作者 | 郭人通提到搜尋引擎,大家首先想到的一般是ElasticSearch。在文字作為資訊主要載體的階段,ElasticSearch技術棧是文字搜尋的最佳實踐。然而目前搜尋領域的資料基礎發生
2021-06-25 03:03:59

提到搜尋引擎,大家首先想到的一般是ElasticSearch。在文字作為資訊主要載體的階段,ElasticSearch技術棧是文字搜尋的最佳實踐。然而目前搜尋領域的資料基礎發生了深刻的變化,遠遠超過文字的範疇。視訊、語音、影象、文字、社交關係、時空資料等非結構化資料構築了更加「立體」的語義基礎。
傳統的文字搜尋技術與實踐方法很難套用到新興的資料搜尋場景上。主要的原因是,在非結構化資料中含有大量隱式的語義資訊,而這些資訊沒辦法通過語言文字進行準確的描述。例如,商品識別、人臉匹配、藥物篩選、使用者偏好與內容推薦等。對於這樣的搜尋場景,目前的主流做法是通過神經網路對資料中的語義進行提取。但這些提取出來的資訊並不以文字的方式進行描述,而是表示為具有隱式語義的高維向量。
向量資料庫以這些具有隱式語義的向量作為資料基礎,向上層應用提供搜尋服務。在AI作為搜尋主要驅動力的新階段,向量資料庫是構成非結構化資料搜尋技術棧的重要基礎軟體。
以下,我們從基本模型的角度出發,具體聊一聊為什麼文字搜尋技術難以適用到更加廣泛的資料搜尋場景,並對向量搜尋的基本模型進行介紹。

向量空間中的文字搜尋
對於非結構化資料的語義,常見的做法是在高維空間內對其進行描述。整個空間定義了所有可能的語義範圍。在這個空間內,語義相似度通過距離來度量。每個在實際業務中出現的非結構化資料被對映到這個空間內的一個點(或稱為一個高維向量),兩個非結構化資料的相似度即是這兩個點間的距離。不論是面向文字的TF-IDF向量,還是基於神經網路構造的embeddings,其語義相關性分析都是遵循這個思路。
為了方便理解,我們先從大家熟悉的文字搜尋聊起。
考慮以下三段文字:
A:」......第一次偷襲,是在淮海戰場之上,張大彪建議先打就近的敵暫七師......「
B:」......這兩個年輕人,不講武德,來騙!來偷襲!打我69歲的老同志。這好嗎?這不好......「
C:」......華爾街不講武德,WSB散戶被拔網線......「
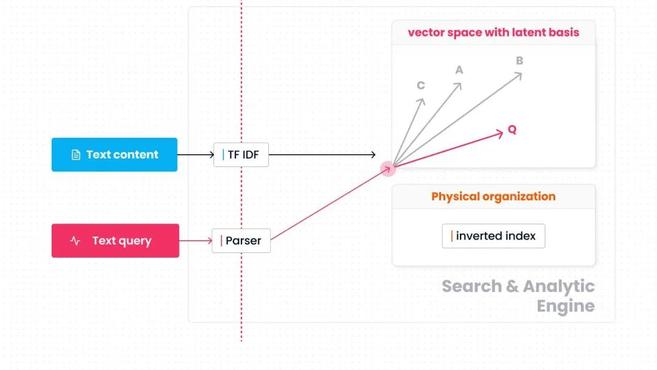
從精簡的模型上看,ElasticSearch(或Lucene)中的每一份文字都可以用一個高維向量來表示。向量的維度是詞典中所包含的詞的總數,每個維度對應一個詞,而各維度上的值為這些詞的TF-IDF分數(一個考慮了詞頻與逆文字頻率的分數,如果一個詞在文字中未出現,該分數為0)。
那麼上面三個文字對應的向量大概長這個樣子:

如果一個查詢請求是:
Q:"偷襲" and "不講武德"
這個查詢請求也會被對映到同樣的向量空間中。其對應的向量為:

「距離」的度量方式為:
$ f(Q,x)=left{ begin{aligned}&cos(Q, x), if 偷襲in x and 不講武德in x (1) &0, if 偷襲notin x or 不講武德notin x (2)end{aligned} right. $
這個值越大,x 與 Q 越相似。本例中,與查詢語句最相似的文字為B。Lucene在工程實現層面對上述模型做了大量優化。如我們所熟知的倒排索引作用於上式的條件(2),這類似一個剪枝的過程:如果一個必要的關鍵字沒有出現,那麼該文字與查詢語句的相似度為0。既然一定不會出現在最終的搜尋結果中,那就沒有必要進行後續的距離計算。

上圖總結了這個簡化的模型,向量空間以各詞語 (term) 作為座標基。關鍵字搜尋分為兩個階段。首先是原始資料到向量空間的對映過程。文字按詞語統計詞頻 (TF)、逆文件頻率 (IDF),並計算各詞語上的TF-IDF值。查詢語句則按謂詞中出現的詞語 (如"偷襲"、"不講武德") 對映至向量空間。其次是相似性分析,基於倒排索引加速向量空間內的搜尋過程和距離計算過程,找出與查詢語句向量相似的資料向量。
模型的基礎部分面向文字搜尋進行了特化設計,包括:
向量空間:維度與詞語一一對應;
資料到向量空間的對映:基於TF-IDF、謂詞;
相似性搜尋:以倒排索引進行資料組織。

從」顯式「與「可解釋性」,到「隱式」與」準確性「
可以明顯看出,文字搜尋以「顯式」的語義為基礎,模型層面和工程層面大體上都基於「詞」這個概念進行構建。這對於文字搜尋是自然的,整個搜尋過程對於「人」也是好理解的。但相同的模型很難適用於更廣泛的非結構化資料搜尋。其中面臨的問題主要有兩個:
一方面,在眾多非結構化資料中,很大一部分都不具有「顯式」的語義單元。例如,很難將一段視訊、一張照片、一個高分子化合物、一段使用者行為分解為類似「詞」這種顯式的、細小的語義單元。
另一方面,在實際的搜尋業務中往往希望引入多個維度的非結構化資訊,從而能夠更加立體地描述業務物件。以視訊推薦為例,其搜尋的輸入是使用者特徵,而搜尋的結果是最符合使用者當前瀏覽偏好的一組視訊。搜尋結果的好壞很大程度上依賴於對「使用者觀看偏好」的理解。但使用者偏好是一個複雜的概念,難以用單一維度的資訊進行準確描述。實際業務中,參考的特徵來源豐富:包括視訊分類、標籤、時長、語言、使用者瀏覽歷史、搜尋歷史、使用者地理位置、年齡、性別、語言等。
由多個維度的非結構化資料所驅動的資料搜尋已經變得越來越普遍。在使用者的業務中,我們觀察到越來越多的搜尋場景都需要解決好上述兩個問題,除了上面提到的視訊推薦,還包括藥物篩選、人臉識別、輔助設計、商品推薦等。
為了在這些搜尋場景上獲得更好的效果,新興的搜尋技術在可解釋性與準確性之間給出了新的權衡。以神經網路、embedding為代表的新技術更多考慮了後者。
這些技術在主體思路上與文字搜尋一致,都是將查詢的輸入與搜尋內容對映至具有相同語義的向量空間,並在這個空間內根據距離進行相似度分析。而差異在於,向量空間所對應的是隱式語義,向量空間著重於對語義相似性的準確刻畫,但不再具有易解讀的性質。
對應視訊推薦的例子,典型的做法是將不同維度的特徵進行彙總,並基於這些資訊訓練神經網路,分別以神經網路的中間層參數、中間層輸出作為視訊embedding、使用者embedding。基於資料訓練得到的神經網路對應著使用者、視訊兩類物件到向量空間的對映函數,這個對映函數的訓練目標是最小化語義相似性的誤差,但不論是對映函數還是向量空間,都不具有良好的可解釋性。

泛化的非結構化資料搜尋
一個具有泛化能力的非結構化資料搜尋系統應該具備兩個特徵:
能夠應對非結構化資料的多樣性;
能夠充分發揮神經網路等新型模型對語義的刻畫能力。

我們給出的泛化模型如上圖所示。與前面講到的文字搜尋模型相比,這個模型在結構上的明顯區別是將「資料到向量空間的對映函數」從搜尋引擎內移到了搜尋引擎外。即圖中「Mapping to vector space」的這部分(一般對應機器學習領域的encoder)。
這個選型的背後原因主要來自於工程層面。首先需要考慮的問題是資料類型爆炸。與傳統的數值類型不同,當前的非結構化資料大多與業務場景直接相關,且資料類型的抽象程度非常低。這就造成了一個問題,即非結構化資料的種類是隨著各個領域的數字化程度加深而與日俱增的。如果將對映函數內置於搜尋引擎,就意味著搜尋引擎在設計上需要考慮各類非結構化資料的具體語義。這一點所引發的系統複雜性增長,幾乎是致命的。我們在項目早期嘗試過將一些典型場景下的典型資料類型引入搜尋引擎,但依然發現這在工程層面非常困難,很難通過一套簡潔的框架來處理這些語義迥異但抽象程度又較低的資料類型。
其次需要考慮的問題是資料到向量空間的對映多樣性。由於現在的搜尋場景越來越複雜,所引入的資料處理方法與模型也越來越豐富。所需要的函數能力遠超搜尋引擎內建函數或自定義函數插件的能力範圍。目前常見的做法是依靠大資料處理與AI兩個生態上的工具來完成原始資料到向量空間的對映,如Spark、Pytorch、Tensorflow、Keras等。因此,將對映函數移至搜尋引擎外,實際上決定了搜尋引擎與大資料系統生態、AI系統生態的對接關係。
值得注意的是,雖然對映的部分有豐富的系統生態做支撐,但在應對具體的搜尋問題時,仍然需要做很多定向的開發。這一點,並沒有像搜尋引擎的內建函數或UDF那樣便利。以我們目前的經驗來看,垂直領域內的典型場景是可以抽象出很多公共的處理流程的。我們也高興的發現,當前一些開源項目已經著手補全這些拼圖,如JINA等。
在剝離出「資料到向量空間的對映函數」後,搜尋引擎的資料類型變得非常簡潔,在傳統的抽象類型之上,我們只需增加一類抽象類型 --- 向量。在搜尋引擎內部,主要考慮向量空間上的操作,包括向量的儲存、距離的計算、搜尋過程的優化。由於對映過程完全透明,搜尋引擎不依賴「對映語義」(如文字搜尋中某個詞會被對映至某個維度)對搜尋過程進行優化。所採用的思路是直接基於「相似性語義」構建索引系統。以向量間的兩兩「距離」作為度量,搜尋引擎將向量按聚類或圖組織成索引。相應的搜尋過程對應著聚類的部分遍歷或圖的部分遍歷。
總結下來,泛化的模型的主要特點如下:
向量空間:維度與隱式的語義相對應,
資料到向量空間的對映:基於神經網路或垂直領域的定製模型、與搜尋引擎充分解耦,
相關性搜尋:以聚類或圖進行資料組織。

小結
我們從向量空間的角度出發,分析了文字搜尋模型,並結合當前的搜尋場景,討論了搜尋能力泛化所需解決的問題,最後給出了泛化的非結構化資料搜尋模型。
致謝
感謝吳一凡同學的精美配圖,以及易小萌博士、星爵同學對文章的修改建議。
作者簡介:郭人通,ZILLIZ合夥人,系統架構師。華中科技大學計算機軟體與理論博士。



相關文章
作者 | 郭人通提到搜尋引擎,大家首先想到的一般是ElasticSearch。在文字作為資訊主要載體的階段,ElasticSearch技術棧是文字搜尋的最佳實踐。然而目前搜尋領域的資料基礎發生
2021-06-25 03:03:59

據悉以加盟製為主的快遞企業正瘋狂壓榨快遞小哥和加盟商,導致如此結果應該是快遞行業競爭日漸激烈所致,這些加盟制的快遞企業已感受到這個行業的衰落而選擇最後的瘋狂。快遞企
2021-06-25 03:03:43

儘管在Windows 11正式推出之前,網上已經洩露了Win11的ISO,同時有相當多的使用者開始嘗試Win11,但這並不妨礙微軟在今天深夜舉辦釋出會,向大家正式推出Win11,在今天的釋出會上,微軟
2021-06-25 03:03:19

【微創WEC科技】近期,關於iPhone 13爆料逐漸增多,近期的爆料稱iPhone 13可能不叫iPhone 13,而是叫iPhone 12s,其實叫啥都沒關係,只是一個名稱罷了。但新iPhone將採用小「劉海」設
2021-06-25 03:02:59
【CNMO新聞】6月24日晚,微軟召開了主題為「what's next for Windows」的線上釋出會,推出了新的Windows 11系統,這是微軟6年來首次推出新的Windows系統。本次釋出會解開了Window
2021-06-25 03:02:12

雖然微軟曾經說過,Windows 10會作為一項服務,持續更新下去,不會再有Windows 11,但還是食言了。6月24日晚,微軟舉辦線上釋出會,正式宣佈了新一代Windows 11!Windows 11從介面設計到
2021-06-25 03:00:23