來源:Python爬蟲與資料探勘作者:Python進階者前言上次兩篇基本學完的Django ORM各種操作,怎麼查,各種查。感興趣的小夥伴可以戳這兩篇文章學習下,一篇文章帶你瞭解Django ORM操作
2021-06-18 15:52:14
來源:Python爬蟲與資料探勘
作者:Python進階者
前言
上次兩篇基本學完的Django ORM各種操作,怎麼查,各種查。感興趣的小夥伴可以戳這兩篇文章學習下,一篇文章帶你瞭解Django ORM操作(進階篇)、一篇文章帶你瞭解Django ORM操作(基礎篇)。
但是還是遺留了一些技能。,再來瞅瞅吧!
查詢
聚合操作
聚合操作,不要被名字嚇到了,通常用在篩選完一些資料之後,求一下平均值了,什麼的。
例如:求所有書的總價格和平均價格
原生sql
SELECTSUM(price) AS"所有書總價格", avg(price) AS"所有書平均價格"FROMweb_book;
執行結果

ORM
price=models.Book.objects.all().aggregate(Sum("price"),Avg("price"), )print(price)
執行結果

可以發現和上面是一樣的,但是會發現列名是預設是欄位__聚合函數名。
原生sql是可以指定顯示的列名的,同樣,ORM也可以。
程式碼
# 需要匯入的包from django.db.models import Avg,Sumprice = models.Book.objects.all().aggregate(所有書總價格=Sum("price"), 所有書平均價格=Avg("price"), )print(price)
執行結果

注:price的類型直接就是dict,所以,在這是不能檢視原生sql的。
但是上述ORM對應的原生SQL確實如上,所以那樣理解就行了。
分組操作
分組操作,就是將某一列,相同的值進行壓縮,然後就可以得出壓縮值的數量。
如果壓縮的是外來鍵,還可以取出外來鍵的詳細資訊。
示例:查詢出每個出版社出版的數量。
通過研究表結構發現,每出版的書,都在book表中記錄,並且每本書會外來鍵一個出版社id。

如果我們能對出版社id進行壓縮,然後再求出壓縮出版社id裡面對應的數量。
嘖嘖,這不就出來了嗎?
程式碼
from django.db.models import Countret = models.Book.objects.values("publish_id").annotate(publish_count=Count("publish_id"))print(ret)
執行結果

原生sql
SELECT`web_book`.`publish_id`,COUNT(`web_book`.`publish_id`)AS`publish_count`FROM`web_book`GROUPBY`web_book`.`publish_id`;
ORM分組和原生SQL對應圖
這一塊,我記得當初我迷茫了一段時間,主要是不知道如何和原生SQL對應上,根據多次測試經驗,對應圖如下。

分組獲取外來鍵欄位資訊
上述確實可以通過分組實現了功能。
但是上述只能獲取出版社id,並不能獲取出版社名啥的,但是如何獲取壓縮外來鍵欄位詳細資訊呢?
程式碼
ret = models.Book.objects.values("publish_id").annotate(publish_count=Count("publish_id")).values("publish__title","publish__phone","publish_count")print(ret)
執行結果

注:分組(annotate)後面跟的values。
裡面只能寫外來鍵欄位的列和annotate裡面的列,不能寫其他。
如果分組分的不是外來鍵欄位,那就不能再跟values!
分組再篩選
分組再篩選本質就是原生sql的group by .. having,將壓縮完的資料在進行條件判斷。
但是對壓縮的資料進行判斷只能通過having。
示例:查詢出版社出版的書大於2本的資料。
程式碼
ret=models.Book.objects.values("publish_id") .annotate(publish_count=Count("publish_id")) .filter(publish_count__gt=2)print(ret)
執行結果

F查詢
有時候,我們可能有這樣的需求,就是兩個列之間進行比較。
比如經典問題,一個商品,找到收藏數大於銷量的商品等之類的兩列進行比較的需求。
示例:查詢book表,評論數小於收藏數的資料。
程式碼
fromdjango.db.modelsimportFbook= models.Book.objects.filter(comment_num__lt=F("collect_num"))print(book)
實際結果

執行結果

F物件還支援加減乘除後的比較
示例:評論數小於兩倍收藏數的資料。
程式碼
可是*,也可以是-,+,÷
from django.db.models import Fbook = models.Book.objects.filter(comment_num__lt=F("collect_num")*2)print(book)
執行結果

F物件還適用於更新
程式碼
models.Book.objects.all().update(price=F("price")+30)
Q查詢
通常情況下,我們使用的filter(條件1,條件2,...),執行的都是and查詢。
但是通常一些時候,我們需要執行or查詢。
比如book表,查詢title=<<大明帝國>> or title=<<安史之亂>>的。
這時候,如果使用Django ORM,就只能使用Q查詢構建條件。
程式碼
from django.db.models import Qbooks = models.Book.objects.filter(Q(title="<<大明帝國>>") | Q(title="<<安史之亂>>"))print(books)
執行結果

注:|是or的意思,&是and的意思。
所以,如果將上述的|換成&,filter(條件1,條件2,...)一個意思,還是and。
Q查詢之~
~相當於not。
示例:查詢title = "<<大明帝國>>" or title != "<<安史之亂>>"。
程式碼
from django.db.models import Qbooks = models.Book.objects.filter(Q(title="<<大明帝國>>") | ~Q(title="<<安史之亂>>"))print(books)
執行結果

Q查詢和and混合查詢
Q查詢和and查詢同時出現,Q查詢必須在其他查詢之前。
示例:查詢title = "<<大明帝國>>" or title != "<<安史之亂>>" 並且publish_id=1的。
程式碼
from django.db.models import Qbooks = models.Book.objects.filter(Q(title="<<大明帝國>>") | ~Q(title="<<安史之亂>>"),publish_id=1)print(books)
執行結果

動態構造Q查詢
一些時候,我們可能並不太確定有什麼條件。
可能是動態傳的,傳過來多少,就拼接多少。
Q查詢,就能做到這個,在做動態Q查詢時,動態Q不僅支援or,還支援and。
示例:查詢publish_id=1或者title模糊=大明 的書。
程式碼
q = Q()# 查詢方式,or還是andq.connector = "or"# or,and# publish_id=1q.children.append(("publish_id", "1"))# title__contains="大明"q.children.append(("title__contains", "大明"))books = models.Book.objects.filter(q)print(books)
執行結果

增
上面說了那麼多,終於算是大概說完了,來簡單看一下怎麼新增一條資料吧。
示例:新增一本書
程式碼
方式一,通過objects.create。這種方式用的最多。models.Book.objects.create(title="<<人類簡史2>>", price=66.66, PublishDate="2020-01-02", comment_num=23, collect_num=12, # 外來鍵欄位 django models對應的mysql 為 欄位_id publish_id=1, # publish欄位需要是一個 Publish 物件 # publish=models.Publish.objects.filter(id=1))方式二,通過model物件.save()。book_obj = models.Book(title="<<人類簡史2>>", price=66.66, PublishDate="2020-01-02", comment_num=23, collect_num=12, # 外來鍵欄位 django models對應的mysql 為 欄位_id publish_id=1, )book_obj.save()方式三,通過字典方式。可能有的時候,我們正好將傳過來的參數構造成了一個字典,那就太好了,不需要再一個個取。c_dict = {"title":"<<tcp程式設計從入門到精通2>>", "price":88.1, "PublishDate":"2020-01-03", "comment_num":13, "collect_num":78, "publish_id":1,}models.Book.objects.create(**c_dict)更新
注:update只能跟在在filter之後。
示例:將title="<<大明帝國>>"的資料修改為title="<<大明帝國666>>"。
程式碼
models.Book.objects.filter(title="<<大明帝國>>").update(title="<<大明帝國666>>")
filter可能篩選到的是多個值,一定要注意
刪除
delete只能跟在filter之後。
示例:刪除title=<<大明帝國666>>的資料。
models.Book.objects.filter(title="<<大明帝國666>>").delete()
總結
好了各位,到此為止,基本上,Django ORM操作基本完畢,至少80%的知識都覆蓋完畢。
本篇主要補充的是一些高階操作,例如聚合操作,分組操作,分組再篩選操作,F查詢和Q查詢。
如何動態構造Q查詢。
相對來說,Django還是自由度比價高的,而且寫起來確實比較省心。
如果在操作過程中有任何問題,記得下面留言,我們看到會第一時間解決問題。

相關文章

來源:Python爬蟲與資料探勘作者:Python進階者前言上次兩篇基本學完的Django ORM各種操作,怎麼查,各種查。感興趣的小夥伴可以戳這兩篇文章學習下,一篇文章帶你瞭解Django ORM操作
2021-06-18 15:52:14
機器之心報道編輯:陳萍這是一個用 Rust 編寫的機器學習框架,與 PyTorch 類似,現已實現最常見的層元件(dense 層、dropout 層等),速度堪比 PyTorch。Rust 作為一門系統程式語言,專注
2021-06-18 15:52:05

夢晨 發自 凹非寺量子位 報道 | 公眾號 QbitAIAlphaGo在圍棋界大殺四方時就有人不服:有本事讓AI鬥地主試試?試試就試試。快手團隊開發的鬥地主AI命名為DouZero,意思是像AlphaZe
2021-06-18 15:51:48
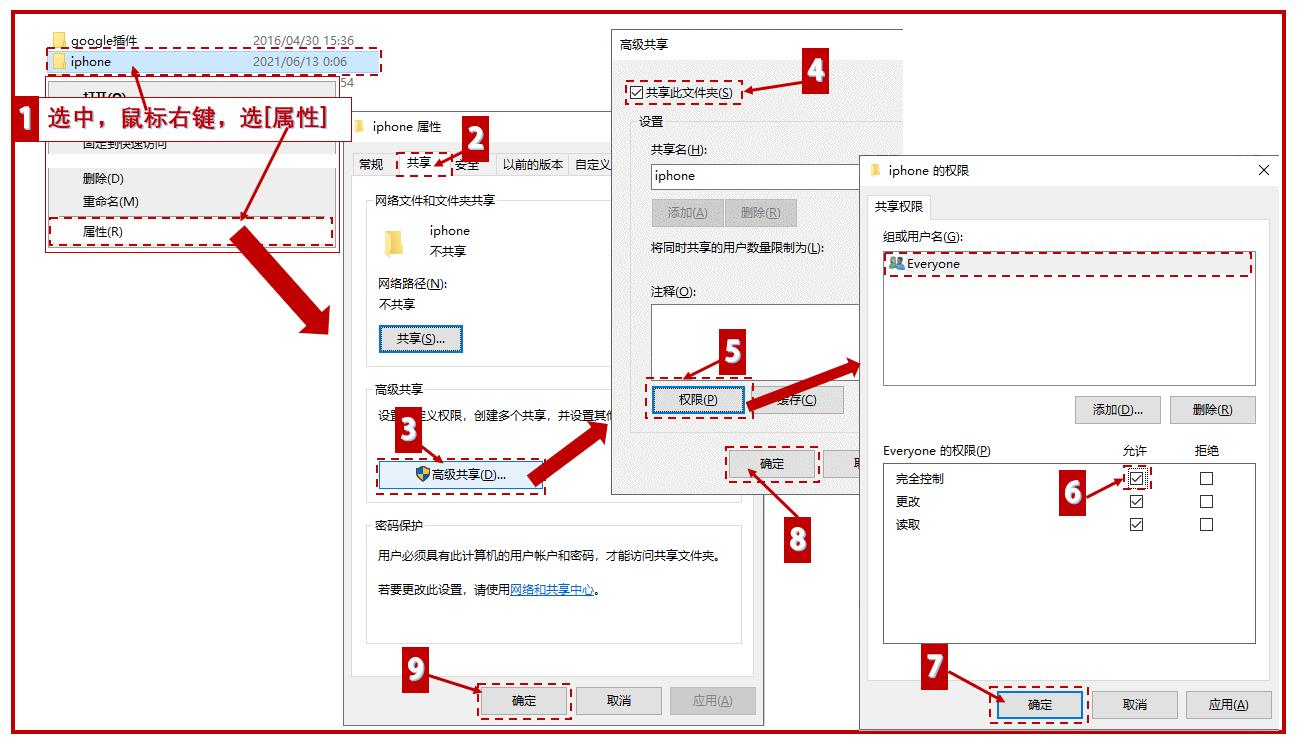
大家好,日漸氣溫升,遇事莫強掙,人生多浮沉,陪伴有廖晨。你是不是也覺得, iphone手機裡的照片和視訊匯入電腦時,特別麻煩?有一次將資料線和電腦連結好,卻無法正常匯出圖片和視訊,後來
2021-06-18 15:51:35

【TechWeb】6月18日訊息,近日全志科技在投資者關係活動上表示,由於產能供應緊張,代工成本會提升,公司已根據經營需要及時適當調節了價格。據悉全志科技主營業務為系統級超大規模
2021-06-18 15:50:58

又是一年畢業季,想必大家最近也經常在朋友圈見學弟學妹曬畢業照。每年的這個時候,筆者微信也總能收到一堆關於選購產品的私信:「有什麼推薦的筆記本?」「A和B筆記本哪個更值得選
2021-06-18 15:50:37