手机的降价力度也是前所未有了,iPhone12也“跳水价”了,发布价是6799元,如今已经跌至5308元,降价幅度超过1400元,最新定价确认了。iPhone12是苹果首款5G手机,同时也是全球首款5nm芯片的智能机,它
2021-06-01 09:30:45