現在,給視訊人物「喂」一段音訊,他就能自己對口型了,就像這樣:00:07原聲其實是出自這裡:00:07這是一種利用音訊生成視訊人物口型的新方法,出自慕尼黑工業大學Wojciech Zielonka的
2021-06-15 15:08:55
現在,給視訊人物「喂」一段音訊,他就能自己對口型了,就像這樣:
原聲其實是出自這裡:
這是一種利用音訊生成視訊人物口型的新方法,出自慕尼黑工業大學Wojciech Zielonka的碩士論文。
用這種新方法對口型,只需2-3分鐘就能夠訓練目標角色,生成的視訊保留了目標角色的說話風格;
並且不受語音來源、人臉模型和表情的限制。
新方法與Neural Voice Puppetry、Wav2Lip、Wav2Lip GAN的生成效果,對比起來是這樣的:
 圖片
圖片在保持較低脣部誤差的同時,生成影象質量高於其他方法。
原理簡介
具體來說,作者提出了一個新的框架,它由音訊特徵提取、投影網路、變形網路、顏色網路、組成網路幾個部分組成。
 圖片
圖片首先,將輸入音訊轉換為MFCC(梅爾頻率倒譜系數),並進行特徵提取。
利用投影網路進行近似轉換,將提取的特徵嵌入到不同的低維空間。
為了順利生成視訊,研究人員還引入了一維卷積網路和一個衰減模組,以保持時間上的連貫性。
在變形網路中,作者使用了三維可變形人臉模型(3DMM),這是一種基於一組人臉形狀和紋理的統計模型,將人臉表示為固定的點數。
 圖片
圖片將3DMM的網格輸入變形網路,該網路能通過音訊訊號產生優化的3D形狀。
再將其柵格化傳遞給色彩網路,每個三維點經過位置編碼,並與音訊嵌入相關聯,最終通過色彩網路輸出影象。
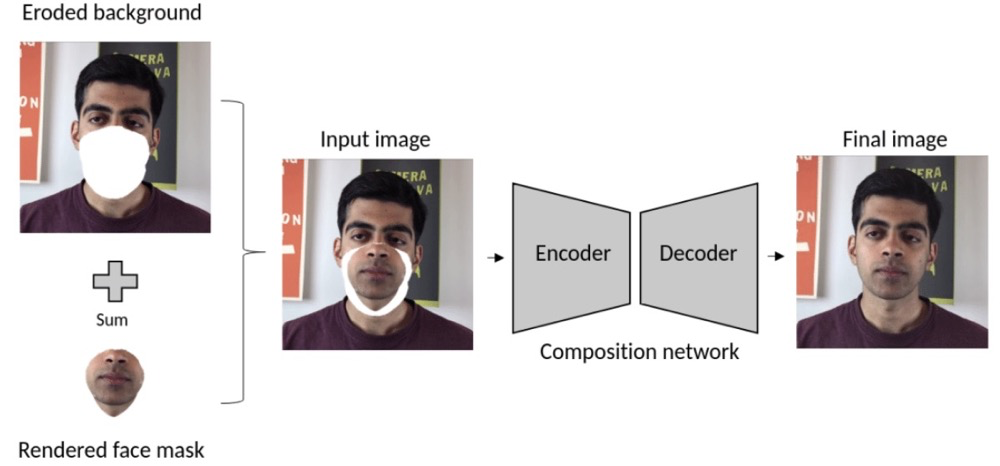
最後,用2D膨脹卷積網路建立的組成網路,將渲染的人臉被無縫地嵌入到背景中。
 圖片
圖片可以看到從3D形狀到最終合成輸出的效果:
 圖片
圖片這項研究採用了最小絕對值偏差(L1)和感知損失(VGG)這兩個損失函數的組合。
先利用L1損失網路找到粗略影象,然後在訓練過程中,通過VGG損失進行完善並學習細節。
效能如何?
研究人員使用資料集對模型進行了測試,資料集中共有6個人物。
 圖片
圖片其中,模型用於Krista和Obama時效果更好,生成影象與ground truth最為接近。
 圖片
圖片而Ayush的誤差較高,作者表示,這可能是受到訓練視訊質量的影響。
 圖片
圖片從左至右依次是原視訊、配音視訊、原聲視訊:
作者還對色彩網路的效能進行了評估,結果顯示,即使3D形狀在隨機幀之間沒有很大變化,色彩網路也能作出正確的預測。
 圖片
圖片論文中還給出了與其他方法的定量對比情況,整個資料集的影象質量誤差如下:
 圖片
圖片在影象質量的3個指標中,新方法都優於其他方法。
不過新方法也不是一直可靠,比如在合成時,也可能會產生位移誤差,出現雙下巴等。
 圖片
圖片此外,它還存在一定的侷限性。
由於3DMM並沒有明確地對牙齒建模,目前的方法是將兩個嘴脣封閉起來。因此,頂點的數量並沒有改變,特徵基數仍然成立。
擁有詳細的牙齒幾何形狀,可以更好地捕捉說話時的面部運動,當然這在很大程度上取決於人們的說話風格。
此外,一個更大的侷限是,在場景或演員變化時,就需要重新訓練模型,並且只支援英語音訊。
網友熱議
作者把效果視訊發在了Reddit上,引起了網友們的熱議。
 圖片
圖片不少網友發現,視訊人物的脣部動作,似乎效果不佳。
 圖片
圖片除了「美國」之外,他的口型看起來對不上。
 圖片
圖片更多的網友對於這項技術的應用,提出了質疑。
這與在奧巴馬靜音的視訊上播放音訊有何不同?
 圖片
圖片就像這位網友所說,類似這樣的人臉生成技術,很多都被用於造假,因此一直存在著倫理爭議。
網友們也為此感到擔憂:
有時我會想到這些技術是如何被濫用的,這讓我對未來感到有點難過。我們需要虛假視訊檢測器,不知道這場戰鬥還要走多遠。
 圖片
圖片擁有權利的同時,也被賦予了重大的責任!
 圖片
圖片如果這類應用盛行起來,人們也許不會相信視訊了。
 圖片
圖片不過也有網友提到:
好在,就目前來說,檢測比生成要要容易得多,效果也更好。
 圖片
圖片對於這項研究,作者表示,
它具有商業前景。比如,在未來,演員可以出售自己的(視訊)化身。僅需語音操縱,就能夠製作電影或遊戲,還可以使用根據文字生成的語音。
 圖片
圖片你希望這樣的技術用在電影和遊戲裡嗎?
相關文章
現在,給視訊人物「喂」一段音訊,他就能自己對口型了,就像這樣:00:07原聲其實是出自這裡:00:07這是一種利用音訊生成視訊人物口型的新方法,出自慕尼黑工業大學Wojciech Zielonka的
2021-06-15 15:08:55

《嚮往的生活》第五季自4月23日開播以來,收視率一直領跑全頻道同時段節目。桃花源裡漁樵耕讀的慢生活和返璞歸真的好風景讓觀眾感受到了久違的解壓和治癒,引發了大家廣泛的共
2021-06-15 15:07:07
除了已經發布的Xe LP低功耗架構、Xe HP/HPG主流遊戲架構,Intel這次重返獨立顯示卡市場,還準備了專門面向高效能運算的Xe HPC頂級架構,定位於超級計算機加速器,開發代號「Ponte V
2021-06-15 15:06:34

近年來,整合灶一路「高歌猛進」,成為廚電行業最火熱的品類之一。根據奧維雲網(AVC)推總資料顯示,2020年全國整合灶市場整體零售額為182.2億元,同比上漲13.9%;零售量238萬臺,同比上漲
2021-06-15 15:06:04

#降噪耳機#Sony 推出 WH-1000XM4 降噪耳機限量「靜謐白」新色Sony今日宣佈,將推出WH-1000XM4無線主動式降噪耳機的「靜謐白」限量新色款式,預計將於6/16上市。Sony表示,WH-1000
2021-06-15 14:47:58

2021上半年釋出了許多手機,但當我回看這些手機時,我發現有三款在我心中的只能算「圾皇」,壓根談不上所謂的「頂級旗艦」也不能稱之為價效比機型,不知道你是否認同?小米11 UItra為
2021-06-15 14:47:06