機器之心釋出作者:葛雲皓本文提出了一個視覺推理解釋框架 (VRX: Visual Reasoning eXplanation), 將人們容易理解的、high-level 的結構化的視覺概念作為「語言」,通過回答為
2021-06-25 20:15:52
機器之心釋出
作者:葛雲皓
本文提出了一個視覺推理解釋框架 (VRX: Visual Reasoning eXplanation), 將人們容易理解的、high-level 的結構化的視覺概念作為「語言」,通過回答為什麼是 A,為什麼不是 B 解釋神經網路的推理邏輯。VRX 還可以利用解釋對網路進行診斷,進一步提升原網路的效能。
本文主要介紹了被 CVPR 2021 錄用的文章《A Peek Into the Reasoning of Neural Networks: Interpreting with Structural Visual Concepts》。這項工作對神經網路推理邏輯的可解釋性進行了探究:區分於大多數現有 xAI 方法通過視覺化輸入影象和輸出結果之間的相關性對網路進行解釋,該研究提出用結構化的視覺概念(Structural Visual Concept) 對神經網路決策背後的推理邏輯和因果關係進行解釋,通過解答網路決策中「為什麼是 A?為什麼不是 B?」 的問題,用人們更容易理解的 high-level 視覺概念和視覺概念之間的結構和空間關係解釋神經網路的推理邏輯,並將其作為一種直接指導來提升被解釋網路的效能。

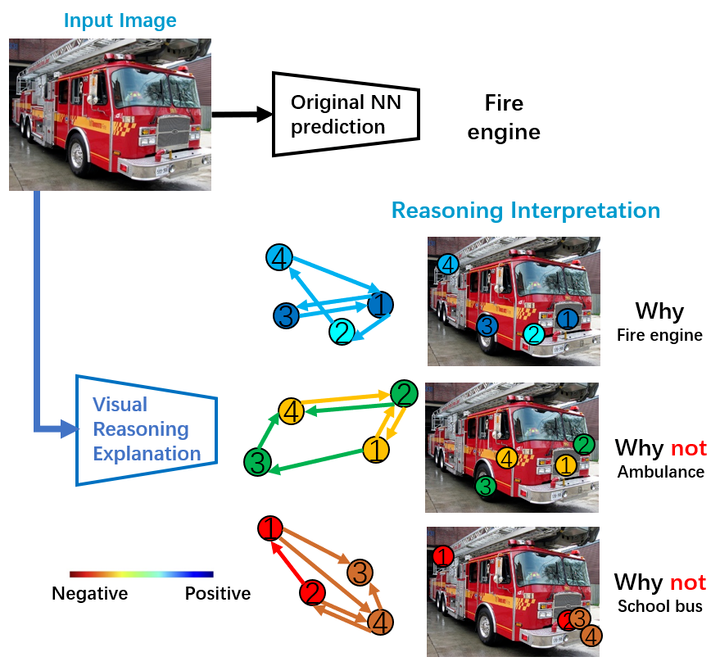
下圖概括了這篇文章要做的任務:為了解釋原網路決策背後的推理邏輯,該研究回答瞭如下問題:為什麼是消防車?為什麼不是救護車?又為什麼不是校車?該研究用結構化的視覺概念圖(Structural Concept Graph) 作為解釋的語言,其中概念圖的節點 (node) 代表視覺概念(visual concept),邊 (edge) 代表視覺概念之間的結構和空間關係,點和邊的顏色代表其對該類最終決策的貢獻度(冷色:正向 或 暖色:負向):(1)為什麼是消防車?從視覺概念角度,所有檢測到的四個與消防車最相關的視覺概念(保險槓,消防車頭,車輪,救援架)都對最終消防車的決策有正向貢獻;從視覺概念的空間結構關係角度,四個概念之間的空間關係也都對決策有正向貢獻,這說明視覺概念和他們之間的關係都像一輛消防車。(2)為什麼不是校車?從視覺概念角度:從圖中檢測到的與校車視覺概念最接近的四個部分及其相關結構和空間關係都對校車的決策起到負向貢獻(否定該圖是校車的決策)尤其是概念 1 和概念 2,與真正的校車概念最不相符。(3)為什麼不是救護車?也同樣可以得到相似的人們容易理解的,邏輯上的,視覺概念角度的解釋。

下面將詳細介紹工作的具體內容。
研究動機
在深度學習日益蓬勃發展的今天,深度神經網路不透明的決策導致的安全事故和隱患也越來越多,神經網路的可解釋性對於人們如何更加信任、安全、可靠的使用他們至關重要。近年來有越來越多關注可解釋性的研究,例如:pixel-level 的方法 (CAM[1]Grad-CAM[2]等) 通過視覺化輸入影象和輸出結果之間的相關性解釋網路的決策,為理解神經網路決策依據找到了線索;concept-level 的方法 (TCAV[3]ACE[4]等) 可以找到給定類別重要的視覺概念。然而,這些方法是否侷限於解釋相對 low-level 的相關性?是否有更加方便人們理解的更直觀的 high-level 的解釋方法?我們是否可以揭示神經網路內在的推理邏輯和因果關係?邏輯解釋能否作為線索進一步幫助提高原網路的效能?

為了回答這些問題,該研究探究如何模擬和解釋神經網路的推理邏輯,提出用結構化的視覺概念對神經網路決策背後的推理邏輯和因果關係進行解釋,通過解答網路決策中 「為什麼是 A,為什麼不是 B?」 的問題,用人們更容易理解的 high-level 視覺概念和視覺概念之間的關係解釋神經網路的推理邏輯,並將其作為指導來提升原網路的效能。

方法詳述
該研究提出的視覺推理解釋框架(VRX:Visual Reasoning eXplaination Framework)包括三個主要部分:
(1)視覺概念提取器 (VCE: Visual Concept Extractor) 用來提取特定類別相關的重要視覺概念,並將影象表示為結構化的視覺概念圖 (SCG: Structural Concept Graph);(2)概念圖推理網路 (GRN: Graph Reasoning Network) 以視覺概念圖為輸入,通過知識蒸餾和遷移來模擬原網路的決策過程;(3)視覺化決策直譯器 (VDI: Visual Decision Interpreter) 用來解釋原網路決策背後的推理邏輯和因果關係。
接下來對每個部分進行詳細解釋。
視覺概念提取器和結構化的視覺概念
該研究首先介紹了什麼是視覺概念 (Visual Concept),簡單來說視覺概念展示了給定神經網路對不同類別的理解,同時人們也更容易接受符合直覺的概念級別的解釋:以下圖警車為例,在給定的神經網路 「眼裡」,警車 Top2 重要的視覺概念視覺化為最右邊綠色圈中的 patch (看起來像輪子和駕駛室側面)。ACE[4] 中作者對視覺概念進行了定義:類別相關的視覺概念是畫素點的集合 (group of pixels) 並滿足以下三個要求:
(1)有意義 (Meaningfulness):即視覺概念需要具有語義上的涵義,單個的畫素就沒有語義涵義,所以需要是畫素點的集合,比如圖片 patch。(2)一致性 (Coherency):同一視覺概念在不同圖片中的表現應該相似,不同視覺概念之間應該不同。(3)重要性 (Importance):如果一個視覺概念的存在對於該類樣本的真實預測是必要的,那麼它對於該類的預測就是「重要的」。
下圖描述了 ACE 中對給定網路、給定類別的視覺概念的提取過程:以警車為例,首先 (a) 用多解析度的分割演算法對圖片進行分割得到 patch(這裡的分割採用的是 SLIC[5],一種基於規則的分割演算法,選擇該方法是對於其速度和效果的綜合考慮); 然後(b) 將分割得到的 patch resize 為統一大小,通過給定網路將 patch 轉化為向量,並在向量空間做聚類; 最後(c) 利用 Testing with Concept Activation Vectors (TCAV)[3] 得到每個聚類的潛在視覺概念對警車類別的重要性分數,並剔除 outlier,留下對警車類別來說最重要的 top 視覺概念。

但研究發現,ACE 提取視覺概念的效果非常依賴用於提取視覺概念的圖片的質量,一般每一類選取 50~100 張左右的圖片用於提取視覺概念,如果圖片有一些 bias 或者不是很具有代表性,就會導致很多提取的視覺概念落在背景區域,比如下圖(左),這些視覺概念並不能代表網路學習了該類 1000 張影象(ImageNet)以後對該類(救護車)的理解。為了解決這個問題,該研究提出使用自頂向下的梯度注意力 (Attention Map) 對視覺概念提取區域進行約束, 因為 Grad-CAM 的 attention map 可以高亮顯示對網路決策重要的區域(多為前景),這樣可以幫助剔除掉提取視覺概念的圖片中與類別無關的背景部分,使得提取的視覺概念更能代表原網路對該類的理解,如下圖右。

以吉普車類別為例,下圖總結了視覺概念提取器提取視覺概念的步驟。

提取出類別相關的視覺概念後,研究者認為視覺概念之間有潛在的空間結構關係,這種空間關係對類別表達至關重要:比如我們並不能說,只要能在影象中檢測到吉普車的四個最重要的視覺概念就代表一定是吉普車,他們之間的空間關係是相對確定的,例如輪子不能在車頂上方。我們人類做決策也是相似的:我們認為這是一輛吉普車,不僅關鍵的特徵(視覺概念)符合認知,特徵之間的空間關係同樣會影響我們的推理和最終決策。因此該研究認為結構化的視覺概念 才是更符合人們直覺的,解釋神經網路推理決策的重要「語言」。後續的模擬並解釋神經網路的推理決策過程也是基於此展開的。
結構化視覺概念的一種表達便是結構概念圖 (SCG: Structural Concept Graph),graph 中不同顏色的點代表不同重要性 (Top k) 的視覺概念,邊代表視覺概念之間的空間關係。如下圖吉普車和斑馬的例子,我們可以把任意圖片表達為對應類別的結構概念圖。注意:目前是 image-level 的 SCG (I-SCG),後續會用 基於 learning 的方法,學習到 class-level 的 SCG(c-SCG)。

概念圖推理網路
有了結構概念圖作為人們容易理解的解釋神經網路的「語言」,接下來可以用這種「語言」解釋神經網路決策背後的推理邏輯。ACE[4]的作者為了驗證提取到的視覺概念對神經網路決策的重要性,實驗驗證發現:如果只保留輸入圖片中表達重要視覺概念的畫素(mask 掉與重要視覺概念無關的區域),神經網路能保留原本 80% 以上的準確率。因此一個比較直接的想法便是:我們能不能追蹤並可視化神經網路決策過程中重要視覺概念相關特徵的流動,這樣我們便能找到最終決策與重要視覺概念之間的關係,從而對決策進行解釋。以下圖為例對於一個經典的由卷積層和全連線層構成的神經網路,我們用不同的顏色代表吉普車最重要的四個視覺概念,在卷積層,我們可以根據結構不變性 追蹤每個視覺概念對應的 representation feature。但是全連線層中,所有特徵 耦合到了一起,使得追蹤變得困難。研究者分析這是由於神經網路結構上資訊流動不夠透明和難以解耦導致的,與此同時研究者想到另一種解決辦法:如果可以用另一個結構比較解耦的,資訊流動更加透明的模型 B,全方位模擬原始神經網路 A 的推理和決策,是不是就可以通過解釋 B 的推理邏輯來解釋 A 呢?

為此研究者提出概念圖推理網路 (GRN: Graph Reasoning Network),以結構概念圖為輸入,通過知識蒸餾和遷移來模擬原網路的決策過程(如下圖)。

下圖解釋了概念圖推理網路的訓練過程:對於輸入圖片,該研究首先構建對於每個感興趣類別的結構概念圖(即先將影象進行分割,然後在所有 patch 中分別檢測每個感興趣類別的重要視覺概念:從下圖中檢測到 2 個消防車的視覺概念(黃色圓圈),2 個老爺車的視覺概念 ... 4 個吉普車的視覺概念),這些檢測到的視覺概念組成相應類別的結構概念圖,表示對其決策的假設(該圖是消防車嗎?是老爺車嗎 ... 是吉普車嗎?)很多類別我們只能檢測到部分視覺概念,檢測不到的視覺概念用 dummy node 來表示(黑色 node)。然後概念圖推理網路利用圖卷積,對每一個結構概念圖進行 representation,學習其視覺概念及其之間的關係對最終決策的影響。最後該研究把所有點和邊 concatenate 為一個向量, 通過非常簡單的 MLP 輸出對所有感興趣類別的決策向量,並用知識蒸餾的方法使得概念圖推理網路與原網路的決策一致。為了提升模擬的魯棒性,該研究還用 mask out 視覺概念新增擾動的方法使得概念圖推理網路與被解釋的原網路在面對擾動時決策一致。(詳細訓練過程和公式推導請見原始 paper)。

訓練中,所有類別的結構概念圖共享一套圖卷積的參數,但是每個類別在訊息傳遞(message passing ) 中有專屬的注意力權重參數 eji,類別專屬的注意力權重參數是為了學習每個類別獨特的視覺概念之間的空間和依賴關係,一方面可以解釋並可視化概念圖推理網路學習到的每個類別視覺概念之間潛在的關係(下圖),另一方面為最終推理過程的解釋提供了支援。下圖是用學習到的消防車的 eji 篩選出重要的視覺概念之間的關係。邊的 eji 值越大,代表點 j 對點 i 的貢獻越大;從右邊的 sum 可以看到消防車的視覺概念 1 和 2 對其他的視覺概念貢獻最大,這也意味著他們是對消防車來說最有區分度的視覺概念。

視覺化決策直譯器 (VDI: Visual Decision Interpreter)
訓練好的概念圖推理網路便是原網路的 representation,基於圖卷積神經網路的概念圖推理網路具有資訊傳遞透明且容易追蹤的特點,為了用結構概念圖對推理過程進行解釋,該研究提出了基於梯度的貢獻度分配演算法,為每個參與決策的點(視覺概念)和邊(概念之間的關係)計算其對於特定決策的貢獻值,貢獻值的高低代表了其肯定還是否定了該決策。最後決策直譯器可視化了對原網路輸出的解釋並回答為什麼是吉普車?為什麼不是其他類別?(顏色代表肯定:冷色,或否定:暖色)如下圖右:(1)為什麼是吉普車?從視覺概念角度,所有檢測到的四個與吉普車最相關的視覺概念(前燈,擋風玻璃,後窗,車輪)都對最終吉普車的決策有正向貢獻(深藍或淺藍);從視覺概念的空間結構關係角度,四個概念之間的空間關係也都對決策有正向貢獻,這說明視覺概念和他們之間的關係都像一輛吉普車。(2)為什麼不是消防車?從視覺概念角度:從圖中檢測到的與消防車視覺概念最接近的四個部分及其相關結構和空間關係都對消防車的決策起到負向貢獻(否定該圖是消防車的決策)尤其是概念 1 和概念 2,與真正的消防車概念最不相符。(3)為什麼不是老爺車等?也同樣可以得到相似的人們容易理解的、邏輯上的、視覺概念角度的解釋。

實驗和結果
視覺推理解釋 (VRX) 與原網路之間邏輯一致性實驗
第一個實驗目的是驗證視覺推理解釋框架 (VRX) 做出的推理解釋與原網路的邏輯是一致的。
如下圖,原網路 Xception 錯把一張消防車分類成了救護車,VRX 給出解釋(如左圖):為什麼不是消防車?因為從影象中檢測到的消防車的視覺概念 3 和 4 都對消防車的決策起到負向貢獻即否定該決策。為什麼是救護車?因為檢測到的救護車的視覺概念 3 和 4 都對救護車的決策起到正向貢獻,即肯定該決策。即使所有消防車視覺概念之間的空間關係(邊)相對救護車的空間關係更加合理,但是綜合來看,Xception 還是做出了救護車的決策。
為了驗證解釋的合理性以及與原網路決策邏輯的一致性。該研究做了兩個實驗 :(1)研究人員把原圖中檢測到的對消防車決策起負向作用的消防車的概念 3 (車輪) 替換為另外一張消防車圖片中的更合理的概念 3 (右圖第一行),然後讓 Xception 對新的圖片再次分類,發現錯誤被糾正了。此外,該研究也做了對比試驗:如果用一張隨機的消防車的 patch 去替換概念 3,或者用另外一張消防車的同樣合理的概念 1 和 2 替換原始的概念 1 和 2,Xception 都無法糾正錯誤。所以研究者認為 VRX 對 Xception 推理的解釋符合原網路的邏輯。(2)研究人員把原圖中檢測到的對救護車的決策起正向作用的救護車的概念 3 mask 掉,發現 Xception 對新圖片的預測結果有糾正的趨勢(消防車概率增大,救護車概率減小)。對比實驗發現如果隨機刪除 patch 則不會有糾正的效果。

上述驗證實驗一共在 119 張 Xception 錯分的圖片中實施,研究者用 VRX 對錯誤原因背後推理邏輯的解釋作為修改建議,通過視覺概念的替換和刪除,原網路超過 95% 的錯分可以被正確的糾正(如下表 1)。

VRX 對視覺和結構解釋的敏感性實驗
VRX 可以從視覺概念(點)和視覺概念之間的空間關係(邊)兩個角度為決策提供解釋。通過新增擾動,分別預設輸入影象的視覺層面不合理和空間結構的不合理,探究 VRX 的解釋對視覺和結構的敏感性。

給定一張 Xception 正確預測的救護車圖片,VRX 給出瞭解釋。(a)如果把一個救護車相對合理的視覺概念 2(對救護車決策起到正向貢獻)替換為一個相對不合理的視覺概念 2(在另一張救護車影象中對決策起到負向貢獻),VRX 對新圖片決策的解釋可以正確捕捉到不合理的部分:被替換的概念 2。(b)如果把視覺概念 4(車輪)移動到一個不合理的位置(擋風玻璃上方),VRX 對新圖片決策的解釋可以正確捕捉到不合理的部分:視覺概念 4 和其他視覺概念之間的空間關係。由此研究者認為 VRX 可以準確的定位視覺和結構的不合理,並給出準確的解釋。
VRX 根據解釋對原網路進行診斷並提升原網路的表現
之前的實驗展示了 VRX 對原網路的解釋可以幫助原網路糾正對圖片的錯誤分類,接下來的實驗中,VRX 將利用可解釋性對原網路進行診斷,發現原網路訓練中存在的問題(比如訓練資料的 bias),從而提出針對性修改建議,進而提升原網路的表現。
如下圖,研究者用 Resnet-18 訓練了一個三種車輛的分類器 ,(a) 訓練資料有 pose 的 bias,所有的公共汽車都是 pose 1,所有坦克都是 pose 2,所有軍用汽車都是 pose 3;但測試資料沒有 pose bias,即所有車輛都有全部的 pose 1,2 和 3。(b) 測試發現分類器的準確率較低,該研究用 VRX 對模型進行診斷,發現大部分錯分的影象其實都能找到正確的視覺概念,錯誤原因是因為概念之間的關係否定了正確的決策,導致錯分。以下圖 (b) 為例,一輛軍用汽車被錯分為坦克,解釋為什麼不是軍用汽車的時候發現是軍用汽車視覺概念之間的空間關係否定了該圖是軍用汽車的決策,而從圖中檢測到的坦克的視覺概念雖然較差,但是空間關係支援是坦克的決策,綜合以上導致了錯分。所以 VRX 診斷給出的建議是增加視覺概念之間空間關係的多樣性和魯棒性 。

根據診斷建議,最直接的實現方法便是增加不同 pose 的圖片,研究者做了接下來的驗證實驗:setting 1:為每類增加 150 張不同於原始資料集 pose 的圖片;setting 2:為每類增加 150 張與原始資料集 pose 相同的圖片(對照組)。研究者用新的資料集分別重新訓練了 Resnet-18 分類器並測試資料集準確率 (結果如下表 2)。VRX 根據解釋性的診斷幫助提升了原始模型的效果。

VRX 對原模型的診斷可以總結模型的不同問題並提出相應提升建議。下圖是 VRX 對在 ImageNet 上預訓練的 Xception 其中六類的診斷,VRX 將其錯誤總結為三種類別,並對每種錯誤的修改提出建議。(細節請參考原 paper)。

總結和展望
總結來說,這項工作在神經網路的可解釋性方向做了進一步探索:解釋神經網路決策背後的推理邏輯。該研究提出了一個視覺推理解釋框架 (VRX: Visual Reasoning eXplanation), 將人們容易理解的、high-level 的結構化的視覺概念作為「語言」,通過回答為什麼是 A,為什麼不是 B 解釋神經網路的推理邏輯。VRX 還可以利用解釋對網路進行診斷,進一步提升原網路的效能。研究者相信這是朝著更透明、更安全、更可信的 AI 方向邁出的小但是重要的一步。
相關文章
機器之心釋出作者:葛雲皓本文提出了一個視覺推理解釋框架 (VRX: Visual Reasoning eXplanation), 將人們容易理解的、high-level 的結構化的視覺概念作為「語言」,通過回答為
2021-06-25 20:15:52

ASML的預言,或將成真嗎?限制晶片以及裝置出口,也確實使得國內不少企業受到衝擊,但是此前與國內有合作的商家也受到了打擊,有分析指出美企都已經損失千億,比如高通或將失去80億的市
2021-06-25 20:14:57

在萬億民航市場中,美國波音與歐洲空客長時間來都佔據主導地位。在全球民航客機總數量中,波音佔比為40.1%,而空客則佔比33.6%,實力相當的二者互將對方視為最大的競爭對手,由此展開
2021-06-25 20:14:19

華為Watch 3作為華為今年的重磅新品,除了顏值和硬體配置外,它最大的亮點還是在HarmonyOS和健康管理這兩個方面,現在它剛剛發售,很多朋友關心它是否值得購買,非華為手機的使用者是
2021-06-25 19:54:53

近段時間,我國半導體領域相繼傳來振奮人心的訊息。據悉,我國28nm完全自主晶片將在今年實現量產,14nm工藝晶片有望在明年登場。但是,在晶片產業鏈中,我國還需要在EDA軟體方面尋求
2021-06-25 19:53:57

機器之心報道機器之心編輯部來自以色列特拉維夫大學的研究者在生成影象方面又有了新的升級,所用方法在保留源影象身份的同時,在細節編輯上實現了更精細的效果。英偉達提出的風
2021-06-25 19:53:31