處理器的虛擬記憶體子系統為每個程序實現了虛擬地址空間。這讓每個程序認為它在系統中是獨立的。虛擬記憶體的優點列表別的地方描述的非常詳細,所以這裡就不重複了。本節集中
2021-06-21 09:14:49
處理器的虛擬記憶體子系統為每個程序實現了虛擬地址空間。這讓每個程序認為它在系統中是獨立的。虛擬記憶體的優點列表別的地方描述的非常詳細,所以這裡就不重複了。本節集中在虛擬記憶體的實際的實現細節,和相關的成本。
當代計算機程式以經大到記憶體無法容納,而且還需要支援多個程式運行。
20世紀60年代所採用的方法是:把程式分割成許多片段,稱為覆蓋。
在程式運行的時候,需要那個片段或者模組,由作業系統動態的換入換出至記憶體。那麼分割就需要程式設計師去操作了,所以呀,操作難度極大,很少有程式設計師擅長這項技術。這個時候虛擬記憶體應運而生。
虛擬記憶體,使得每個程式都擁有自己的記憶體地址,這個空間被分割成多個快,每一塊稱之為一頁或者頁面.每一頁有連續的地址範圍,這些頁被對映到實體記憶體。 並不是整個程式都在記憶體中,程式才能夠運行。程式引用到一部分在實體記憶體中的地址空間時,由硬體立即執行對映。當程式應用的頁面不在實體記憶體中時,由作業系統負責把缺失的部分裝入實體記憶體並重新執行失敗的指令。簡而言之,就是你用那一塊頁面,就調那一塊。因為程式是一步步執行的,只要能滿足現階段就ok.
為什麼說,虛擬記憶體適合多道程式設計呢,在我們讀取其他頁面的時候,cpu就閒下來了,這時候就可以讓cpu去執行另外的一個程序,提高了cpu的利用率。
3.1分頁
虛擬記憶體,讓每個程式都有了自己的(虛擬)地址空間,那麼虛擬的空間肯定會大於真是的物理空間,那麼他就肯定需要一個機制去對映和管理,完成虛擬-----> 物理 的對映。
因為程式執行需要載入到記憶體上,那麼虛擬記憶體又是在幹什麼呢?他類似於在磁碟上給你一個空間,給他們標記上地址編碼,等我們需要的時候,能夠以最快的速度找他程式的頁面,並載入其進入記憶體。
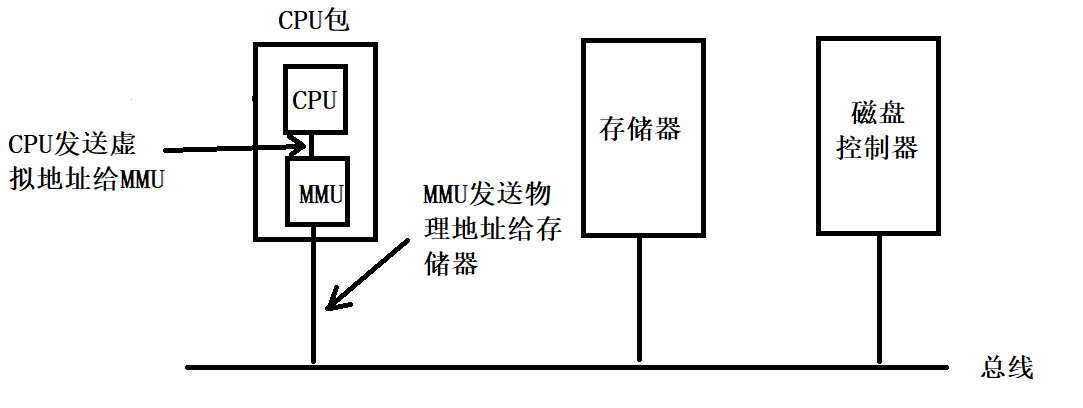
這樣呢,就出現了一個機制叫 記憶體管理單元(Memory Management Unit ,MMU),他就負責怎麼將虛擬記憶體轉換成實體記憶體。

CPU不會直接將虛擬記憶體傳送給地址匯流排,而是將其先發送給MMU,經過MMU的對映之後,在傳輸到地址匯流排。

虛擬地址按固定大小劃分稱為頁面的若干單元,實體記憶體對應的單元稱為頁框。
從64k程式虛擬地址空間到32k的實體地址空間,虛擬記憶體空間,還有一位用來標誌是否在記憶體中,或者說是是否建立對映關係。當訪問的頁面不在記憶體中時,則產生缺頁中斷,作業系統建立對映(或者替換一個頁面建立對映)。
3.2頁表
虛擬地址到實體地址的對映:
虛擬地址被分成虛擬頁號(高位部分)和偏移量(低位部分)兩個部分。

通過上述機制,我們就可以實現虛擬程式地址,到實體地址的轉化。
虛擬記憶體本質上是一個新的抽象概念—地址空間,是對物理空間的一個抽象,解放實體記憶體在使用過程中,一些問題。
虛擬記憶體MMU的實現從某種程度上講還是對基址寄存器與界限寄存器的一種綜合實現。
3.3 加速分頁過程
上述我們看到的分頁,但是每一次的抽象都會帶來效率上的各種問題。
分頁我們就必須保證:
1.虛擬地址到實體地址的對映必須快
2.如果虛擬地址很大,頁表也會很大
實體記憶體是有限的,在對映過程中,我們不僅僅是要查詢,產生缺頁中斷,我們還要替換,甚至當記憶體資料發生改變的時候,我們還需要將資料寫回磁碟。就查詢而言,即使是小的程式,執行機器語言查詢指令地址和資料地址也數不勝數呀,那麼這些問題,我們需要怎麼解決呢?
轉換檢測緩衝區(TLB)
因為大多數的程式總是對少量的頁面進行多次訪問,那麼,也只有很少的頁表會被反覆的讀取。
轉換檢測緩衝區,是一個直接將虛擬地址對映成實體地址的硬體裝置。
它設計在記憶體管理單元之中,一般大小不超過64個。它的作用和其他的緩衝區一樣,當程式運行的時候,它會記錄最近最常使用的頁面資訊,當一個虛擬地址放入MMU中時,會先從TLB匹配虛擬頁號,如果存在就直接呼叫;如果不存在,再去訪問頁表,進行替換。
現在的機器的頁面管理大部分都是由軟體管理的,這樣做為cpu晶片的快取記憶體以及其他騰出大量空間。
為了減少TLB失效,計算機預先裝載程式,也會在記憶體中維護一個固定位置的TLB頁表的軟體告訴快取。
這裡說一下TLB時效:
軟失效:訪問頁面在記憶體中,不在TLB中。
硬失效:訪問頁面不在記憶體中,需要磁碟取出。
3.4針對大記憶體的頁表
引入TLB,加速虛擬記憶體地址到實體地址的轉化。但是,問題又來了特別大虛擬空間時,頁表會特別大,全部載入到記憶體中勢必會浪費很大一部分空間,這時應該怎麼處理呢。
多級頁表

**引用多級頁表可以避免把把全部的頁表一直儲存在記憶體中。**特別時那些不用的頁表,就更不應該保留了。
如上圖,在左邊時頂級頁表,他有1024個表項,對應於1024PT1域。當一個虛擬地址被送到MMU時,MMU首先提取到PT1,在頂級頁表中找到二級頁表的索引,在去二級頁表中,找到PT2,加上偏移位Offset,那麼就可以找到對應的頁面了。
當然,大家看到二級頁表,肯定就會有三級、四級等更多級,級別越多,靈活性也會增大,複雜度也會增大。
倒排表
現在的計算機基本都是x64位的。如果現在的地址空間264位元組,頁面大小4KB,我們需要252個表項的頁表。如果一個表項8個位元組,呢麼整個頁表就會超過3000萬GB。僅僅為頁表消耗,這麼多多的空間可不是個好主意。
解決方案就是倒排頁表。
先介紹一下倒排表,當你開啟《現代作業系統》這本書,看到的目錄一樣,你可以通過目錄去找到對應的頁面,他和目錄不同的是,他沒有序號,也就是無序的。也就是說當你想找記憶體管理是,你只能一個一個遍歷目錄 找到對應的頁框(*)。
這裡補充一下頁和頁框的區別:
一頁是指一系列的線性地址和包含的資料。 頁框是*記憶體*中的實際儲存區域。 一般情況下,頁和頁框是一樣大小的。 頁只是一組資料塊,可以存放在實際儲存區域。
我感覺還是沒有講清楚,磁碟中存在4kB一頁資料,我們要將一頁資料放在一個頁框中。
當程序n,訪問頁面p時,我們需要去倒排表中,遍歷尋找對應的頁框。每次遍歷倒排表,無疑時非常費時的工作。那麼我們可能會想到TLB,來個這個不就好了嗎,沒有問題,但是TLB會失效,當失效時,我們還是需要去遍歷整個倒排表。
先輩們,給出了散列表。

通過虛擬地址來雜湊,當前所有在記憶體中的具有相同雜湊值的虛擬頁面被連結在一起。如果散列表中的索引數和實體記憶體頁面數目相同,那麼散列表只有一個表項,大大提高了對映速度。一旦頁框號被找到,我們就將其(虛擬頁號,物理頁框號)對就會加入TLB中,雜湊提高查詢速度,TBL提供快取,大大提高了效率。
相關文章
處理器的虛擬記憶體子系統為每個程序實現了虛擬地址空間。這讓每個程序認為它在系統中是獨立的。虛擬記憶體的優點列表別的地方描述的非常詳細,所以這裡就不重複了。本節集中
2021-06-21 09:14:49

前言:我是一個需要持續記錄會議紀要的文職人員,之前一直使用的是手機錄音。每一次開啟手機錄音整理檔案的時候,都需要重新聽錄音,還需要篩選有用的資訊,將它們記錄在冊,再通過電腦
2021-06-21 08:33:03

【電動狗】6月20日,賽力斯華為智選SF5變身父親節禮物亮相天津站交車儀式。華為官方稱之為「華為史上最大開箱」,讓交車的儀式感瞬間拉滿。賽力斯華為智選SF5於今年4月20日釋出
2021-06-21 08:32:47

由於眾所周知的原因,華為P50系列上半年都快要過去了還沒有釋出,僅僅是在釋出會上做了一個預告。所以外界不少人擔心今年下半年的華為Mate 50系列還會不會有。 不過在最近,有訊
2021-06-21 08:31:40

像摩托羅拉 RAZR 這樣的翻蓋手機曾一度統治世界。它們時尚、小巧,輕彈手腕即可結束通話電話,這點簡直就是是有史以來最令人滿意的事情之一。然而,對更大螢幕的需求最終扼殺了翻
2021-06-21 08:30:32

談到賣東西,相信不少人都聽過把梳子賣給和尚的故事。不過沒有仔細瞭解過這個故事的人,基本都會感嘆推銷員「憑空捏造出不存在的需求」的本領。可實際上這故事的重點不是賣別人
2021-06-21 08:30:03