導讀與傳統關係型資料庫相比,分散式資料庫系統具有多叢集、多節點、高併發等特性,這就需要分散式資料庫的 SQL 引擎能夠在滿足使用者常規的 SQL 請求以外,提供多叢集、多節點協
2021-06-22 11:05:17
導讀
與傳統關係型資料庫相比,分散式資料庫系統具有多叢集、多節點、高併發等特性,這就需要分散式資料庫的 SQL 引擎能夠在滿足使用者常規的 SQL 請求以外,提供多叢集、多節點協同計算的能力,從而提高查詢效率。本文將介紹分散式資料庫 ZNBase 的 SQL 引擎架構特點,以及其中各大服務元件的技術原理與工作流程。
分散式資料庫架構
目前業界最流行的分散式資料庫主要分為兩種架構。一種是以 Google Spanner 為代表的 Shared nothing 架構,另一種是以 AWS Auraro 為代表的計算/儲存分離架構。
Spanner 是 shared nothing 的架構,內部維護了自動分片、分散式事務、彈性擴展能力,資料儲存還是需要 sharding,plan 計算也需要涉及多臺機器,也就涉及了分散式計算和分散式事務。
Auraro 主要思想是計算和儲存分離架構,使用共享儲存技術,這樣就提高了容災和總容量的擴展。但是在協議層,只要是不涉及到儲存的部分,本質還是單機例項的 SQL 引擎,不涉及分散式儲存和分散式計算,這樣就和傳統資料庫相容性非常高。
浪潮云溪 NewSQL 資料庫 ZNBase 完美地繼承了 Spanner 的設計理念,實現了基於對等架構的分散式 SQL 引擎。
ZNBase 的 SQL 引擎
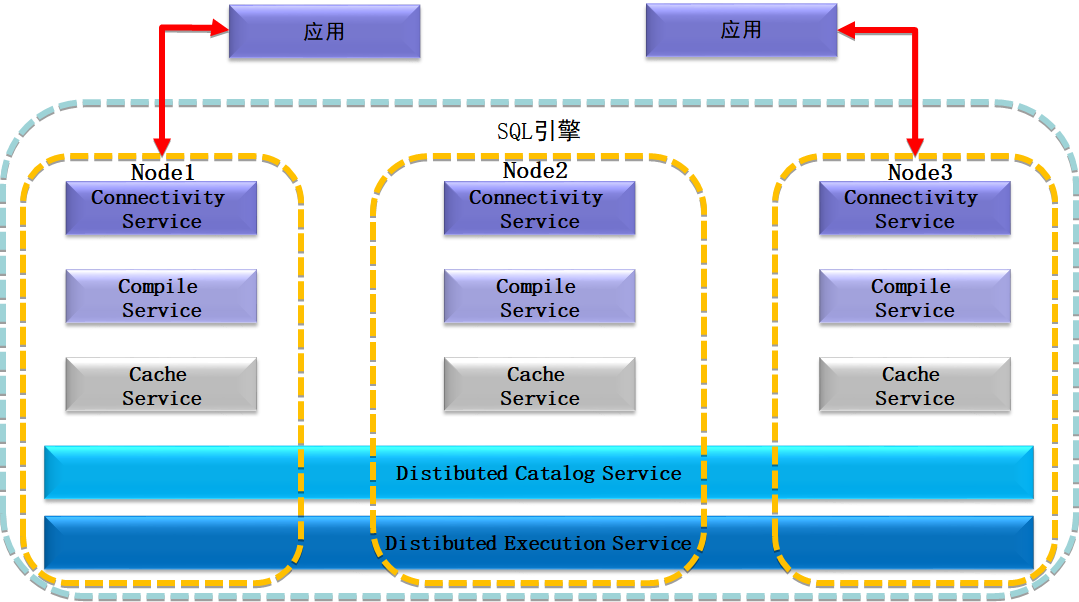
ZNBase 的 SQL 引擎在傳統的 SQL 引擎基礎上,引入了分散式的概念,通過多個叢集節點協同計算更高效的執行使用者 SQL 查詢,總體架構圖如下:

SQL 引擎靜態結構,包含五大服務
叢集中每個節點 node 都獨有連線服務(Connectivity Service)、編譯服務(Compile Service) 和快取服務(Cache Service)三大服務,可以完成使用者的 SQL 查詢執行的前端準備工作。
同時,所有節點又共同組成了分散式的目錄服務(Distibuted Catalog Service)和分散式的執行服務(Distibuted Execute Service),通過這兩個服務完成了多個 node 節點的協同執行,提高了分散式 SQL 引擎的執行效能。最終將結構化資料,轉化為底層儲存可識別的 KV 編碼對,通過 Batch 批處理髮送到事務層進行處理。

SQL 引擎執行流程
下文將對這五大服務進行展開介紹。
1.連線服務 Connectivity Service
分散式資料庫 ZNBase 採用的是對等架構,叢集中的任意節點都可以作為接入節點。同時,ZNBase 支援 PostgreSQL 協議,SQL 查詢可以通過各種支援 PostgreSQL 協議的驅動傳送到叢集。
連線服務流程如下:
使用者通過後臺守護程序進行連線器管理,為每個客戶端構建新的 Executor。
當用戶從客戶端發起指令後,從客戶端接收和解包流。
執行完畢後,將操作結果打包返回給客戶端。
使用者的每一次操作,都被認為是一個單獨的事務操作。
2.分散式目錄服務 Dist Catalog Service
ZNBase 的 Dist Catalog Service 不僅實現了傳統關係資料庫的 schema metadata,包含了常用的庫、表、列、模式等資料庫元資料,而且實現了元資料資訊的高可用,以及分散式訪問。元資料採用多副本儲存、分散式儲存,保證少於一半資料不可用的情況下,元資料資訊仍然可用。而且每個對等節點在啟動時會直接記憶體化元資料路由表的第一級 Root Meta Range 資料,保證任意節點都能訪問到需要的元資料資訊。
Catalog 資訊發生變化時,首先會更新到元資料儲存的寫入節點,通過 Raft 協議同步到多副本。同時使得各個節點的 Catalog 快取失效,在使用時進行非同步的更新,保證各節點資料的一致性。
3.編譯服務 Compile Service
ZNBase 的編譯服務包括了 SQL 前端和 SQL 中端功能,SQL 前端實現了傳統資料庫的 Scanner、Parser、SQL 語法、SQL 語義以及資料庫物件和許可權校驗的處理,生成了 AST(抽象語法樹)。
SQL 中端實現了資料庫的優化器的功能。優化器負責給執行引擎提供輸入,它接收來自 SQL 前端解析好的 AST 樹,然後需要從所有可能的計劃中選擇代價最優的計劃提供給執行引擎。
ZNBase 的優化器是基於 Cascades 論文實現的搜尋框架。從資料庫的發展歷程來看,基於 Cascades 的搜尋框架已經成為了業界標準,包括商業資料庫 SQL Server 以及開源資料庫 GP/ORCA 都採用 Cascades 實現。編譯服務的整體架構如下:

SQL 引擎編譯服務結構圖
如上圖所示,Client 端輸入的 SQL 語句通過 go-yacc 層的詞法、語法、語意義解析為 AST 語法樹,經過 Memo construction 轉換為 CBO 初始的 Memo 樹。Memo 由一些列等價的 group 組成,每個 group 表示一個邏輯等價表示式集合,Memo 本身是樹狀結構化的,可以代表查詢語句,但是又不包含大量的元資料資訊,可以被快取以提高執行效率,這點在 Cache Service 中會給出解析。構造好的 Memo 直接應用於基本的 RBO 轉換。之後,Memo 資料根據統計資訊經過 CBO 優化(等價發掘和最優化Cost)選擇轉換為最優路徑的計劃。
RBO 根據指定的優先順序規則,對指定的表進行執行計劃的選擇。比如在規則中:索引的優先順序大於全表掃描。
當某些 SQL 語句的寫法並不利於快速從儲存中查詢資料的場景下,RBO 會對其進行相應轉化,例:
SELECT * FROM t1 ,t2 WHERE t1.a > 4 AND t2.b >5;
如果先進行笛卡爾積再進行過濾條件時,則會產生很多不必要的元組。但是如果先過濾 t1 , t2 的關係,在進行笛卡爾積,那麼表示式的消耗將大大減少。在進行過濾時,能做到一個select運算元中就做到運算元中,不能的話,就在具有過濾需要的列時及時做好,比如 a.a > 5 and b.b > 10 and a.c > a.b,第一個和第二個條件都可以推到 select 運算元中,在這兩個運算元上面立即加一個 a.c > a.b 的過濾條件。
CBO 則基於統計資訊對代價進行代價預估,得到一條較優的查詢路徑。例如:我們在做三個表連線的時候,如果有統計資訊的話,我們就可以知道,哪兩個表先做連線會使接下來執行的代價更小,因為在做 hashjoin 時,我們總希望小的表先進入,然後製作成一個小的 hashtable,因為 hashtable 比較小,所以之後的大表在做 join 的時候,就會有更高的命中率。
4.快取服務 Cache Service
ZNBase 提供了兩種類型的快取服務,主要是用來提高資料訪問效率,減少重複消耗。
第一種是 Session 級的 Querycache,主要是快取使用者 SQL 語句指紋對應的 Memo 樹資料結構,減少同一 Session 的 SQL 語句多次構建邏輯計劃的開銷。SQL 語句指紋含有 SQL 語句的相關 Catalog 資訊和許可權等校驗資訊。
在重用 Memo 之前,會對 Memo 是否過期進行檢查:解析元資料所依賴的每個資料來源和 schema,以便檢查完全限定的物件名是否仍解析為相同物件的相同版本,檢查和時間相關的類型的構造和比較方式,以及使用者是否仍有足夠的許可權訪問這些物件。如果依賴項不再是最新的,則判定該 Memo 過期,需要重新構建。
第二種是叢集級別的元資料相關 Cache。其中 Catalog 資訊包含了資料庫常用的 scheme 資訊和元資料路由資訊。元資料路由資訊由 Dist Catalog service 提供。通過元資料路由資訊叢集任意節點可以訪問到所有需要的元資料或者資料。
5.分散式執行服務 Dist Execution Service
ZNBase 的 SQL 引擎整體設計模型參考了 Volcano 模型[1],Volcano 模型的提出者是 Goetz Graefe,其 1994 年發表此文,並於 2017 年獲得 Edgar F. Codd(關係模型奠基人)創新獎。
ZNBase 的分散式執行提出了一些與 Map-Reduce 類似,但與 Map-Reduce 的執行模型又完全不同的概念。
ZNBase 的邏輯計劃由優化後的 Memo 自底而上構建出一個 Plan node 樹狀結構,為後續構建物理計劃新增一些額外的表資訊,列資訊等。
分散式執行的關鍵思想是如何從邏輯執行計劃到物理執行計劃,這裡主要涉及兩方面的處理,一個是計算的分散式處理,一個是資料的分散式處理。
一旦生成了物理計劃,系統就需要將其拆分並分佈到各個 node 之間進行運行。每個 node 負責本地排程資料處理器 data processors 和輸入同步器 synchronizers。node還需要能夠彼此通訊以將輸出 output router 連線到 input synchronizer。特別是,需要一個 streaming interface 來連線這些元件。為了避免額外的同步成本,需要足夠靈活的執行環境以滿足上面的所有這些操作,以便不同的 node 除了執行計劃初始的排程之外,可以相對獨立的啟動相應的資料處理工作,而不會受到 gateway 節點的其他編排影響。
ZNBase 的叢集中的 Gateway node 創建一個 Scheduler 排程器,它接受一組 flow,設定輸入和輸出相關的資訊,創建本地 processor 並開始執行。在 node 對輸入和輸出資料進行處理的時候,我們需要對 flow 進行一些控制,通過這種控制,我們可以拒絕 request 中的某些請求。

執行 Flow 示意圖
每個 Flow 表示整個物理計劃中跨節點執行的一個完整片段,由 processors 和 streams 組成,可以完成該片段的資料拉取、資料計算處理和最終得資料輸出。如下圖所示:

計劃執行示意圖
對於跨節點的執行,Gateway node 首先會序列化對應的 FlowSpec 為 SetupFlowRequest,並通過 grpc 傳送到遠端 node,遠端 node 接收後,會先還原 flow,並創建其包含的 processor 和互動使用的 stream(TCP 通道),完成執行框架的搭建,之後開始由閘道器節點發起驅動的多節點計算。Flow 之間通過 box 快取池進行非同步排程,實現整個分散式框架的並行執行。
對於本地執行,就是並行執行,每個 processor,synchronizer 和 router 都可以作為 goroutine 運行,它們之間由 channel 互聯。這些 channel 可以緩衝通道以使生產者和消費者同步。
為實現分散式併發執行,ZNBase 在執行時引入了 Router 的概念,對於 JOIN 和AGGREGATOR 等複雜運算元根據資料分佈特徵,實現了三種資料再分佈方式,mirror_router、hash_router 和 range_router,通過資料再分佈實現 processor 運算元內部拆分為兩階段執行,第一階段在資料所在節點做部分資料的處理,處理後結果,根據運算元類型會進行再分佈後,第二階段彙集處理,從而實現了單個運算元多節點協作執行。
小結
本文介紹了基於谷歌 Spanner 論文設計的分散式 NewSQL 資料庫 ZNBase 的 SQL 引擎架構,並詳細介紹了每個節點中的連線服務、編譯服務、快取服務,以及系統中的分散式目錄服務、分散式執行服務五大服務元件的技術原理與工作流程。下期文章我們將介紹在原有 SQL 引擎架構的基礎上,ZNBase 團隊針對編譯服務、分散式執行服務等元件進行的一系列優化改進工作。
相關文章
導讀與傳統關係型資料庫相比,分散式資料庫系統具有多叢集、多節點、高併發等特性,這就需要分散式資料庫的 SQL 引擎能夠在滿足使用者常規的 SQL 請求以外,提供多叢集、多節點協
2021-06-22 11:05:17

自鴻蒙在6月初發布後,引起了廣大網友的關注,即便沒有使用華為手機,也關注著鴻蒙的成長,畢竟好的產品,又是國內自研的,我們肯定是要支援國貨的。鴻蒙系統也沒有讓人失望,僅釋出一週,
2021-06-22 11:05:02

自從紅米手機發布了紅米K20系列、紅米K30系列以及紅米K40系列之後,直接成功立足於中端手機市場,並且取得了十分耀眼的成績。雖然紅米redmi目前依舊沒有擺脫價效比的束縛,但對於
2021-06-22 11:04:15

iPhone一直是消費者喜愛的手機產品,並且iPhone的換代時間也比較長。不過值得注意的是,iPhone系列從未釋出過專業的遊戲機型。各大安卓手機廠商在紛紛釋出了自家品牌的遊戲手機
2021-06-22 10:44:11
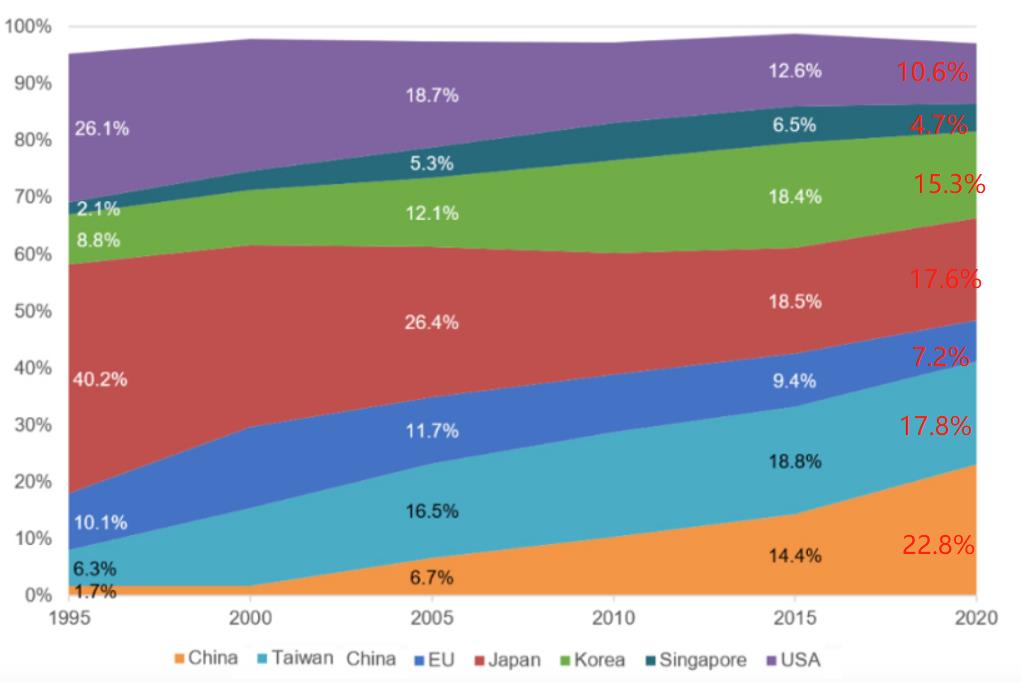
前幾天,SEMI(國際半導體產業協會)釋出了一份截止至2020年底的,全球晶圓產能的最新資料。資料顯示,過去的5年間,中國大陸的晶片產能差不多增長了一倍,從2015年佔全球的14.4%,變成了20
2021-06-22 10:43:35

黑暗、破曉隱藏在挫敗的洗禮之後創造、突破隱藏在時局的變換之中我不能證明歲月有腳,但確信他們在奔跑,曾經的榮耀已成為未來的預告。9年,見過你帶著誠摯第一次踏上這片賽場,聽
2021-06-22 10:42:03