來源:資料STUDIO作者:雲朵君資料透視表將每一列資料作為輸入,輸出將資料不斷細分成多個維度累計資訊的二維資料表。在實際資料處理過程中,資料透視表使用頻率相對較高,今天雲朵君
2021-06-28 16:14:13
來源:資料STUDIO
作者:雲朵君
資料透視表將每一列資料作為輸入,輸出將資料不斷細分成多個維度累計資訊的二維資料表。在實際資料處理過程中,資料透視表使用頻率相對較高,今天雲朵君就和大家一起學習pandas資料透視表與逆透視的使用方法。
本次使用的資料來源於Kaggle,車輛被警察攔下並進行搜查記錄資料集,簡稱車輛資料。文末有下載方式,大家按需獲取。
資料基本情況

groupby資料透視表
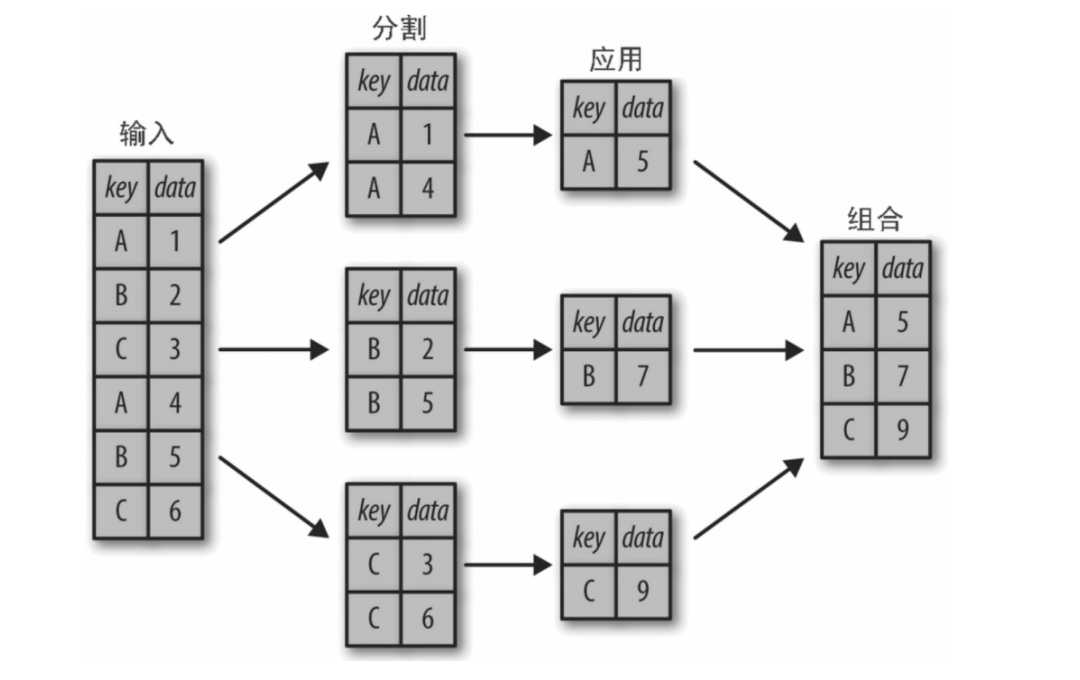
使用 pandas.DataFrame.groupby 函數,其原理如下圖所示。

使用車輛資料集統計不同性別司機的平均年齡,聚合後用二維切片可以輸出DataFrame資料框。
data.groupby('driver_gender')[['driver_age']].mean()

在聚合後一維切片會得到 pandas.Series.
data.groupby('driver_gender')['driver_age'].mean()
driver_genderF 32.607399M 34.537886Name: driver_age, dtype: float64
可能還想進一步探索,同時觀察不同司機性別與司機種族的平均年齡。根據 GroupBy 的操作流程,我們也許能夠實現想要的結果:將司機種族('driver_race')與司機性別('driver_gender')分組,然後選擇司機年齡('driver_age')列,應用均值('mean')累計函數,再將各組結果組合,最後通過行索引轉列索引操作將最裡層的行索引轉換成列索引,形成二維陣列。
data.groupby(['driver_gender','driver_race'] )[['driver_age']].aggregate('mean')

通過unstack重排資料表
如果原表只有一級索引,unstack就將每一個列都分出來,然後全部縱向疊加在一起,每一個列名作為新的一級索引,原本的索引作為二級索引。如果原表有二級索引,那麼unstack就會將二級索引作為新的列名,一級索引作為新的索引。
data.groupby(['driver_gender', 'driver_race'] )[['driver_age']].aggregate('mean').unstack()

pivot_table
雖然這樣就可以更清晰地觀察出不同司機性別與司機種族的平均年齡,但程式碼有點複雜。要理解這個長長的語句可不是那麼容易的事。
由於二維的 GroupBy 應用場景非常普遍,因此 Pandas 提供了一個快捷方式 pivot_table 來快速解決多維的累計分析任務。
pivot_table()的參數values待聚合的列的名稱。預設聚合所有數值列index 用於分組的列名或其他分組鍵,出現在結果透視表的行columns 用於分組的列名或其他分組鍵,出現在結果透視表的列aggfunc 聚合函數或函數列表,預設為'mean'。可以使任何對groupby有效的函數fill_value 用於替換結果表中的缺失值dropna 預設為Truemargins_name 預設為'ALL',當參數margins為True時,ALL行和列的名字
同樣是上面的需求,同時觀察不同司機性別與司機種族的平均年齡 ,用pivot_table實現透視表。
data.pivot_table(values='driver_age', index='driver_gender', columns='driver_race')

多級資料透視表
與 GroupBy 類似,資料透視表中的分組也可以通過各種參數指定多個等級。
行索引和列索引都可以再設定為多層,不過行索引和列索引在本質上是一樣的,大家需要根據實際情況合理佈局。
data.pivot_table(values='driver_age', index=['driver_gender', 'stop_duration'], columns='driver_race')

自定義聚合函數
aggfunc 參數用於設定累計函數類型,預設值是均值(mean)。累計函數可以用一些常見的字元串 ('sum'、'mean'、'count'、'min'、'max' 等)表示,也可以用標準的累計函數(np.sum()、min()、sum() 等)。
還可以通過字典為不同的列指定不同的累計函數。
如果傳入參數為list,則每個聚合函數對每個列都進行一次聚合。如果傳入參數為dict,則每個列僅對其指定的函數進行聚合, 此時values參數可以不傳。data.pivot_table(index='driver_gender', columns='driver_race', aggfunc={'driver_age':'mean', 'violation':'count'})

這裡沒有使用參數 values。其實在我們通過字典為 aggfunc 指定對映關係的時候,待透視的數值就已經確定了。
margin 的標籤可以通過 margins_name 參數進行自定義, 預設值是 "All"。
下面按行、按列進行彙總,指定彙總列名為「Total」
data.pivot_table(index="driver_gender", columns="driver_race", values="violation", aggfunc= "count", margins=True, margins_name="Total")

pandas.crosstab
crosstab是交叉表,是一種特殊的資料透視表預設是計算分組頻率的特殊透視表(預設的聚合函數是統計行列組合出現的次數)。如果指定了聚合函數則按聚合函數來統計,但是要指定values的值,指明需要聚合的資料。
pandas.crosstab 參數index:指定了要分組的列,最終作為行。columns:指定了要分組的列,最終作為列。values:指定了要聚合的值(由行列共同影響),需要指定aggfunc參數。rownames:指定了行名稱。colnames:指定了列名稱。aggfunc:指定聚合函數。必須指定values的值。margins:布爾值,是否分類統計。預設False。margins_name:分類統計的名稱,預設是"All"。dropna:是否包含全部是NaN的列。預設是True。
pd.crosstab(index=data.driver_gender, columns=data.driver_race, margins=True)

逆透視
如果說df.pivot()將長資料集轉換成寬資料集,df.melt()則是將寬資料集變成長資料集 melt()既是頂級類函數也是例項物件函數,作為類函數出現時,需要指明DataFrame的名稱
pd.melt 參數frame被 melt 的資料集名稱在 pd.melt() 中使用id_vars 不需要被轉換的列名,在轉換後作為標識符列(不是索引列)value_vars 需要被轉換的現有列,如果未指明,除 id_vars 之外的其他列都被轉換var_name 自定義列名名稱,設定由 'value_vars' 組成的新的 column namevalue_name 自定義列名名稱,設定由 'value_vars' 的資料組成的新的 column namecol_level 如果列是MultiIndex,則使用此級別
df = data.loc[:,['driver_gender',
'driver_race',
'violation']]df

df_pivot = data.pivot_table(index="driver_gender",
columns="driver_race", values="violation", aggfunc= "count")df_pivot

為方便下面轉換的理解,經過去除columns的name後得到:

下面開始進行轉換。保留"driver_gender",對剩下列全部轉換,並給設定對列定義列名。
df_wide.melt(id_vars='driver_gender',var_name = 'driver_race', value_name='violation_count')

上述同樣的結果用groupby也可以做到,如下所示。
df.groupby(['driver_gender','driver_race'] )[['violation']].agg('count').reset_index()

這裡補充說明下去除columns的name及index的name的方法。
如下圖所示"driver_race" 和 "driver_gender" 分別是columns的name,index的name。
下面演示一個平時較為頭疼的事情。即將兩個name刪掉。下面介紹一個常見的方法。
使用pandas.DataFrame.rename_axis去除columns列的名稱
# 第一步,重置索引df_wide = df_pivot.reset_index()# 重置name,設定為None即可df_wide.rename_axis([None], axis=1) # columns有N個,就用N個None
另外一種情況如下圖所示,在column上還有一個"driver_age",此時需要在第一步使用pandas.DataFrame.droplevel把"driver_age"刪除:df.columns = df.columns.droplevel(0)
然後在執行上面兩步。
OK今天的分享就到這裡咯,關注我們持續分享實用乾貨。
相關文章
來源:資料STUDIO作者:雲朵君資料透視表將每一列資料作為輸入,輸出將資料不斷細分成多個維度累計資訊的二維資料表。在實際資料處理過程中,資料透視表使用頻率相對較高,今天雲朵君
2021-06-28 16:14:13

機器之心專欄機器之心編輯部來自浙江大學計算機輔助設計與圖形學國家重點實驗室和杭州相芯科技有限公司的聯合研究團隊提出了自由式材質掃描的可微分框架,並研製了材質外觀掃
2021-06-28 16:14:05

去年先馬的趣造I'm是個很有裝機樂趣的小機箱,它體積相對緊湊,內部又挺能裝,ITX的大小,卻能塞入M-ATX規格主機的硬體配置,不僅相容性較高、可玩性好,還可以控制裝機的成本,所以趣造I
2021-06-28 16:13:19

中科院是國家主力的科技力量,是中國科研的「國家隊」。在中科院手中,誕生了諸多中國乃至全球的前沿科技,有力推動了中國科技發展。在最近幾日裡,中科院接連傳來三大好訊息,給我國
2021-06-28 16:12:53

一、前言:i7-11800H網遊效能到底比銳龍7 5800H強多少呢?在國內遊戲市場,網遊往往比單機遊戲更受關注,玩家群體也更廣泛,因此硬體平臺的網遊效能如何,直接決定了在玩家心目中的口碑
2021-06-28 16:12:04

6月28日,小米舉行了小米電視6畫質雙旗艦見面會,正式釋出小米電視6至尊版和小米電視ES 2022款。作為最受歡迎的小米電視數字系列和ES系列產品,二者著重發力畫質,全面採用分區背光
2021-06-28 15:54:15