移動網際網路「早古」時期,普通人因為收入差距問題而無法做到人手一部智慧手機,從而導致數字鴻溝。同樣,在當前這個AI,也就是人工智慧扮演越來越關鍵作用的時代,企業也站在了類似
2021-06-17 15:29:30
移動網際網路「早古」時期,普通人因為收入差距問題而無法做到人手一部智慧手機,從而導致數字鴻溝。同樣,在當前這個AI,也就是人工智慧扮演越來越關鍵作用的時代,企業也站在了類似的抉擇交接線上——是否有足夠的實力或能力擁抱智慧化?而這個問題的成本,可就不是一個小小的智慧手機了。因缺少AI人才、技術積累或財力支援而難以靠自身力量完成AI基礎設施建設的企業,在智慧化轉型的過程中正將面臨這樣的智慧化鴻溝,能否破解,很可能會關乎新十年中它們的命運走向。
1 如何消除智慧化鴻溝?
要解決問題,就要先精確定位問題所在。
一方面,構建AI能力對於普通企業來說,IT基礎設施維護、AI框架搭建、訓練和推理、硬體和軟體、人才和鉅額算力成本等這些「夯地基」的事情需要從零做起,然而大部分企業,尤其是傳統行業企業並沒有相關經驗;另一方面,智慧化轉型又迫在眉睫,企業需要快速讓自己具備AI能力,才能趕上不斷變化的需求。

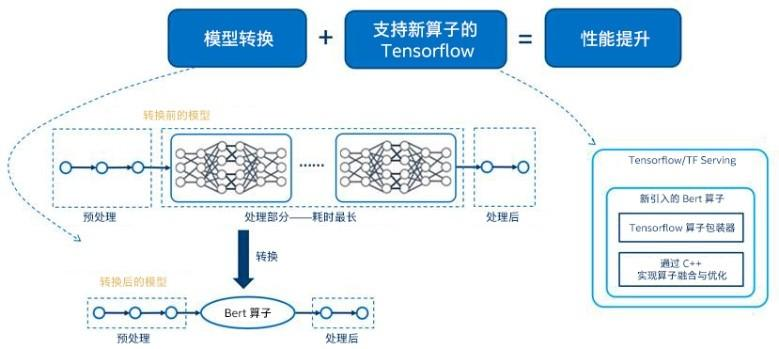
企業在AI應用開發和使用各階段可能遇到的挑戰,
雖然不全,但已足夠「挑戰」
包括那些有一定的AI人才、技術積累與創新能力,但仍不足以支撐自身智慧化轉型的企業在內,大家都在尋找一種功能全面、部署便捷且價效比高的法子,來幫助它們快速完成AI能力的構建和部署。
這就給了雲服務提供商大展身手的機會,通過輸出快捷、高效、實惠的AI雲服務,幫助條件和實力不足的企業快速部署和實踐AI應用,它們可以做到既惠人,又利已。
2 意外!CPU成AI雲服務熱門選擇
緊迫的需求,已經在過去數年催生了眾多針對AI的雲服務和產品,IaaS和PaaS級別的服務是主流,例如AIaaS (AI as a Service)、AI 線上服務、增強型 IaaS、企業級AI一體機,深度學習雲平臺等等,硬體搭配也是多種多樣,例如基於CPU、GPU、TPU、NPU、FPGA等等,都在為企業AI轉型提供包括基礎設施構建及優化、AI應用開發和部署,以及AI 模型訓練與推理效能優化在內的多種支援。
有趣的是,CPU作為通用處理器,在AI雲服務的搶眼程度,並不亞於專用的AI加速晶片。通過實際應用分析,我們不難發現,如果不是專注於AI演算法模型訓練和開發的企業,大多數企業使用AI時其實更偏推理型的應用。對他們來說,基於CPU平臺的雲服務,特別是集成了可加速AI應用的AVX-512技術和深度學習加速技術的英特爾至強平臺的AI雲服務,其實在很多應用場景中都足以應對實戰需求,且不論對於他們,還是雲服務提供商而言,部署都更快、更便捷,上手門檻也低。
就這樣,可能與大家的印象相悖,CPU成為了很多雲服務提供商輸出,以及企業採用AI雲服務時的熱門選擇,這使得以CPU為基礎設施的AI雲服務異軍突起。
3 用CPU做AI雲服務,整合AI加速是前提
如前文提到,基於CPU的雲服務要受歡迎,並不是僅僅做好通用計算任務就夠了,首先就要針對AI應用在硬體上整合特定的加速能力。

作為老牌CPU廠商的英特爾,早在2017年就於第一代至強可擴展處理器上匯入了可以加速浮點運算(涵蓋AI運算)的AVX-512技術;而後又在2019年推出的第二代至強可擴展處理器上集成了可以加速INT8的英特爾深度學習加速技術,專攻推理優化;2020年和今年,分別面向多路和單、雙路伺服器的第三代至強可擴展處理器依次亮相,後者靠INT8加速主攻推理,前者則通過同時支援INT8和BF16加速,兼顧了CPU上的AI訓練和推理任務。

2021年面向單路和雙路伺服器的全新第三代至強可擴展處理器的主要優勢,包括再次提升AI推理效能
CPU有了AI加速能力,用它來構建AI雲服務的根基就已奠定。但為了充分發揮出這些硬體AI加速能力,英特爾還同步提供了一系列開源AI軟體優化工具,包括基礎效能優化工具oneDNN,可幫助AI模型充分量化利用CPU加速能力、預置了大量預優化模型並能簡化它們在CPU平臺上部署操作的OpenVINO,以及可以在現有大資料平臺上開展深度學習應用,從而無縫對接大資料平臺與AI應用的Analytics Zoo等。英特爾還將oneDNN融入了TensorFlow、Pytorch等主流AI框架,將它們改造成面向英特爾架構優化的AI框架。
通過這些舉措,英特爾架構CPU平臺加速AI應用的軟硬兩種能力就有了「雙劍合璧」的效果。而英特爾和雲服務提供商合作伙伴的實踐,也正是基於此展開的。
4 CPU AI雲服務第一式,軟硬打包上手快
得益於英特爾提供的全面AI加速軟硬體組合,多數雲服務提供商無需做更多調整和優化,就可迅速打造出針對AI的基礎設施即服務或AI雲主機產品。簡單來說,就是將整合AI加速能力的至強可擴展平臺與我們提到的軟體工具,例如oneDNN或面向英特爾架構優化的AI框架軟硬打包,就可快速形成易於部署和擴展的AI雲主機映象。
國內有云服務提供商早在2017年就進行了類似的嘗試,通過使用英特爾優化軟體,它激活了至強平臺的AI加速潛能,並在部分應用場景實現了可與GPU相媲美的推理效能。
如果僅有效能優化還不夠,還需要更快的模型部署能力,那就可以像CDS首雲一樣匯入OpenVINO。它通過至強可擴展平臺、高效能 K8S 容器平臺和OpenVINO Model Server這三者的組合大幅簡化了AI模型的部署、維護和擴展。效能實測結果也表明,OpenVINO不僅在使用者併發接入能力上優於首雲此前採用的AI框架,在推理應用的時延等關鍵效能指標上也有良好表現。

CDS首雲AI雲服務方案架構
5 CPU AI雲服務第二式,深度優化收益多
僅僅是匯入英特爾已經就緒的AI軟硬體組合,就已能輸出令人滿足的AI雲服務了,那麼如果是和英特爾在AI雲服務的演算法及模型上進行更深入的優化,又會有什麼驚喜呢?像阿里雲這樣的頭部雲服務提供商就通過實戰給出了答案。
以阿里云為例,其機器學習平臺PAI在與英特爾的合作中,利用了第三代英特爾至強可擴展處理器支援的bfloat16加速,來主攻PAI之上BERT效能的調優,具體來說就是以經過優化的Float32 Bert模型為基準,利用BF16加速能力優化了該模型的MatMul運算元,以降低延遲。測試結果表明:與優化後的FP32 Bert模型相比,至強平臺BF16加速能力能在不降低準確率的情況下,將BERT模型推理效能提升達1.83倍。

阿里雲PAI BERT 模型優化方案
6 CPU AI雲服務第三式 紮根框架打根基
如果說從提供軟硬協同的基礎平臺到定向深度優化演算法,算是AI雲服務在優化程度上的邁進,或者說雲服務提供商與英特爾在AI雲服務構建和優化上的深化合作的話,那麼如果有云服務提供商能在深度學習框架這個AI基石上與英特爾開展合作,那是不是會更具意義呢?
為這個問題輸出答案的是百度,它的開源深度學習平臺「飛槳」先後結合第二代和第三代至強可擴展處理器在計算、記憶體、架構和通訊等多層面進行了基礎性的優化。其結果也是普惠性的——優化後的飛槳框架能夠充分調動深度學習加速技術,可將眾多AI模型,特別是影象分類、語音識別、語音翻譯、物件檢測類的模型從FP32瘦身到INT8,在不影響準確度的情況下,大幅提升它們的推理速度。

英特爾深度學習加速技術可通過1條指令執行8位乘法和32位累加,INT8 OP理論算力峰值增益為FP32 OP的4倍
例如在影象分類模型ResNet50的測試中,飛槳搭配英特爾今年釋出的全新第三代至強可擴展處理器對其進行INT8量化後,其推理吞吐量可達FP32的3.56倍之多。
如此效能增幅,再加上CPU易於獲取、利用和開發部署的優勢,讓飛槳的開發者們可藉助AI框架層面的優化,更加快速、便捷地創建自己可用CPU加速的深度學習應用。而為了給企業開發者們提供更多便利,百度還推出了EasyDL和BML(Baidu Machine Learning)全功能AI開發平臺,通過飛槳基於全新第三代至強可擴展處理器的優化加速,來為企業提供一站式AI開發服務。

百度飛槳開源深度學習平臺與飛槳企業版
7 展望未來,跨越智慧化鴻溝不僅靠算力
前文CDS首雲、阿里雲和百度的例項,可以說是充分反映了用CPU做AI雲服務的現狀,而這些雲服務也正是為當前希望跨越智慧化鴻溝的企業設計的。當然,它們也會持續演進,比如說隨著未來AI技術的進一步發展,特別是大資料與AI融合帶來的新需求,不論是用CPU還是專用加速器,不論是企業自建AI基礎設施和應用,還是雲服務提供商輸出的AI雲服務,都會在資料儲存而非算力上面臨越來越多的挑戰。
畢竟,算力、演算法和資料是並駕齊驅的「三駕馬車」,隨著資料規模進一步暴增,資料儲存也將對AI的部署和應用帶來更多挑戰。
好訊息是,國內的雲服務提供商也早已和英特爾就此展開了前瞻創新,例如百度智慧雲早在2019年就推出了ABC(AI、Big Data、Cloud)高效能物件儲存解決方案,能利用英特爾傲騰固態盤的高效能、低時延和高穩定來滿足AI訓練對資料的高併發迭代吞吐需求。
值得一提的是,英特爾在今年釋出全新第三代至強可擴展處理器時,也帶來了與其搭檔的英特爾傲騰持久記憶體200系列和傲騰固態盤P5800X。

與全新第三代至強可擴展處理器搭配使用的傲騰持久記憶體和固態盤新品
相信未來會有更多專攻AI應用場景的儲存系統匯入這些新品,把更多資料存放在更靠近CPU或其他加速器的地方,從資料就緒或「供給」層面提升AI推理和訓練的效能。而提供這些AI優化型儲存系統或服務的,多數也很可能是技術實力雄厚的雲服務提供商們,這樣一來,使用者就不用擔心在應對智慧化鴻溝時再遇到大資料和AI對接的難題了。
相關文章
移動網際網路「早古」時期,普通人因為收入差距問題而無法做到人手一部智慧手機,從而導致數字鴻溝。同樣,在當前這個AI,也就是人工智慧扮演越來越關鍵作用的時代,企業也站在了類似
2021-06-17 15:29:30
大家身邊有沒有每年都換手機的人,你以為是他們「豪」,其實並不是。他們只是用買一部高階機的價格購買了好幾款千元機罷了,使用起來依舊是爽歪歪。我們需要知道千元機和高階機的
2021-06-17 15:28:55

4月15日,極氪001正式上市,共推出三款車型,分別為長續航雙電機WE版、超長續航單電機WE版以及超長續航雙電機YOU版,售價區間為28.1-36萬元。該車的火爆情況也是超出了逾期,而今,只過
2021-06-17 15:28:05

隨著愈來愈多關於Windows 11 系統的訊息爆出,大部分Windows 系統的使用者都期待可以免費升級新的版本。根據外媒《XDA Developers》訊息稱,Windows 11 獲得了Windows 7與8.1的
2021-06-17 15:08:27

今天給大家分享一下如何從idea提交程式碼到gitee上面。1.先在gitee上創建倉庫gitee地址直接官網下載2.填寫相應的資訊3.下載git直接next一站式安裝4.滑鼠右鍵點選 Git Bash
2021-06-17 15:08:07

說起日本在半導體材料方面的成績,相信大家都是清楚的。目前日本壟斷了全球70%左右的半導體材料,比如光刻膠、矽晶圓、特氣、靶材等等。日本為何在半導體材料方面這麼強大,這是
2021-06-17 15:07:53