<em>Mac</em>Book项目 2009年学校开始实施<em>Mac</em>Book项目,所有师生配备一本<em>Mac</em>Book,并同步更新了校园无线网络。学校每周进行电脑技术更新,每月发送技术支持资料,极大改变了教学及学习方式。因此2011
2021-06-01 09:32:01
模組可以看成是一堆函數的集合體。
一個py檔案內部就可以放一堆函數,因此一個py檔案就可以看成一個模組。
如果這個py檔案的檔名為module.py,模組名則是module。
在Python中,總共有以下四種形式的模組:
一般我們使用import和from...import...匯入模組。
以下述spam.py內的檔案程式碼為例。
# spam.py
print('from the spam.py')
money = 1000
def read1():
print('spam模組:', money)
def read2():
print('spam模組')
read1()
def change():
global money
money = 0語法如下:
import module1[, module2[,... moduleN]
import匯入的模組,存取需要加字首。
import首次匯入模組發生了3件事:
注意:模組的重複匯入會直接參照之前創造好的結果,不會重複執行模組的檔案。
# run.py import spam # from the spam.py import spam money = 111111 spam.read1() # 'spam模組:1000' spam.change() print(spam.money) # 0 print(money) # 111111
# run.py import spam as sm money = 111111 sm.money sm.read1() # 'spam模組:1000' sm.read2 sm.change() print(money) # 1000
import spam, time, os # 推薦使用下述方式 import spam import time import os
語法如下:
from modname import name1[, name2[, ... nameN]]
這個宣告不會把整個模組匯入到當前的名稱空間中,它只會將模組裡的一個或多個函數引入進來。
from...import...匯入的模組,存取不需要加字首。
from...import...首次匯入模組發生了3件事:
# run.py from spam import money from spam import money,read1 money = 10 print(money) # 10
# spam.py __all__ = ['money', 'read1'] # 只允許匯入'money'和'read1' # run.py from spam import * # 匯入spam.py內的所有功能,但會受限制於__all__ money = 111111 read1() # 'spam模組:1000' change() read1() # 'spam模組:0' print(money) # 111111
以下情況會出現迴圈匯入:
# m1.py
print('from m1.py')
from m2 import x
y = 'm1'
# m2.py
print('from m2.py')
from m1 import y
x = 'm2'可以使用函數定義階段只識別語法的特性解決迴圈匯入的問題,或從本質上解決迴圈匯入的問題,但是最好的解決方法是不要出現迴圈匯入。
方案一:
# m1.py
print('from m1.py')
def func1():
from m2 import x
print(x)
y = 'm1'
# m2.py
print('from m2.py')
def func1():
from m1 import y
print(y)
x = 'm2'方案二:
5、# m1.py
print('from m1.py')
y = 'm1'
from m2 import x
# m2.py
print('from m2.py')
x = 'm2'
from m1 import y內建的函數 dir() 可以找到模組內定義的所有名稱。以一個字串列表的形式返回:
dir(sys) ['__displayhook__', '__doc__', '__excepthook__', '__loader__', '__name__', '__package__', '__stderr__', '__stdin__', '__stdout__', '_clear_type_cache', '_current_frames', '_debugmallocstats', '_getframe', '_home', '_mercurial', '_xoptions', 'abiflags', 'api_version', 'argv', 'base_exec_prefix', 'base_prefix', 'builtin_module_names', 'byteorder', 'call_tracing', 'callstats', 'copyright', 'displayhook', 'dont_write_bytecode', 'exc_info', 'excepthook', 'exec_prefix', 'executable', 'exit', 'flags', 'float_info', 'float_repr_style', 'getcheckinterval', 'getdefaultencoding', 'getdlopenflags', 'getfilesystemencoding', 'getobjects', 'getprofile', 'getrecursionlimit', 'getrefcount', 'getsizeof', 'getswitchinterval', 'gettotalrefcount', 'gettrace', 'hash_info', 'hexversion', 'implementation', 'int_info', 'intern', 'maxsize', 'maxunicode', 'meta_path', 'modules', 'path', 'path_hooks', 'path_importer_cache', 'platform', 'prefix', 'ps1', 'setcheckinterval', 'setdlopenflags', 'setprofile', 'setrecursionlimit', 'setswitchinterval', 'settrace', 'stderr', 'stdin', 'stdout', 'thread_info', 'version', 'version_info', 'warnoptions']
如果沒有給定引數,那麼 dir() 函數會羅列出當前定義的所有名稱:
a = [1, 2, 3, 4, 5] import fibo fib = fibo.fib print(dir()) # 得到一個當前模組中定義的屬性列表 # ['__builtins__', '__name__', 'a', 'fib', 'fibo', 'sys'] b = 5 # 建立一個新的變數 'a' print(dir()) # ['__annotations__', '__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__spec__', 'a', 'b'] del b # 刪除變數名a print(dir()) # ['__annotations__', '__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__spec__', 'a']
如果我們在執行run.py檔案的時候,快速刪除mmm.py檔案,我們會發現檔案會繼續執行,而不會報錯,因為mmm已經被匯入記憶體當中。如果我們再一次執行run.py時會報錯,因為mmm.py已經被刪除了。
# test.py import m1 # 從m1.py檔案中匯入的,然後會生成m1模組的名稱空間 import time # 刪除m1.py檔案,m1模組的名稱空間仍然存在 time.sleep(10) import m1 # 不報錯,一定不是從檔案中獲取了m1模組,而是從記憶體中獲取的
驗證先從內建中找,不會先找自定義的time.py檔案。
# time.py
print('from time.py')
# run.py
import time
print(time) #import sys for n in sys.path: print(n) # C:PycharmProjectsuntitledvenvScriptspython.exe C:/PycharmProjects/untitled/hello.py # C:PycharmProjectsuntitled # C:PycharmProjectsuntitled # C:PythonPython38python38.zip # C:PythonPython38DLLs # C:PythonPython38lib # C:PythonPython38 # C:PycharmProjectsuntitledvenv # C:PycharmProjectsuntitledvenvlibsite-packages
如果mmm.py在C:PycharmProjectsuntitledday16路徑下,而執行檔案路徑為C:PycharmProjectsuntitled,如果普通匯入一定會報錯,我們可以把C:PycharmProjectsuntitledday16新增到環境變數sys.path中,防止報錯。
# run.py import sys sys.path.append(r'C:PycharmProjectsuntitledday16') print(sys.path) import mmm mmm.f1()
假設我們有如下目錄結構的檔案,檔案內程式碼分別是:

而hello和spam.py不是同目錄下的,因此run.py的環境變數無法直接找到m2,需要從資料夾匯入
from aa import spam print(spam.money)
一個模組被另一個程式第一次引入時,其主程式將執行。如果我們想在模組被引入時,模組中的某一程式塊不執行,我們可以用__name__屬性來使該程式塊僅在該模組自身執行時執行。
python檔案總共有兩種用途,一種是執行檔案;另一種是被當做模組匯入。
每個模組都有一個__name__屬性,當其值是'__main__'時,表明該模組自身在執行,否則是被引入。
1、當run.py執行的時候,aaa.py被當做參照模組,它的__name__ == 'aaa'(模組名),會執行aaa.py中的f1()。
# aaa.py
x = 1
def f1():
print('from f1')
f1()
# run.py
import aaa2、aaa.py被當做可執行檔案時,加上__name__ == '__main__',單獨執行aaa.py才會執行aaa.py中的f1()。 run.py執行時可以防止執行f1()。
# aaa.py
x = 1
def f1():
print('from f1')
if __name__ == '__main__':
f1()包是一種管理 Python 模組名稱空間的形式,包的本質就是一個含有.py的檔案的資料夾。
包採用"點模組名稱"。比如一個模組的名稱是 A.B, 那麼他表示一個包 A中的子模組 B 。
目錄只有包含一個叫做 __init__.py 的檔案才會被認作是一個包。
在匯入一個包的時候,Python 會根據 sys.path 中的目錄來尋找這個包中包含的子目錄。
匯入包發生的三件事:
匯入包就是在匯入包下的.py,匯入m1就是匯入m1中的__init__。
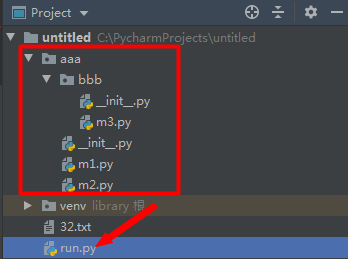
import 可以每次只匯入一個包裡面的特定模組,他必須使用全名去存取。
import aaa.bbb.m3 print(aaa.bbb.m3.func3())
import方式不能匯入函數、變數:import aaa.bbb.m3.f3錯誤
這種方式不需要那些冗長的字首進行存取
from aaa.bbb import m3 print(m3.func3())
這種方式不需要那些冗長的字首進行存取
from aaa.bbb.m3 import func3 print(func3())
# aaa/.py from aaa.m1 import func1 from aaa.m2 import func2
from .m1 import func1 from .m2 import func2
匯入語句遵循如下規則:如果包定義檔案 __init__.py 存在一個叫做 __all__ 的列表變數,那麼在使用 from package import * 的時候就把這個列表中的所有名字作為包內容匯入。
這裡有一個例子,在:file:sounds/effects/__init__.py中包含如下程式碼:
__all__ = ["echo", "surround", "reverse"]
這表示當你使用from sound.effects import *這種用法時,你只會匯入包裡面這三個子模組。
為了提高程式的可讀性與可維護性,我們應該為軟體設計良好的目錄結構,這與規範的編碼風格同等重要,簡而言之就是把軟體程式碼分檔案目錄。假設你要寫一個ATM軟體,你可以按照下面的目錄結構管理你的軟體程式碼:
ATM/ |-- core/ | |-- src.py # 業務核心邏輯程式碼 | |-- api/ | |-- api.py # 介面檔案 | |-- db/ | |-- db_handle.py # 運算元據檔案 | |-- db.txt # 儲存資料檔案 | |-- lib/ | |-- common.py # 共用功能 | |-- conf/ | |-- settings.py # 設定相關 | |-- bin/ | |-- run.py # 程式的啟動檔案,一般放在專案的根目錄下,因為在執行時會預設將執行檔案所在的資料夾作為sys.path的第一個路徑,這樣就省去了處理環境變數的步驟 | |-- log/ | |-- log.log # 紀錄檔檔案 | |-- requirements.txt # 存放軟體依賴的外部Python包列表,詳見https://pip.readthedocs.io/en/1.1/requirements.html |-- README # 專案說明檔案
# settings.py import os BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__))) DB_PATH = os.path.join(BASE_DIR, 'db', 'db.txt') LOG_PATH = os.path.join(BASE_DIR, 'log', 'user.log') # print(DB_PATH) # print(LOG_PATH)
# common.py
import time
from conf import settings
def logger(msg):
current_time = time.strftime('%Y-%m-%d %X')
with open(settings.LOG_PATH, mode='a', encoding='utf-8') as f:
f.write('%s %s' % (current_time, msg))# src.py
from conf import settings
from lib import common
def login():
print('登陸')
def register():
print('註冊')
name = input('username>>: ')
pwd = input('password>>: ')
with open(settings.DB_PATH, mode='a', encoding='utf-8') as f:
f.write('%s:%sn' % (name, pwd))
# 記錄紀錄檔。。。。。。
common.logger('%s註冊成功' % name)
print('註冊成功')
def shopping():
print('購物')
def pay():
print('支付')
def transfer():
print('轉賬')
func_dic = {
'1': login,
'2': register,
'3': shopping,
'4': pay,
'5': transfer,
}
def run():
while True:
print("""
1 登陸
2 註冊
3 購物
4 支付
5 轉賬
6 退出
""")
choice = input('>>>: ').strip()
if choice == '6': break
if choice not in func_dic:
print('輸入錯誤命令,傻叉')
continue
func_dic[choice]()# run.py import sys import os BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__))) sys.path.append(BASE_DIR) from core import src if __name__ == '__main__': src.run()
https://docs.python.org/zh-cn/3.8/library/index.html
到此這篇關於Python基礎之模組的文章就介紹到這了。希望對大家的學習有所幫助,也希望大家多多支援it145.com。
相關文章

<em>Mac</em>Book项目 2009年学校开始实施<em>Mac</em>Book项目,所有师生配备一本<em>Mac</em>Book,并同步更新了校园无线网络。学校每周进行电脑技术更新,每月发送技术支持资料,极大改变了教学及学习方式。因此2011
2021-06-01 09:32:01
综合看Anker超能充系列的性价比很高,并且与不仅和iPhone12/苹果<em>Mac</em>Book很配,而且适合多设备充电需求的日常使用或差旅场景,不管是安卓还是Switch同样也能用得上它,希望这次分享能给准备购入充电器的小伙伴们有所
2021-06-01 09:31:42
除了L4WUDU与吴亦凡已经多次共事,成为了明面上的厂牌成员,吴亦凡还曾带领20XXCLUB全队参加2020年的一场音乐节,这也是20XXCLUB首次全员合照,王嗣尧Turbo、陈彦希Regi、<em>Mac</em> Ova Seas、林渝植等人全部出场。然而让
2021-06-01 09:31:34
目前应用IPFS的机构:1 谷歌<em>浏览器</em>支持IPFS分布式协议 2 万维网 (历史档案博物馆)数据库 3 火狐<em>浏览器</em>支持 IPFS分布式协议 4 EOS 等数字货币数据存储 5 美国国会图书馆,历史资料永久保存在 IPFS 6 加
2021-06-01 09:31:24
开拓者的车机是兼容苹果和<em>安卓</em>,虽然我不怎么用,但确实兼顾了我家人的很多需求:副驾的门板还配有解锁开关,有的时候老婆开车,下车的时候偶尔会忘记解锁,我在副驾驶可以自己开门:第二排设计很好,不仅配置了一个很大的
2021-06-01 09:30:48
不仅是<em>安卓</em>手机,苹果手机的降价力度也是前所未有了,iPhone12也“跳水价”了,发布价是6799元,如今已经跌至5308元,降价幅度超过1400元,最新定价确认了。iPhone12是苹果首款5G手机,同时也是全球首款5nm芯片的智能机,它
2021-06-01 09:30:45