來源:資料STUDIO作者:雲朵君01、降維的意義降低無效、錯誤資料對建模的影響,提高建模的準確性。少量切具有代表性的資料將大幅縮減挖掘所需的時間。降低儲存資料的成本。02、需
2021-06-29 10:21:48
來源:資料STUDIO
作者:雲朵君
01、降維的意義
降低無效、錯誤資料對建模的影響,提高建模的準確性。少量切具有代表性的資料將大幅縮減挖掘所需的時間。降低儲存資料的成本。02、需要降維的情況
大多數情況下,面臨高維資料,就要降維處理
維度數量。降維基本前提是高維。建模輸出是否必須保留原始維度。如果需要最終建模輸出是能夠分析、解釋和應用,則只能通過特徵篩選或聚類等方式降維。對模型對計算效率和建模時效性有要求。是否需要保留完整的資料特徵。03、基於特徵選擇的降維
根據一定的規則和經驗,直接選取原有維度的一部分參與後續的計算和建模過程,用選擇的維度代替所有維度。優勢是既能滿足後續資料處理和建模要求,又能保留維度原本的業務含義,以便業務理解和應用。
四種思路
經驗法: 根據業務專家或資料專家的以往經驗、實際資料情況、業務理解程度等進行綜合考慮。
測演算法: 通過不斷測試多種維度選擇參與計算,通過結果來反覆驗證和調整,並最終找到最佳特徵方案。
基於統計分析方法: 通過相關分析不同維度間的線性關係,在相關性高的維度中進行人工去除或篩選
方差過濾:classs sklearn.feature_selection.VarianceThreshold(threshold=0.0) .fit_transform(X,y)卡方過濾:原假設是相互獨立 SelectKBest(chi2,k).fit_transform(X,y)F檢驗:原假設是不存在顯著的線性關係 SelectKBest(f_classif,k).fit_transform(X,y)通過計算不同維度間的互資訊,找到具有較高互資訊的特徵集,然後去除或留下其中一個。SelectKBest(model,k).fit_transform(X,y) 其中 model=multual_info_classif 或 multual_info_regression機器學習演算法: 通過機器學習演算法得到不同特徵的特徵值或權重,選擇權重較大的特徵。
嵌入法:精確度模型本身,是過濾法的進階版。sklearn.feature_selection.SelectFromModel(sklearn.ensemble.RandomForestClassifier(),threshold=0.01).fit_transfrom(X,y)包裝法:sklearn.feature_selection.RFE(sklearn.SVM.SVC(),k).fit_transfrom(X,y)04、基於特徵轉換的降維
按照一定的數學變換方法,把給定的一組相關變數(特徵)通過數學模型將高維空間資料點對映到低維空間中,然後用對映後到變數的特徵來表示原有變數的總體特徵。這種方式是一種產生新維度的過程,轉換後的維度並非原有的維度本體,而是其綜合多個維度轉換或對映後的表示式。
PCA(主成分分析)
PCA (Principal Component Analysis) sklearn.decomposition.PCA(n_components=None,whiten=False)
from sklearn.decomposition import PCApca=PCA().fit()pca.components_ # 返回模型各個特徵向量pca.explained_variance_ratio_ # 返回各自成分的方差百分比
 圖片來源網路
圖片來源網路按照一定的數學變換方法,把給定的一組相關變數(特徵)通過線性變換轉換成另一組不相關的變數,這些新變數按照方差依次遞減的順序排列。方法越大,包含的資訊越多。(無監督式學習,從特徵的協方差角度,去選擇樣本點投影具有最大方差方向)n維可用。
二維轉一維舉例

所謂主成分:選出比原始變數個數少、能夠解釋資料中大部分的變數的幾個新變數,來替換原始變數進行建模。
PCA是將資料投影到方差最大的幾個相互正交的方向上,以期待保留最多的樣本資訊。
PCA演算法1,將原始資料按列組成 行 列矩陣2,將 的每一行(代表一個屬性欄位) 進行標準化處理。3,求出相關係數矩陣4,求出 的特徵值 及對應的特徵向量5,將特徵向量按對應特徵值大小從上到下按行排列成矩陣,取前 行組成矩陣6,,
LDA(線性判別分析)
LDA (Linear Discriminant Analysis)
通過已知類別的「訓練樣本」,來建立判別準則,並通過預測變數來為已知資料進行分類。(有監督式學習,考慮分類標籤資訊,投影后選擇分類效能最好的方向) C-1維(分類標籤數-1)
基本思想是將高維資料的模式樣本投影到最佳鑑別向量空間,已到達抽取分類資訊和壓縮特徵空間維度的效果。投影后保證模式樣本在新子空間的類空間距離和最小的類距離,集模式在該空間中有最佳可分離性。
使樣本儘可能好分的投影方向,就是要使投影后使得同類樣本儘可能近,不同類樣本儘可能遠。
 圖片來源網路
圖片來源網路05、基於特徵組合的降維
將輸入特徵與目標預測變數做擬合的過程,它將輸入特徵經過運算,並得出能對目標變數作出很好解釋(預測性)對複合特徵,這些特徵不是原有對單一特徵,而是經過組合和變換後的新特徵。
優點:提高模型準確率、降低噪聲干擾(魯棒性更強)、增加了對目標變數的解釋性。
方法:
基於單一特徵離散化後的組合。 現將連續性特徵離散化後組合成新的特徵。如RFM模型基於單一特徵的運算後的組合。 對於單一列基於不同條件下獲得的資料記錄做求和、均值等獲得新特徵。基於多個特徵的運算後的組合。 將多個單一特徵做複合計算(包括加減乘除對數等),(一般基於數值型特徵)獲得新特徵。基於模型等特徵最優組合。 基於輸入特徵與目標變數,在特定的優化函數的前提下做模型迭代計算,以到達模型最優的解。如多項式的特徵組合、基於GBDT的特徵組合。GBDT
sklearn.ensemble.GradientBoostingClassifier( ).fit(X,y).apply(X)[:,:,0]
apply()返回的是[n_samples,n_estimators, n_classes]
多項式
sklearn.preprocessing.PolynomialFeatures.fit_transform(X,y).get_feature_names()
Ok,今天的分享就到這裡啦!

相關文章

來源:資料STUDIO作者:雲朵君01、降維的意義降低無效、錯誤資料對建模的影響,提高建模的準確性。少量切具有代表性的資料將大幅縮減挖掘所需的時間。降低儲存資料的成本。02、需
2021-06-29 10:21:48
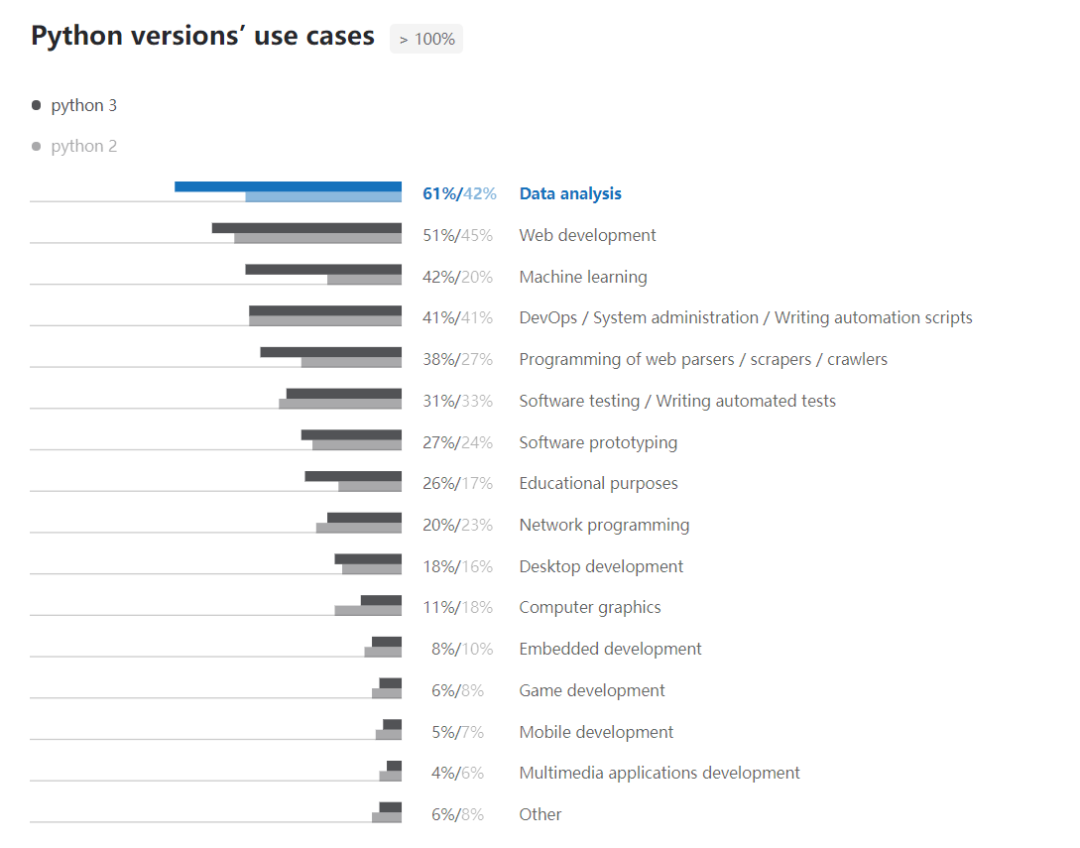
近日,Python 官方釋出了 2019 年 Python 開發者調查結果。該調查由 Python 軟體基金會和 JetBrains 在 2019 年 11 月進行,來自 150 多個國家/地區的 2.4 萬名開發者曾參與其
2021-06-29 10:21:28

大家買 iPhone 的時候,都應該知道 iPhone 有很多版本可以選擇,比如國行版、港版、日版、美版等。仔細對比,你會發現美版 iPhone 的價格的確是比我們最常接觸的國行版 iPhone 便
2021-06-29 10:21:05

眾所周知,如今的使用者需求已經發生了改變,以前的時候,我們都喜歡用小屏設計,大屏手機拿在手機的感覺真的非常差,不僅厚重,還不便於攜帶。但是,當手機市場進入到全面屏時代之後,消費
2021-06-29 10:20:17

研究表明,瑣碎的事務佔用了企業員工完成更有成效的工作的時間。如果做得好,機器人流程自動化(RPA)可以幫助他們消除大量無意義的事務。而企業因此需要為開展更高效的工作選擇
2021-06-29 10:01:49

蘋果公司去年推出的iPhone12系列在引入5G功能之後,吸引了不少消費者的購買;在這之前,所有的iPhone都不支援5G網路,即便是去年上半年推出的iPhone SE 2020,也僅僅是一款4G智慧手機
2021-06-29 10:01:24