選自eng.uber作者:Xinyu Hu等機器之心編譯編輯:力元、陳萍近年來,隨著 Uber 在客戶中越來越受歡迎以及規模的不斷擴大,它也吸引了網際網路金融犯罪分子的目光。共謀是一種典型的
2021-06-03 21:43:12
選自eng.uber
作者:Xinyu Hu等
機器之心編譯
編輯:力元、陳萍
近年來,隨著 Uber 在客戶中越來越受歡迎以及規模的不斷擴大,它也吸引了網際網路金融犯罪分子的目光。共謀是一種典型的使用者之間的合作欺詐行為,例如使用者可以共謀,通過一個使用者宣稱信用卡被盜用,另外一個使用者進行虛假旅行,讓銀行發起信用卡退款。在本文中,來自 Uber 的幾位研究者應用了被稱為關係圖卷積網路(RGCN)的前沿深度圖學習模型來發現這種共謀,他們希望反欺詐領域的其他研究者能有所借鑑,用之解決其他的問題。
實際上,圖學習方法已經廣泛應用於欺詐檢測和推薦任務。例如,Uber Eats 外賣服務部門已經開發了一種圖學習技術,目的在於推薦最有可能吸引使用者下單的食物。圖學習已經成為提升 Uber Eats 上食物和餐廳推薦質量和相關性的有效方法之一。
檢測共謀使用了類似的技術。如下面的使用者圖所示,紅色節點代表欺詐使用者,藍色節點代表合法使用者,使用者通過業務資訊彼此連線。從圖中可以看出欺詐性使用者通常處於連線和聚集的狀態。在這裡我們介紹了一個案例研究,展示了研究人員如何建立了一個關係圖學習模型,來利用這個資訊來發現共謀使用者,並使用不同的連線類型來改善模型。

關係圖學習
在本案例研究裡,我們在小型資料樣本上應用了 RGCN 模型,以預測使用者是否在欺詐。在使用者圖中,通過資訊連線的司機和乘客可以看作兩類節點。每個使用者可以被視為圖中的一個節點,並通過嵌入向量表示。這個表示能夠對使用者及其鄰居社群的屬性進行編碼,以用於機器學習任務,如節點分類和邊預測。為了發現使用者是否欺詐,我們不僅使用了使用者節點自身的特徵,還使用了幾跳(hop)內鄰居使用者的特徵。RGCN 是基於在圖上運行的神經網路,專門為建模多關係圖資料而開發。這種類型的圖學習已經被驗證可以顯著地提升節點分類的效果。此外,我們發現,區分不同的連線類型會放大用於欺詐檢測的訊號。因此,連線的類型也被我們用於學習。
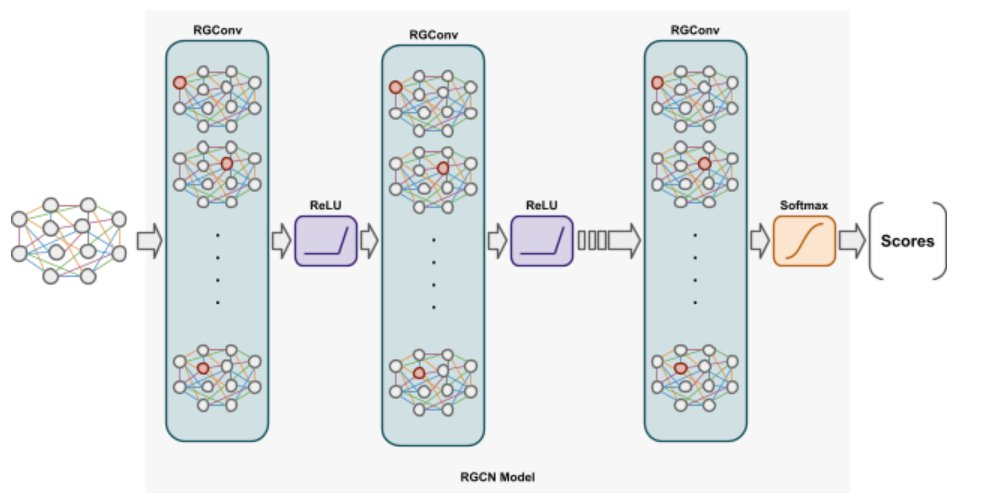
為了更好地理解我們是如何建模圖使用者資料並發現共謀,瞭解一些基礎的 RGCN 知識是有幫助的。圖卷積網路(GCN)已被證明在編碼結構化鄰域特徵方面非常有效,其中,相同的權重被分配給連線到源節點的邊。而 RGCN 會針對連線關係做變換,變換的方式取決於邊的類型和方向。因此,為每個節點計算的內容會增加邊類型的資訊進來。
如下圖所示,RGCN 模型的輸入由節點特徵和邊類型組成。所有的節點特徵先傳遞到 RGCN 層,然後通過聚合來自相連鄰居的學習表示(被稱為「訊息」),將其轉換為節點表示的向量。來自相連鄰居的訊息會根據邊的類型做加權。具體而言,模型把相鄰節點的訊息進行加權和歸一化求和,再傳遞到目標節點以學習一個 RGCN 層中的隱藏表示,然後將所有節點的隱藏表示傳遞到啟用函數(如 ReLU)中完成非線性變換。RGCN 可以通過多層訊息傳遞和圖卷積來提取高階節點表示。並最終通過將 softmax 層作為輸出層和將交叉熵作為損失函數,來學習節點的評分。

相鄰節點變換後的特徵向量的值取決於邊類型和方向。同時我們將自連線 (self-loop) 作為一種特殊的邊類型新增到每個節點上,以便可以通過層l的相應表示計算層l+ 1 上的節點表示。第l+ 1 層的隱藏表示可以用下式計算:

其中,

是模型第
l
層中節點 i 的隱藏表示;

表示邊類型為 r R 的節點 i 的鄰居集合;
W_r 為邊類型 r 的權重;
W_0 為自連線的權重;

是歸一化常數。
傳入的訊息被累積並通過逐元啟用函數σ(·)計算;
啟用函數是 ReLU(·)= max(0,·)。
用於欺詐檢測的 RGCN
Uber 有多種風險模型和多個檢查點來發現欺詐使用者。為了更好地讓 RGCN 模型服務這些風險模型,一種想法是通過這個模型得出一個欺詐評分,並將其作為下游風險模型的輸入特徵。RGCN 模型會為每個使用者給出一個欺詐評分,來表明使用者存在欺詐的風險程度。
欺詐評分的學習流程如下圖所示。通過最小化二元交叉熵損失值,模型學習使用者圖中每個節點的隱藏表示來預測使用者是否欺詐。使用者可以是司機,也可以是乘客,或者兩者都是,所以會輸出兩個分數:一個為司機的得分,一個為乘客的得分。這兩個分數作為兩個特徵提供給下游的風險模型。

模型使用兩個輸入源:節點(使用者)特徵和邊類型。我們使用一個流行的圖深度學習庫,DGL(Deep Graph Library),來構建可放入記憶體(in-memory)的司機 - 乘客關係圖。欺詐的標籤是:使用者是否在一個時間範圍內退款。我們利用特徵工程來進一步幫助模型學習。例如,司機 - 乘客圖只有兩種類型的節點:司機和乘客。每個節點類型可能具有不同的特徵。為了解決這個問題,我們採用零填充的方法來保證輸入的特徵向量具有相同的維度;另外,我們定義了不同的邊類型,並在模型訓練中學習每種類型的不同權重。
為了評估 RGCN 模型的效能和欺詐評分的效用,我們使用歷史資料對模型進行訓練。該資料的跨度為 4 個月,直到特定的日期為止。然後,我們用分割日期後 6 周的資料測試了模型的表現。具體來說,我們為使用者輸出欺詐分數,並計算精確率、召回率和 AUC。
在實驗中,我們通過在現有生產模型中新增這兩個欺詐評分作為特徵,發現精確率提高了 15%,而只是假陽性有小幅增加。如下圖所示,兩個欺詐得分在下游模型的 200 個特徵中的重要性分別排在第 4 和第 39 位。

資料管道
資料獲取
在之前的一篇博文「Food Discovery with Uber Eats」中,我們解釋瞭如何利用離線圖生態系統生成一個城市級別的使用者 - 餐廳關係圖。而在本案例中,我們主要的需求是構建一個巨大的圖,而不是幾個較小的城市級圖。我們重用了許多元件,比如 Spark 上的 Cypher,以生成一個多關係使用者圖。資料提取框架將源 Hive 錶轉換為節點和關係表。節點表儲存使用者的特徵,而關係表儲存使用者之間不同類型的邊。
圖分區
這個案例裡的圖的尺寸非常大,因此需要使用分散式的方式進行訓練和預測。原始圖被劃分為幾個相對較小的圖,以便能放入工作節點機器的(worker machine)記憶體。我們只對最近使用過 Uber 平臺的使用者的 x 跳子圖感興趣。併為這些最近的「種子使用者」隨機分配一個分區號(0 到 n)。每個種子使用者的 x 跳子圖也被放到到相同的分區中。一個使用者可能是多個分區的一部分,而不活躍的使用者可能不在任何分區中。每個分區都被對映到一臺訓練或預測工作節點機器。
我們擴充了 Cypher 語言,添加了一個分區子句來創建圖。下面的示例查詢將自動生成由分區列分割的多個圖。每個分區將包含種子使用者和他們的單跳鄰居(one-hop neighborhood)。

超級節點
圖生成過程的一個巨大挑戰是處理超級節點,超級節點是一個具有極高連線量的節點。我們分兩個階段對這些節點進行處理:
在創建關係表時,過濾具有高度連線的實體。例如,通過 1,000 個共享實體連線的兩個使用者將生成 10,00 個使用者 - 使用者關係。但是,我們只構建 1 條連線,而將連線數作為特性新增到節點上;在圖分區階段,有一些使用者在他們的子圖中具有非常大的關係數量。這增加了分區大小的差異,有些分區變得非常大。因此我們根據閾值限制這些使用者的每一跳的鄰居數量。這些異常情況的使用者就可以通過這些規則進行處理了。
訓練以及批次預測
資料管道和訓練管道如下圖所示。資料管道的第一步是從 Apache Hive 表中提取資料,並以包含節點和邊資訊的 Parquet 檔案匯入 HDFS。每個節點和邊都有時間戳進行版本控制。最新的節點和邊構成的圖將在給定日期的情況保留,並使用 Cypher 格式儲存在 HDFS 中。在使用 Apache Spark 運行引擎中的 Cypher 查詢語言送入模型之前,我們會先對圖進行分區。圖分區直接送入到 DGL 編寫的訓練和批次預測程式中。生成的評分會儲存在 Hive 中,用於後續任務和離線分析。

資料管道(頂行)和訓練管道(底行)用於學習欺詐評分,以提升後續欺詐檢測的表現。
未來發展方向
圖學習在學術界和工業界都受到了廣泛的關注,它提供了一種令人信服的欺詐檢測方法。雖然圖學習在檢測質量和相關性方面有了顯著的改進,但是還需要進一步的研究來提高系統的可擴展性和實時性。我們也正在探索一種更有效的方式來儲存更大的圖,並進行分散式訓練和實時預測。此外,由於司機 - 乘客圖是密集連線的,為了提高資訊傳遞的效率,我們將探索基於注意力的圖模型,這些模型會利用掩碼自注意力層,對鄰居中的不同節點賦予不同的重要性。例如,GAT 模型和能進一步關聯遙遠鄰居的 GAT 的擴展模型都和我們的場景相關。
相關文章
選自eng.uber作者:Xinyu Hu等機器之心編譯編輯:力元、陳萍近年來,隨著 Uber 在客戶中越來越受歡迎以及規模的不斷擴大,它也吸引了網際網路金融犯罪分子的目光。共謀是一種典型的
2021-06-03 21:43:12

6月2日晚,鴻蒙系統正式登場,Mate系列、P系列、MatePad平板等多款裝置已經陸續啟動升級。邁向萬物互聯從被吐槽「PPT系統」「安卓換皮」到如今正式亮相,鴻蒙系統一路走來都伴隨
2021-06-03 21:42:21
IT之家 6 月 3 日訊息 微信安全中心今晚釋出《視訊號直播常見違規內容概覽》,詳細介紹了平臺上進行直播過程的違規行為。這一概覽根據視訊號直播日常安全監管過程中實際發現
2021-06-03 21:42:06

媒體報道指特斯拉正計劃進入印度市場,希望在這個正迅速發展的全球最大汽車市場之一分羹,如此做的原因之一可能是因為它在中國和歐洲市場均受到打擊所致。特斯拉進入歐洲市場之
2021-06-03 21:24:06
我一直認為,給老使用者升級系統是一場釋出會最高光的時刻。特別是隨著昨天華為鴻蒙HarmonyOS的釋出,餘承東表示「明年上半年,一些老款華為手機也會升級HarmonyOS,包括Mate 9、Ma
2021-06-03 21:23:48

【科技犬】伴隨HarmonyOS正式釋出,華為5月19日釋出的顯示器新品華為MateView也迎來了全新的智慧聯接升級,其最與眾不同的功能—Desktop Mode隨之落地。作為華為旗艦直面屏顯示
2021-06-03 21:22:29